


第二篇 -COUNT DISTINCT
SQL 中的去重计数 COUNT DISTINCT 一直比较慢。去重本质上是分组运算,需要把遍历过的分组字段值都保持住,用于后续的比对。结果集太大时,还要把数据写到硬盘上做缓存,性能低下。
如果先将数据按照去重字段排序,计算有序去重就会简单很多,只要在遍历过程中,把与上一条不相同的字段保存下来,并把计数值加 1 即可,不需要保持结果集,更不必做外存缓存。
但数据库无法保证存储的次序,很难实施这样的有序去重算法。esProc SPL 可以把数据导出后有序存储,实现这种高性能的有序去重计数。
以事件表 events 为例,数据是这样的:
event_type 是指操作类型,比如:1 表示 login、2 表示 view、7 表示 confirm 等。
针对事件表的分析计算,一般都是对用户的去重和去重计数。数据外置时,要按照用户号有序存储,可以使用有序去重提高性能。
我们用 ETL 工具定义一个新的 Q2.etl 文件,重复前面的步骤,连接数据库 - 拖拽 events 表 - 编辑:
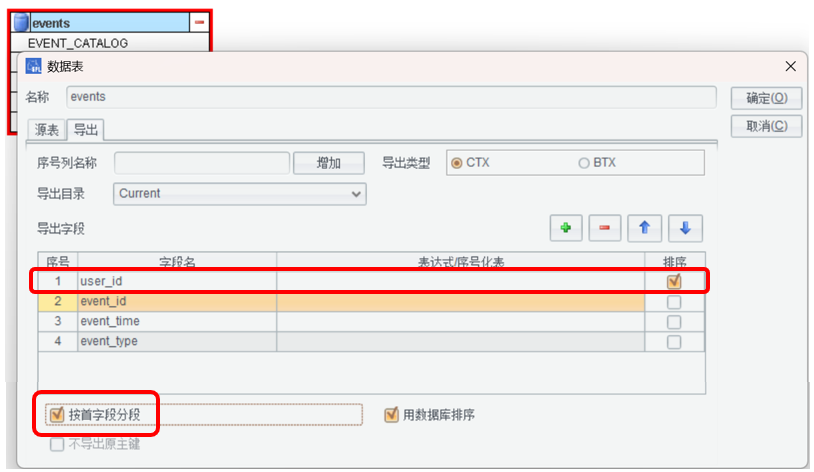
这里按照客户号有序存储,可以使用有序去重提高性能。排序字段必须放在第一个。
user_id 不唯一,要选中“按首字段分窜”选项,表示第一个字段是分段键。
防止分段读取时,把某个 user_id 的记录拆分到两段。SPLX 中 create 会自动加 p 选项。
数据库性能较好时选择“用数据库排序”,不选择就用 SPL 排序。
注意:events 和 MYSQL 系统表重名了,所以有些不需要的字段,在 etl 中删掉,不取出即可。
ETL 工具导出 SPL 代码 9:转储成组表 CTX。
A |
|
1 |
=connect("speed") |
2 |
="d:\\speed\\etl\\" |
3 |
=A1.cursor("SELECT event_id,user_id,event_time,event_type FROM events ORDER BY user_id") |
4 |
=A3.new(user_id,event_id,event_time,event_type) |
5 |
=file(A2+"events.ctx").create@yp(#user_id,event_id,event_time,event_type).append(A4).close() |
6 |
=A1.close() |
A3 的 SQL 中必须有 order by user_id。
A4 中创建组表时,用 #user_id 声明组表是按照这个字段有序的。这里自动加了 p 选项。
用户有序的数据是什么样的呢?我们来直观的看一下。
运行 SPL 代码 10:
A |
|
1 |
=file("events.ctx").open().cursor().fetch(1000) |
IDE 右边可以看到:
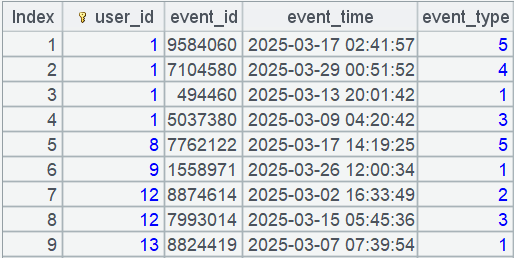
每个用户的数据是连续存放的,读取的时候也是连续的。
每个用户的数据都不多,可以全部读入内存,进行复杂计算。
例 2.1,计算 events 表中有多少不重复的用户。
SQL 语句是这样:
select count(distinct user_id) from events;
执行这个 SQL 需要 7 秒。
SPL 有序去重的方法是这样的:
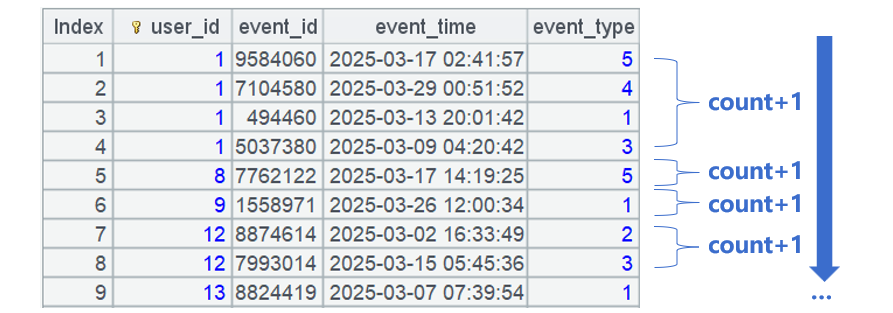
只要合并相邻且相同的用户,就是去重计数了。
而且,只是计数不做分组汇总的话,可以不建立按照 user_id 分组的子集,性能更好。
SPL 代码 11:
A |
|
1 |
=now() |
2 |
=file("events.ctx").open().cursor@m(user_id).group@1(user_id).skip() |
3 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
A2 中游标的 group 函数就是采用有序分组方式,归并相邻且相同的 user_id。
group函数的@1 选项表示每组只取第一条记录,这样就不用建立分组子集了。
这个计算方法,执行时间是 0.1 秒。
例 2.2,出现过 login 或 confirm 的去重 user_id 个数。
event_type 为 1 的,代表 login。event_type 为 7 的,代表 confirm。
SQL 是这样:
select
count(distinct case when event_type = 1 then user_id end) as count1,
count(distinct case when event_type = 7 then user_id end) as count2
from events;
执行时间是 5 秒。
SPL 代码 12:
A |
|
1 |
=now() |
2 |
=file("events.ctx").open().cursor@m(user_id,event_type) |
3 |
=A2.groups(;icount@o(if(event_type==1,user_id)):count1,icount@o(if(event_type==7,user_id)):count2) |
4 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
icount 是去重计数,加 @o 选项就是有序去重计数,也是只合并相邻且相同的值。
if(event_type==1,user_id)):count1,条件成立,得到 user_id,不成立得到 null。
icount 函数会忽略 null,比如:[1,null,1,2,3].icount@o(),结果是 3。
执行时间是 0.15 秒。
例 2.3,去掉重复事件后,发生事件个数大于 5 的用户数量。
同一用户,按照时间顺序连续的事件如果 event_type 相同就是重复事件。比如:用户 31 的一个事件类型是 7,随后发生的事件也是 7 就是重复事件:
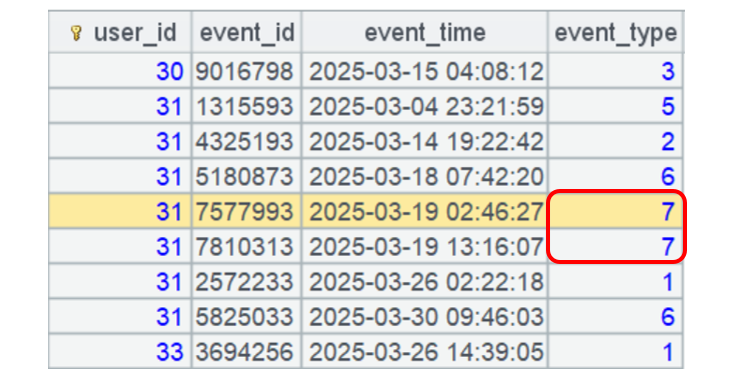
这一题,SQL 比较难写了,这里不再给出,有兴趣的同学可以尝试写一下。
SPL 代码 13:
A |
|
1 |
=now() |
2 |
=file("events.ctx").open().cursor@m(user_id,event_type,event_time).group(user_id) |
3 |
=A2.select(~.sort(event_time).group@o1(event_type).len()>5).skip() |
4 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
执行时间是 0.5 秒。
A2 中游标的 group 函数,不带任何选项,默认是建立分组子集的,A3 中的 ~ 就表示当前分组子集。
重点看 A3,每组 user_id 数据量不大,可以全组读入内存形成序表 ~,比如这一组:
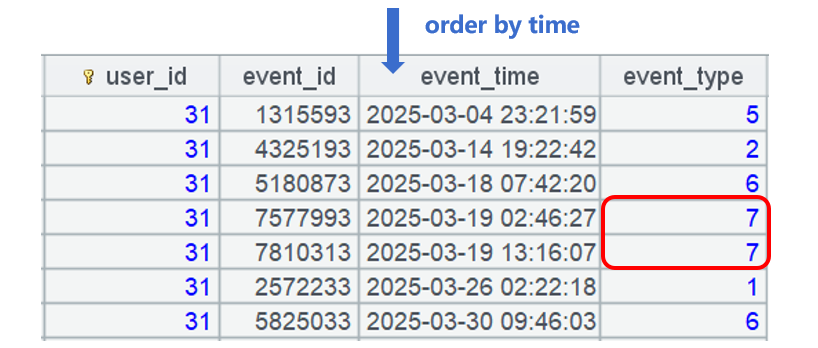
~.sort(event_time) 对序表 ~ 按照时间排序后,相邻且相同的 event_type 就是重复数据。再对这个序表继续计算分组 group@o1,归并相邻且相同的 event_type,就去掉了重复。
小结一下性能(单位 - 秒):
MYSQL |
SPL |
|
例 2.1 |
7 |
0.1 |
例 2.2 |
5 |
0.15 |
例 2.3 |
实现困难 |
0.5 |
请动手练习一下:
1、计算没有出现过 login 或 confirm 的去重 user_id 个数。
2、思考:是否遇到过去重或者去重计数比较慢的情况?是否可以用有序去重来提速?

