


13. 用正则表达式分析文本
文件 RegisterSiteA.csv 中存储了某次考试的报名信息,数据量比较大。(1)找到报名人员中哪些人填写了中间名,并列出他们的中间名。(2)找到姓(Last Name)以 B 开头的前 100 个人的报名信息。
参考答案:
解答:
| A | |
|---|---|
| 1 | =file(“RegisterSiteA.csv”).cursor@ct(ID,NAME,REGTIME) |
| 2 | .* (.*) .* |
| 3 | =A1.derive(NAME.regex(A2)(1):MidName) |
| 4 | =A3.select(MidName).fetch() |
| 5 | =file(“RegisterSiteA.csv”).cursor@ct(ID,NAME,REGTIME) |
| 6 | =A5.select(left(NAME.words().m(-1),1)==“B”) |
| 7 | =A5.fetch@x(100) |
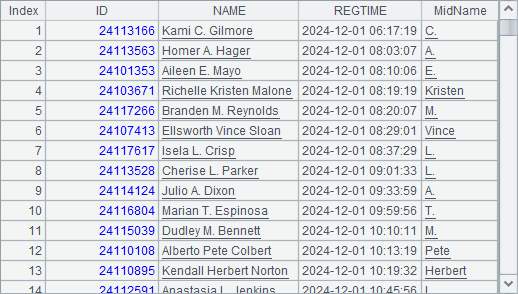
A1 用文件中所需的字段创建游标,A2 设置正则表达式,其中. 表示任意字符,而如果名字中包含中间名,则其中会包含两个空格,把两个空格中间的字符用小括号括起来表示提取出来。在 A3 中,使用正则表达式函数 regex 处理 NAME 字符串,提取其中的中间名作为新生成的 MidName 字段。在 A4 中,先从游标中筛选出 MidName 不为空的字段,并用 fetch 获取结果。
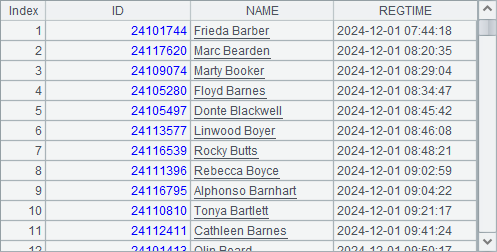
A5 新建游标,这里不能用 A1.reset()后继续使用,因为游标中已经包含了添加列和过滤的操作。A6 中筛选出姓以 B 开头的报名者,为此,用 s.words() 函数将字符串按单词拆开,此时用 A.m(-1) 即可获取最后一个单词,即姓,用 left(s,n) 函数取出第一个字母,判断它是否为 B。A7 中即可按所需的条数获取结果。这里也可以用正则表达式来解决,如将 A6 中代码改为 =A5.select(NAME.regex(“.* (B)[A-Za-z]*$”)(1)),正则表达式中,[A-Za-z] 表示任意英文字母,$ 表示字符串结尾。


英文版