


6. 降水量计算
使用文本数据 meteorolog.txt 存储的气象数据,根据每日平均气温 TEMP, 最大风速 MXSPD 和降水量 PRCP,(1)列出每个观测站的首次降水量。(2)哪些观测站缺失了降水量数据,哪些观测站出现了至少连续 6 日的降水。(3)统计每个观测站中,若某日降温超过 2 度时,次日下雨 / 雪的天数和概率; 以及某日降温超过 2 度时,次日平均风速大于该地区全年平均风速的天数和概率。
参考答案:
解答:
| A | |
|---|---|
| 1 | =T(“meteorolog.txt”,STATION,DATE,TEMP,PRCP,WDSP) |
| 2 | =A1.derive(TEMPDiff,RainTomorrow,WindyTomorrow) |
| 3 | =A2.group(STATION) |
| 4 | =A3.new(STATION,~.ifn(PRCP):FirstPRCP) |
| 5 | =A3.select(!~.(PRCP).cor()).(STATION) |
| 6 | =A3.select(~.(PRCP[0,5].cand()).cor()).(STATION) |
| 7 | >A3.(avgWDSP=~.avg(WDSP), ~.run(TEMPDiff=if(#==1,0.0, round(TEMP-TEMP[-1],1)), RainTomorrow=PRCP[1]>0, WindyTomorrow=WDSP[1]>avgWDSP)) |
| 8 | =A3.(~.select(TEMPDiff<-2)) |
| 9 | =A8.new(STATION, ~.count():CoolingDays, ~.count(RainTomorrow):RainyDays, round(RainyDays/CoolingDays,4):RainyRate, ~.count(WindyTomorrow):WindyDays, round(WindyDays/CoolingDays,4):WindyDays) |
A1 从文本文件中读取序表,这里仅取出需要使用的字段,也可以改为 =file(“meteorolog.txt”).import@t(STATION,DATE,TEMP,PRCP,WDSP),效果是相同的。A2 中添加了 TEMPDiff,RainTomorrow 和 WindyTomorrow3 个新字段,准备用来存储每日与前一天的温差,以及次日是否有雨雪或大风。A3 中将 A2 中添加记录后的序表,按观测站分组。
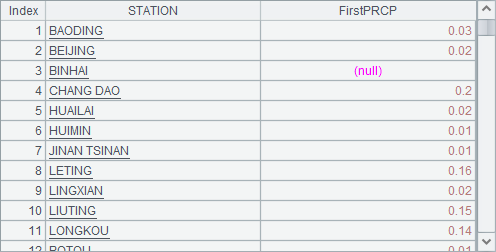
A4 用 A.new()函数,生成各个观测站首次降水的数据,降水数据中无降水时是 null,因此只需要用 A.ifn(x) 即可查出到首次降水数据。
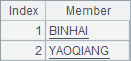
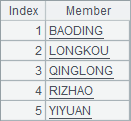
A5 用 A.cor(x),判断是否存在降水数据,前面加了! 则可筛选出全年均无降水数据的站点。A6 用 [a,b] 跨行计算区间,配合 A.cand()计算是否连续 6 天均有降水,再用 A.cor()选出全年中曾经出现过连续 6 天降水的站点。
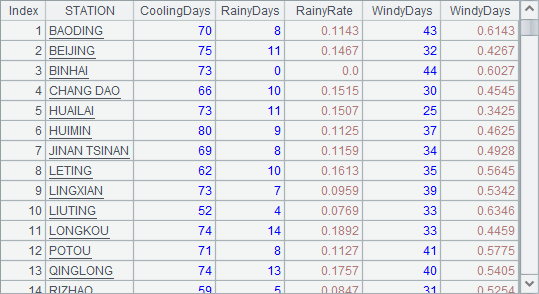
在 A7 中,循环每个观测站的数据来计算,计算时使用了逗号运算符 x1,x2,…xn,它在计算时会依次计算或执行每个表达式,并只返回最后一个表达式的计算结果,这里在每个观测站的数据中先计算出全年平均风速,并存入变量 avgWDSP 以用于后续计算,后面用 A.run()函数依次为新字段赋值,用 [] 可以在当前分组的序列中实现跨行计算,如前一天气温为 TEMP[-1],后一天降水为 PRCP[1]等,而第 1 天的温差设为 0。赋值完成后,A7 中结果如下:
可以查看其中某个分组的数据,如 HUAILAI 观测站的数据如下:
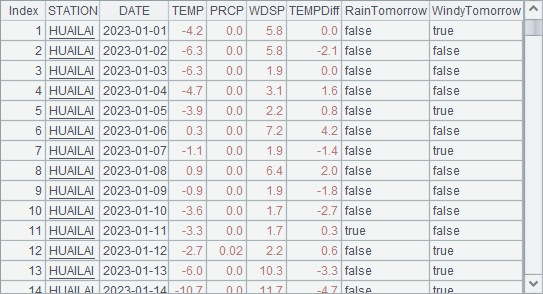
A8 在各个观测站分组中选取降温超过 2 度的数据,准备用来完成计算,A8 中的结果是排列构成的序列,其中排列是指由序表记录构成的序列。A9 用 A.new() 函数,生成结果序表,其中计算概率时用 round 函数保留 4 位小数。


英文版