


数据分析编程从 SQL 到 SPL:断货
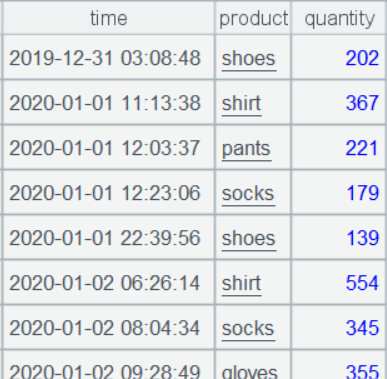
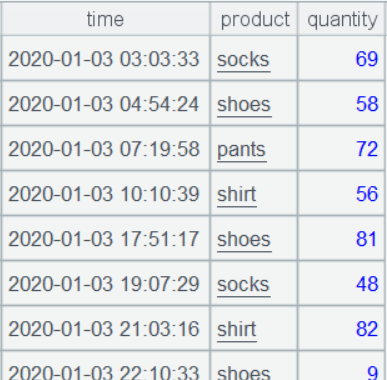
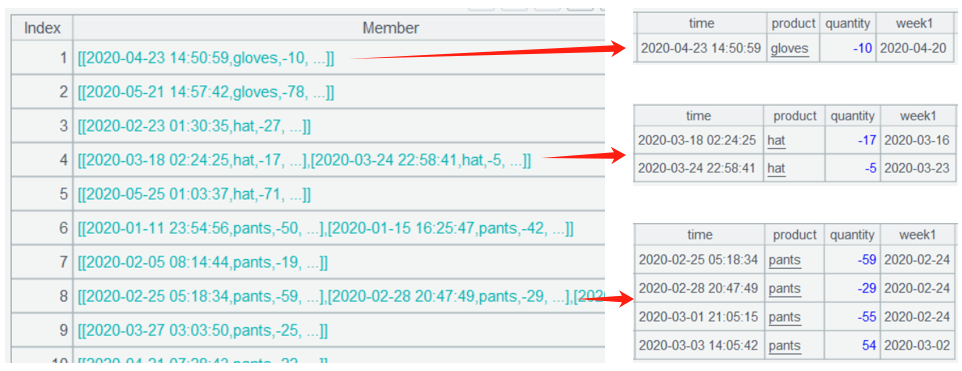
简化后的进货表 purchases、销售表 sales 的部分数据如下:
sales:
purchases:
1、统计各产品多少周发生过断货
这里只统计断货点所在周,多周持续断货时后面的周不再统计。
进货理解为增加,销售理解为减少,所以把销售数量变为负数,然后两表合并起来,按产品、时间排序后,进货、销售数量就混合在一起了,然后按顺序做累加,为 0 时即发生断货,遇到新产品时重新累计;一种产品在一周内可能出现多次断货,直接对断货时间点计数就可能重复,可以统一成断货时间点所在周的周一,再去重计数。
先看 SQL:
with t1 as (
select time,product,-quantity quantity from sales
union all
select * from purchases
),
t2 as (
select *,
sum(quantity) over(partition by product order by time) cum
from t1
)
select product, count(distinct date_sub(date(time), interval weekday(time) day)) cnt
from t2
where cum=0
group by product;
先用一个子查询合并两表;
SQL 集合无序,后面累加计算时无法利用子查询的有序性。分组,组内排序、累加这些操作要绑定在一个窗口函数内实现,会出现第二个子查询;
SPL 集合有序,多步计算时,会保持有序性供下一步利用,cum()函数能对有序集合做分组累计,直接用于过滤断货记录的条件中;pdate() 函数能获得各种特殊日期,包括这里用到的周一。
A |
|
1 |
=file("purchases.txt").import@t() |
2 |
=file("sales.txt").import@t().run(quantity=-quantity) |
3 |
=(A1|A2).sort(product, time) |
4 |
=A3.select(cum(quantity;product)==0) |
5 |
=A4.groups(product;icount(pdate@w1(time)):cnt) |
A1 加载 purchases 数据;A2 加载 sales 数据并把销售数量变为负数;
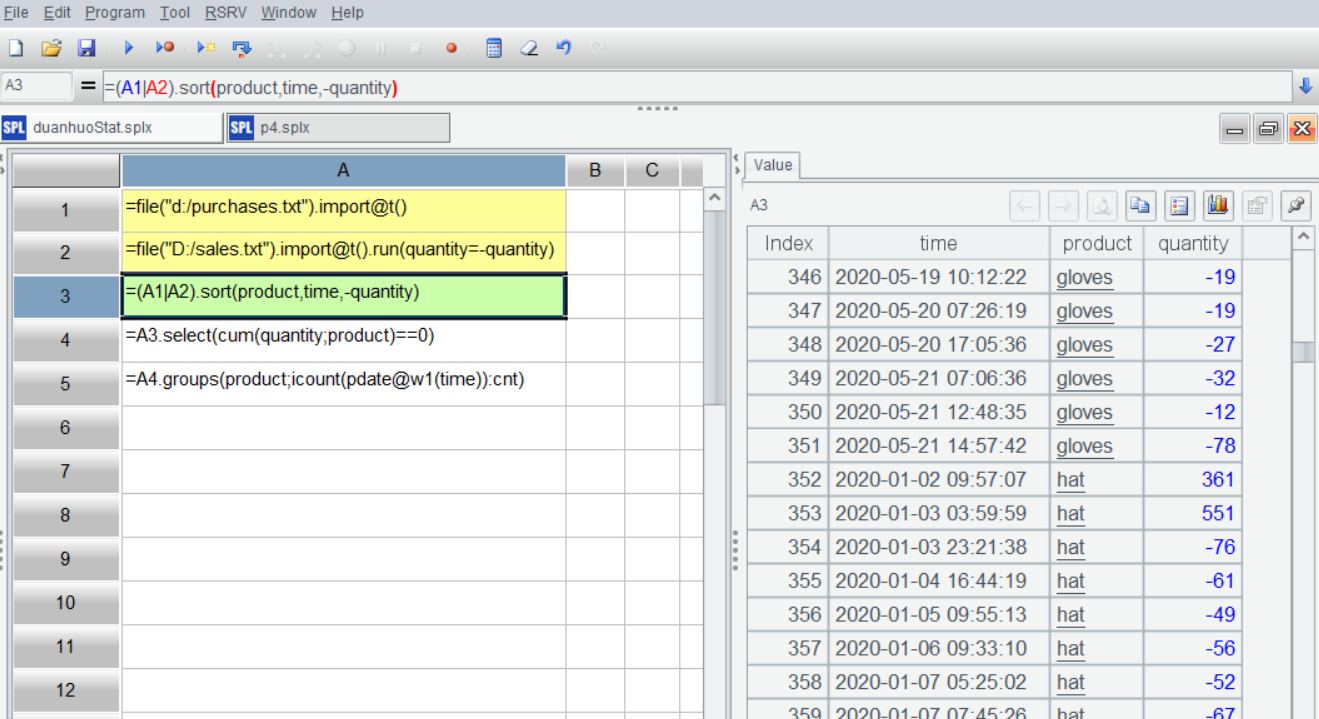
SPL IDE 有很好的交互性,可以单步执行并随时在右边的面板中直观地查看到每一步的结果,A3 中用 | 把两表合并起来之后,按产品、时间排序,选中 A3,右侧展示它的结果数据:
A4 过滤出各产品累加为 0 的断货记录;
A5 按产品统计周一数量时,icount() 函数为去重计数。
熟悉SPL后,计算步骤可以简单地写成一句:
A |
|
1 |
=file("purchases.txt").import@t() |
2 |
=file("sales.txt").import@t().run(quantity=-quantity) |
3 |
=(A1|A2).sort(product, time) |
2、统计出各产品断货周的时间段
按照上题方法找到每个产品所有断货周的周一日期,把这些日期排序,按连续的周 (间隔 0 天或 7 天的周一) 分组,第一周周一到最后一周周日就是这组连续断货周的时间段。
SQL:
with recursive t1 as (
select time,product,-quantity quantity from sales
union all
select * from purchases
),
t2 as (
select *, sum(quantity) over(partition by product order by time) cum
from t1
),
t3 as (
select product, date_sub(date(time), interval weekday(time) day) week1
from t2
where cum=0
),
t4 as (
select *, row_number() over(partition by product order by week1) rn
from t3
),
t5 as (
select product, min(week1) start, min(week1) week1, rn
from t4
group by product
union all
select h.product, (case when datediff(h.week1,q.week1)>7 then h.week1 else q.start end), h.week1, h.rn
from t4 h join t5 q
on h.product=q.product and h.rn=q.rn+1
)
select product, concat(start, ',', max(week1)+interval 6 day) segment
from t5
group by product,start
order by product,start;
SQL 集合无序,不支持按位置取数,和上一个对比时,要先用子查询 t4 标记上次序号 rn,t5 中 t4 自关联后用条件 h.rn=q.rn+1 表达相邻两条,而且存在多条连续对比,还要指定用递归子查询,本来只是对比前后两个日期的周是否连续,改成标序号并且递归做关联的思路实在太绕。
SPL 的有序集合能按位置引用数据,容易对比是否为连续周;除了最常见的等值分组,还支持条件分组,能完全按照自然思路编写代码:
A |
|
1 |
=file("purchases.txt").import@t() |
2 |
=file("sales.txt").import@t().run(quantity=-quantity) |
3 |
=(A1|A2).sort(product, time) |
4 |
=A3.select(cum(quantity;product)==0).derive(pdate@w1(time):week1) |
5 |
=A4.group@i(product!=product[-1] || week1- week1 [-1]>7) |
6 |
=A5.new(product, ~1.week1/","/(~.m(-1).week1+6):segment) |
A4 算出每个断货周的周一,并且保持着 A3 集合的有序性:
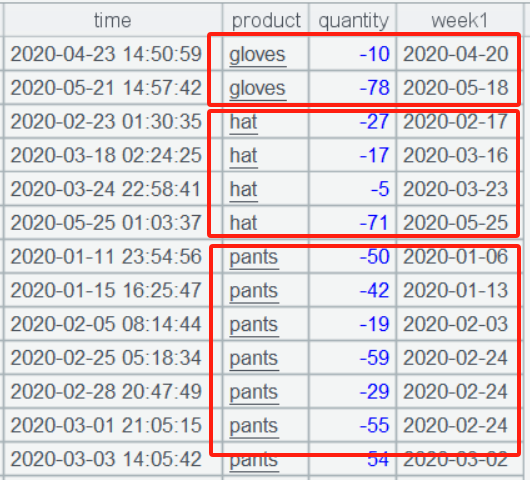
A5 中的 group()函数用 @i 选项表达按条件分组,条件表达式为 true 时,就会产生新组,product[-1] 表示上一条的产品,week1 [-1] 表示上一条的周一日期,用它们和本条产品、日期对比是否连续;分组结果是个二层集合:
A6 直接从各个连续周分组子集获得时间段首尾日期,~ 是当前分组子集,~.m(1) 是第一条记录,~.m(1).week1 是第一个周一,~.m(-1) 是最后一条记录,~.m(-1).week1+6 是最后一个周一加 6,也就是该时间段的结尾:
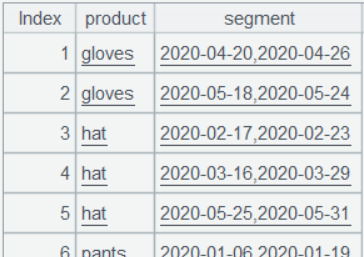
3、统计各产品断货周的时间段及周均销量
对合并的进货、销售明细记录累加数量的同时,算出它们所在周的周一日期,然后按产品、周一日期分组,选出存在断货的组 (累计为 0),然后再汇总出这些断货周的总销量,之后计算逻辑就与上题一样了,按连续的断货周分组,算出时间段以及周均销量 (多个断货周总销量 / 周个数)。
SQL:
with recursive t1 as (
select time,product,-quantity quantity from sales
union all
select * from purchases
),
t2 as (
select *, sum(quantity) over(partition by product order by time) cum
from t1
),
t3 as (
select product, date_sub(date(time), interval weekday(time) day) week1
from t2
where cum=0
group by 1, 2
),
t4 as (
select *, row_number() over(partition by product order by week1) rn
from t3
),
t5 as (
select product, min(week1) start, min(week1) week1, rn
from t4
group by product
union all
select h.product, (case when datediff(h.week1,q.week1)>7 then h.week1 else q.start end), h.week1, h.rn
from t4 h join t5 q
on h.product=q.product and h.rn=q.rn+1
),
t6 as (
select product, start, max(week1)+interval 6 day end
from t5
group by product,start
),
t7 as (
select product
,date_sub(date(time), interval weekday(time) day) week1
,sum(quantity) quantity
from sales
group by 1,2
)
select t6.product, concat(start,',',end) segment, avg(t7.quantity) avg
from t6 join t7
on t6.product=t7.product and t7.week1 between t6.start and t6.end
group by 1,2
order by 1,2;
SQL 每一次单独的 (子) 查询运算,都是针对全集数据的,很难针对计算过程中的分组子集再定义复杂、复合运算,所以计算断货周时间段和计算每周的总销量,要分别针对全集数据去运算,最后再把两个运算结果关联起来。
SQL 可以做纯粹的分组,得到的分组子集中仍然是明细数据,针对每组再定义多复杂的运算都方便,编写脚本时按照自然思路逐步写就行,不用费脑的去想替代方案:
A |
|
1 |
=file("purchases.txt").import@t() |
2 |
=file("sales.txt").import@t().run(quantity=-quantity) |
3 |
=(A1|A2).sort(product,time).derive(cum(quantity;product):cum,pdate@w1(time):week1) |
4 |
=A3.group(product,week1).select(~.pselect(cum==0)) |
5 |
=A4.new(product,week1,-~.sum(if(quantity<0, quantity)):quantity) |
6 |
=A5.group@i(product!=product[-1] || week1-week1[-1]>7) |
7 |
=A6.new(product, week1/","/(~.m(-1).week1+6):segment, ~.avg(quantity):avg) |
A3 合并进货、销售记录,按数量排序,然后算出累加数量 cum 和周一日期 week1;
A4 按产品、周一日期分组后,用 pselect 找出出现过断货的周;
A5 汇总出断货周的总销量;
A6 按条件分组,把连续的断货周分到一组内;
A7 算出时间段起止日期的同时,还汇总出周均销量。


英文版