


这可能是最轻量级的逻辑数仓替代技术
现代数据分析业务(如常见的报表应用)经常要从不同系统中提取数据,这些数据分散在各个地方,格式和存储形式也不一样,更新速度也不统一。CRM 里的销售数据、财务系统里的财务数据,ERP 里的库存数据,甚至有一些外部数据存储在云端。这些数据源就像是拼图的不同块,形状不一样,信息也不同,如何整合这些数据源进行数据分析是一项不断挑战效率和灵活性的难题。
逻辑数仓 OK,但是…
逻辑数据仓库是融合多数据源的一种常见方式。逻辑数仓可将来自不同来源的数据汇总到一个统一的“虚拟”数据平台上,通过统一的视图快速进行数据查询和报表分析。这样的透明性可以屏蔽底层数据源的差异,无论何种数据源,都可以采用统一方式进行查询分析。而且即使以后数据源变化,应用改动也很小甚至可能不用改,这是透明性的又一重要表现。同时,逻辑数仓没有传统数仓因为数据加工和同步的延迟,数据实时性更高。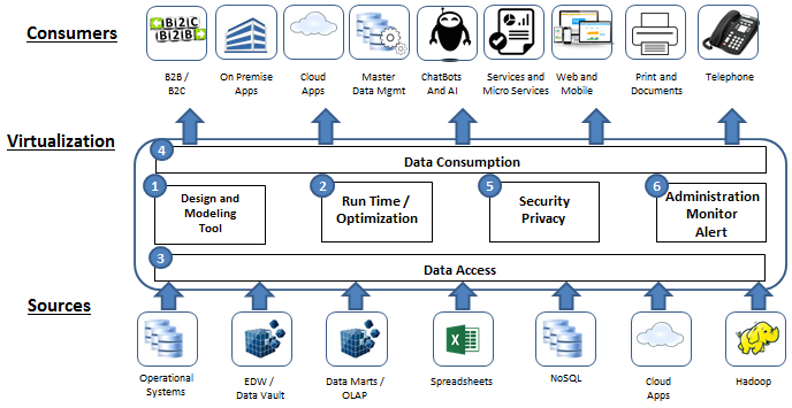
但是,逻辑数仓太沉重了。目前主流的逻辑数仓都采用集群体系,通常节点还不少,资源消耗很高。而且,逻辑数仓的配置也很复杂,搭建就不容易,想运行丝滑还要付出很大的运维成本,整体表现就很重。逻辑数仓的复杂度会远远超过某个应用本身,应用于大机构的数据平台还较为合理,但如果仅仅为诸如报表的某个应用而搭建逻辑数仓就有点得不偿失了。
SPL 轻量级解决方案
如果你觉得用这么沉重的逻辑数据仓库仅仅处理一个多数据源混合计算的问题有点不划算,那一定得了解一下 esProc SPL。它就像给分析系统加上了轻盈的翅膀,不仅避免了繁琐的架构和高昂的维护成本,还能快速响应、灵活调整。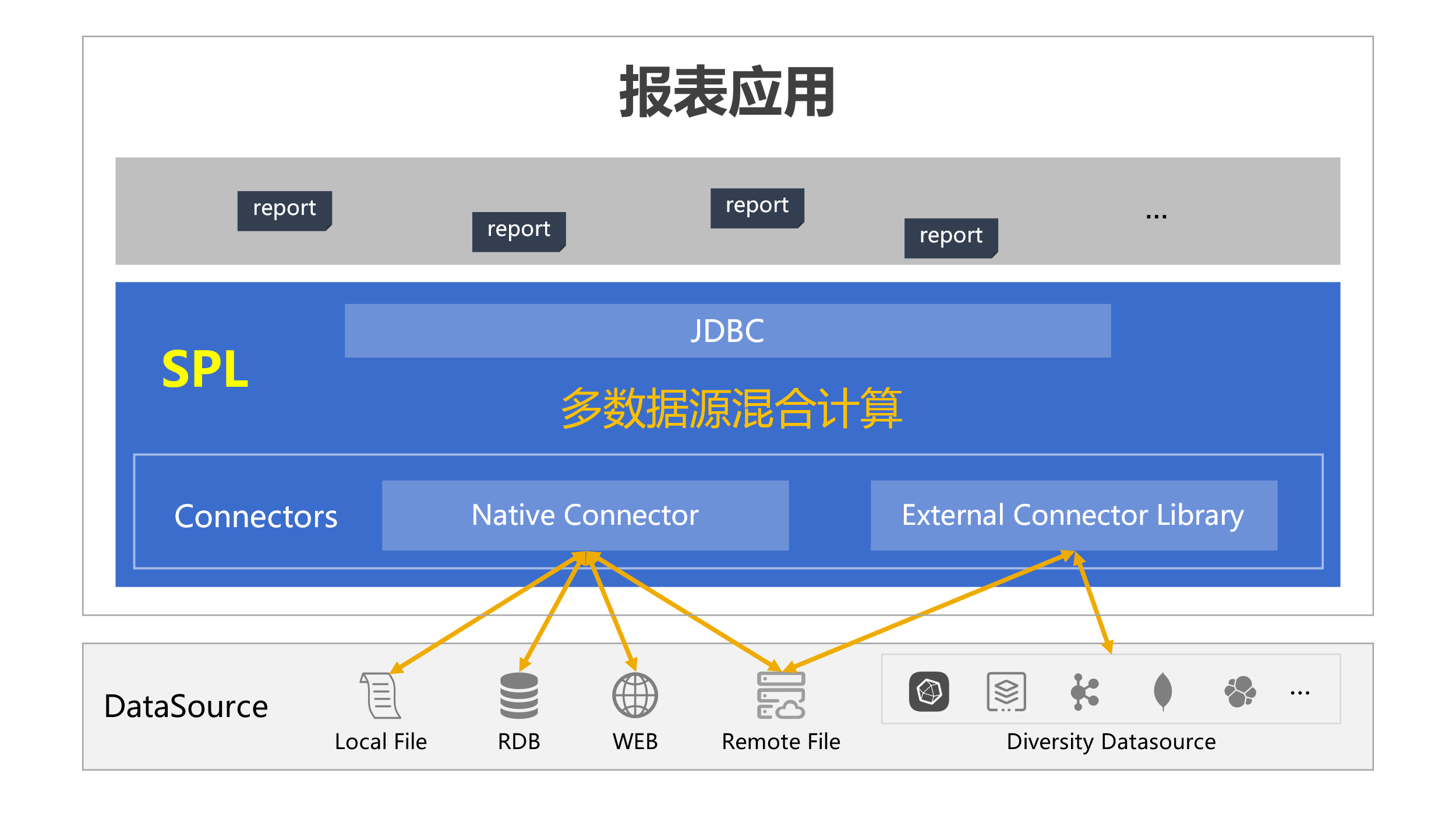
SPL 提供了序表和游标两种核心的数据对象,无论何种数据源、无论数据量大小,都使用这两种数据对象进行计算,不需要事先定义复杂的元数据映射,简化数据接入过程,天然支持混合计算。
更重要的是,与逻辑数仓相比,SPL 非常轻,避免了复杂的虚拟化过程,不需要重型数据库系统的支持。只需要将 JAR 包嵌入应用就能使用,尤其适合报表应用,然后通过脚本直接处理多源数据。因为可以随应用部署,也不需要额外的集群环境,可以节省大量的硬件资源,使用和运维也更简单。
SPL 的轻量还表现在配置和使用上。与应用集成时将 SPL 的两个 JAR 包引入到应用中,然后复制核心配置文件即可,不需要复杂的配置操作。
使用时,由于封装了标准 JDBC 接口,报表通过配置 SPL 的 JDBC 数据源后就能访问 SPL。
比如要针对 MongoDB 和 MySQL 进行混合计算:
准备 SPL 脚本(orderAmount.splx):
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date >= CURDATE()- INTERVAL 1 MONTH") |
3 |
=mongo_open("mongodb://127.0.0.1:27017/raqdb") |
4 |
=mongo_shell@d(A3, "{'find':'products', 'filter': { 'category': {'$in': ['Tablets', 'Wearables', 'Audio'] } }}” ) |
5 |
=A2.join@i(product_id,A4:product_id,name,brand,category,attributes) |
6 |
=A5.groups(category;sum(price*quantity):amount) |
7 |
return A6 |
最后在应用中像调用存储过程一样调用这个脚本就可以了:
call orderAmount()
整个过程不需要系统搭建,也没有复杂的配置要求,简单几步就能实现报表多源混合计算。
更详细的集成和使用可以参考 SPL 实践专题: SPL 报表开发:不依赖逻辑数仓的轻量级多数据源报表
SPL 支持多种数据源,包括关系型数据库(SQL)、非关系型数据库(NoSQL)、Webservice、JSON、文件系统等等。不同类型的数据源都能轻松接入,不需要将所有数据强行转换为统一格式。
SPL 支持的部分数据源
同时,SPL 也提供了扩展接口,用户可以根据需要扩展数据源种类。
与逻辑数仓几乎完全透明化有所不同,SPL 脚本对数据源并不透明,在数据源变化时需要随之修改。主要原因在于 SPL 基于不同数据源的取数方式(接口)不同,这样设计的初衷是为了充分利用数据源自身的优势。比如上面的脚本中,先借助 SQL 和 MongoDB Shell 命令进行了数据过滤和关联运算,发挥数据源自身优势的同时,数据实时性也更高。
由于 SPL 具备完整的计算能力,数据源变化也只需要修改取数逻辑,主要的计算逻辑仍然无需修改,基于 SPL 开发的应用也不用改动,可以做到相当程度的透明化。
数据源变化只需要修改 SPL 的取数逻辑
总体来说,SPL 提供了一种简单、轻量的解决方案,可以完美应对多数据源计算的挑战。加之语法简洁、交互方便等因素,SPL 足可以成为多数据源计算场景,尤其是报表应用的标配。


英文版