


数据分析编程从 SQL 到 SPL:就诊记录分析
数据结构
就诊记录表 Appointments
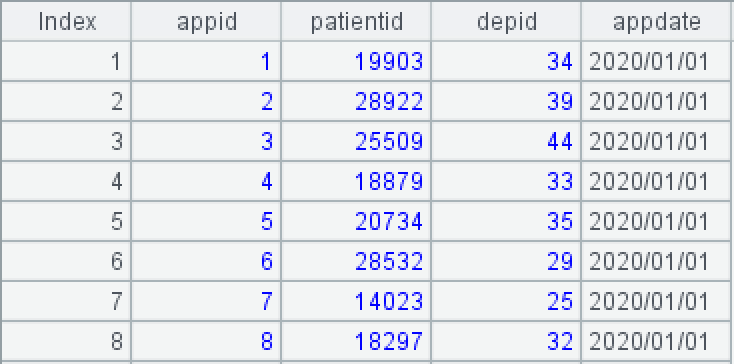
appid 是就诊编号,patientid 是患者编号,depid 是科室编号,appdate 是就诊日期。
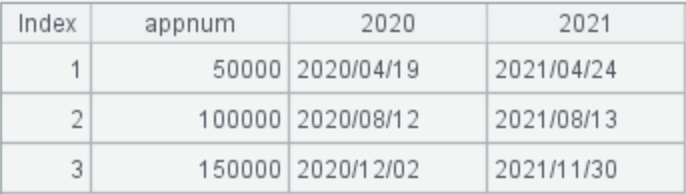
1. 查询 2020 与 2021 年就诊量分别达到 50000 的倍数的时间
期待的目标结果如下图所示:
SQL 语句如下:
with t1 as (
select appid,patientid,depid,appdate,
row_number() over(partition by year(appdate) order by appdate) rn
from appointments
where appdate between '2020-01-01' and '2021-12-31'
),
t2 as (
select rn appnum,
max(if(year(appdate)=2020,appdate,null)) `2020`,
max(if(year(appdate)=2021,appdate,null)) `2021`
from t1
where rn%50000=0
group by rn
)
select * from t2;
SQL 语句在使用了窗口函数后仍要嵌套多层,比较繁琐。主要是因为 SQL 的结果集是无序的,要增加隐晦的标记来实现有序运算。
这个问题其实很简单,将就诊记录表按照年份分组,每组内选出 50000 的整数倍的所有记录,再构造出需要的目标结构即可。
SPL 中的集合都是有序集合,可以直接用序号访问成员记录,更方便实现有序运算。SPL 脚本如下:
A |
|
1 |
=T("appointments.txt").select([2020,2021].contain(year(appdate))) |
2 |
=A1.sort(appdate).group@o(year(appdate)).(~.select(#%50000==0)) |
3 |
=A2.max(~.len()).new(#*50000:appnum,A2(1).m(#).appdate:'2020', A2(2).m(#).appdate:'2021') |
A1: 读取就诊记录表,选出 2020 年和 2021 年的记录。
SPL 的 IDE 有很好的交互性,可以执行后在右边的值面板中直观地查看到每一步的结果:
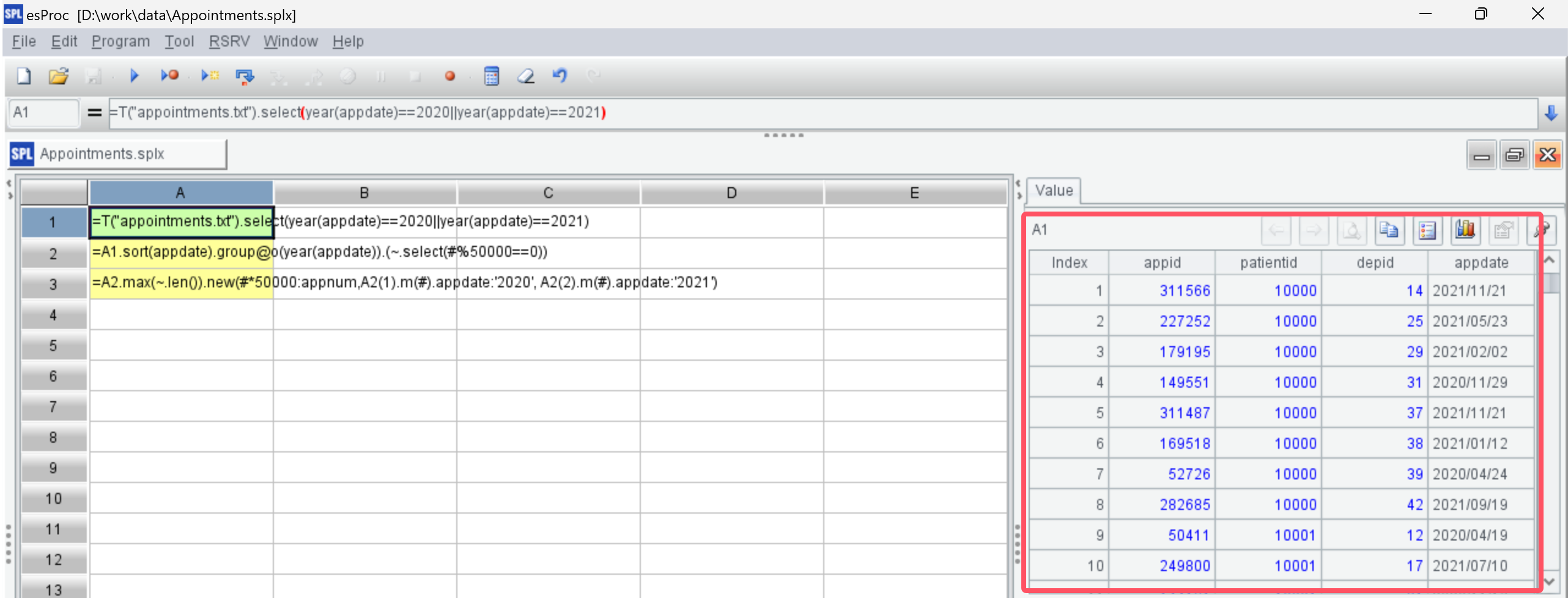
A2: 根据就诊日期排序后按年份分组,每组取位置能被 50000 整除的记录。
使用了函数 group 的选项 @o 进行有序分组,当就诊日期的年份发生变化时产生新组:

点击进去可以看到记录按年份分成了两组,每组的成员是所有年份相同的记录:
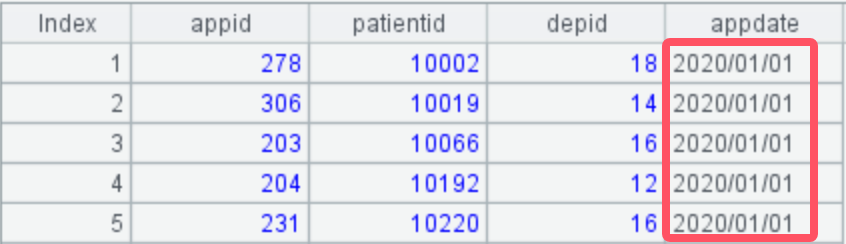
A3: 按最长组的长度添加记录,生成需要的目标结构:
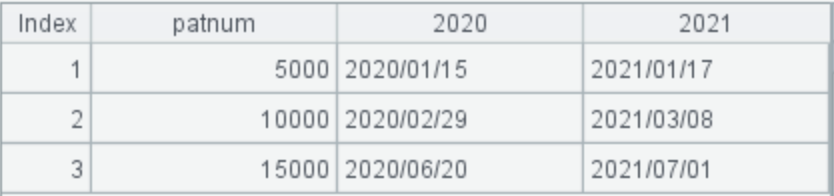
2. 查询 2020 与 2021 年就诊人数分别达到 5000 倍数时的时间
如果病人年度有多次就诊记录,只计年度第 1 次。期待的目标结果如下:
SQL 语句如下:
with t1 as (
select appid,patientid,depid,appdate,
row_number() over(partition by year(appdate),
patientid order by appdate) rn
from appointments
where appdate between '2020-01-01' and '2021-12-31'
),
t2 as (
select *
from t1
where rn=1
),
t3 as (
select *,
row_number() over(partition by year(appdate) order by appdate) rn2
from t2
),
t4 as (
select rn2 patnum,
max(if(year(appdate)=2020,appdate,null)) `2020`,
max(if(year(appdate)=2021,appdate,null)) `2021`
from t3
where rn2%5000=0
group by rn2
)
select * from t4;
虽然只是增加了一步选出病人第一次就诊记录,但是 SQL 语言的复杂程度却增加了很多。
对于 SPL,还是按自然逻辑,只要在问题 1 的基础上选出病人第一次就诊记录即可:
A |
|
1 |
=T("appointments.txt").select([2020,2021].contain(year(appdate))) |
2 |
=A1.sort(appdate).group@o(year(appdate)) |
3 |
=A2.(~.group@u1(patientid).select(#%5000==0).new(#*5000:patnum,year(appdate):year,appdate)).conj() |
4 |
=A3.pivot(patnum;year,appdate) |
A3: 每年里取病人第一次就诊记录,然后取位置能被 5000 整除的记录。函数 group 的选项 @1 在分组时每组只取第一个,选项 @u 在分组时保持原序。
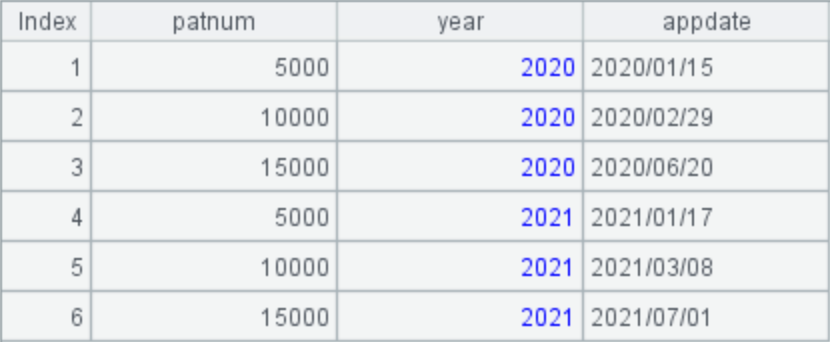
A4: 把年份转置到列上:
这个 SPL 脚本相比问题 1 并没有复杂很多,SPL 支持分步运算,只需要增加一步选出病人第一次就诊记录。
3. 统计每年续诊超 8 次的人数
同一科室续诊的计算规则为:忽略不到 12 天的再次就诊,12 天到 18 天内的再次就诊才算续诊。
SQL 对于分组后的有序循环计算不能很好的描述,这里就不再给出 SQL 的解决方案了。
SPL 解决这个问题仍不复杂,只要按照自然逻辑,将就诊记录按照年份、科室、患者编号进行分组,然后在组内循环计算续诊次数,最后选出所有续诊次数大于 8 患者数量:
A |
|
1 |
=T("appointments.txt").sort(appdate) |
2 |
=A1.group(year(appdate):year,depid,patientid;~.sum(if(#==1 || appdate-a>18:(a=appdate,0),appdate-a<12:0;(a=appdate,1))):num) |
3 |
=A2.select(num>8) |
4 |
=A3.groups(year;icount(patientid):count) |
A2: 计算每年各科室每个病人的续诊次数。使用函数 group 按照年份、科室和病人分组,每组的成员是病人在某年某科室的所有就诊记录。然后对每组记录进行求和计算续诊次数,这里使用了函数 if 进行多重判断:第一次就诊或就诊日期超过 18 天时定义变量 a 值为当前就诊日期,续诊数加 0;就诊日期小于 12 天则续诊数为 0;这些条件都不满足的就是续诊记录,设置 a 为当前就诊日期,续诊数加 1。
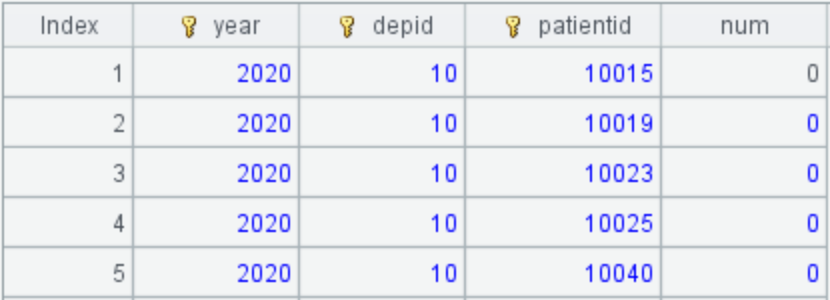
A4: 统计每年续诊超 8 次的病人数:
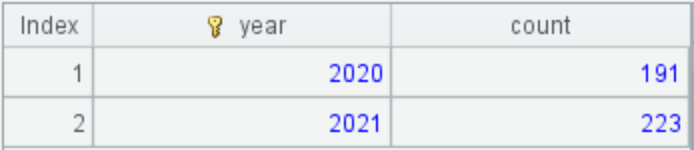
这个 SPL 脚本相比前两个例子并没有复杂很多,这主要得益于 SPL 支持独立的分组运算,在分组后保留了分组子集,可以继续使用分组子集进行一些复杂的计算,而不局限于 SUM、COUNT 等 SQL 中常见的聚合运算。
4. 统计每年续诊超 8 次的人数排前 5 的科室
与上个问题相比,在算出续诊超 8 次的患者后,需要按科室统计续诊人数并取前五名。SPL 解决这个问题时,可以直接复制上个脚本的 A1:A3 部分,再按年份分组选出续诊人数排名前五的科室即可。
A |
|
1 |
=T("appointments.txt").sort(appdate) |
2 |
=A1.group(year(appdate):year,depid,patientid;~.sum(if(#==1 || appdate-a>18:(a=appdate,0),appdate-a<12:0;(a=appdate,1))):num) |
3 |
=A2.select(num>8) |
4 |
=A3.group(year).(~.group(depid).top(5;-~.len()).new(year,depid,~.len():num)).conj() |
A4: 计算每年续诊超 8 次的病人数排前 5 的科室。A3 选出的续诊记录先按年份分组,对每年的记录再按科室分组,并选出续诊次数前五名的科室,最后构造出目标数据集:
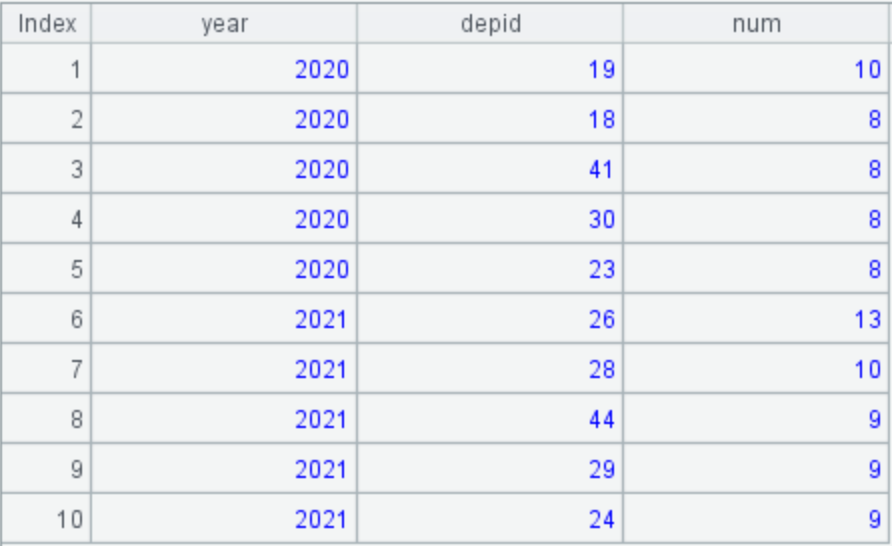
通过几个逐渐变难的例子可以看到,使用 SPL 解决比较复杂的问题时,可以化繁为简,将难题拆解为比较好解决的小问题。SPL 的 IDE 支持单步调试功能,不需要一次性写好全部脚本,可以边调试边修改,逐步完成:
数据文件附件:


英文版