


比 csv 快 N 倍的通用文件格式
用 csv 文件存储数据很普遍。类似的还有纯文本文件、tsv 文件等等,这些文件都是平面结构,没有层次关系,数据都存成文本字符。有些 xls 文件也是类似的平面结构。
csv 文件具有简单、通用性强等优点,但也存在一些明显的缺点。文本字符不能直接参与计算,把这些字符解析成日期、实数等内存数据类型是非常耗时的过程,特别是要判断非法情况时会更复杂,所以 csv 文件的性能一向不好。数据无压缩会使 csv 文件体积膨胀,占用更大存储空间,进一步拖累性能,也对文件的操作和管理造成困难。高精度数值数据存成文本还可能丢失信息,其他如日期型数据、包含逗号的字符串等也可能在解析的时候出现错误,都要人为加上引号并在解析时专门处理才能消除。
csv 文件的这些问题都可以用二进制格式的文件来解决。但是,业界缺少一种通用、简单的二进制存储格式。很多软件都有高效的二进制文件格式,但绝大多数是私有格式,不对外提供 API,也就无法供第三方使用。而 Parquet 这些开源的二进制格式文件又过于沉重了,虽然有公开的 API,但需要借助复杂的环境(比如 Hadoop)才能工作,应用成本过高。
开源计算引擎 esProc 的 btx 是一种非常简单、开放的二进制文件格式,性能比 csv 文件快 4-5 倍!在 btx 文件中,可以直接写入各种数据类型对应的内存字节,读取时也只要直接取出重新装载成内存数据,没有复杂的解析过程,也不需要判断和识别非法情况。btx 还提供了简单压缩方式,采用适当的压缩比,既能一定程度上减少硬盘空间占用,又不会在读取时带来过多的 CPU 消耗。
btx 覆盖了 csv 文件的所有功能,除了存储日期、数值、字符串等,还允许更复杂的集合和记录数据类型,支持数据的嵌套存储。
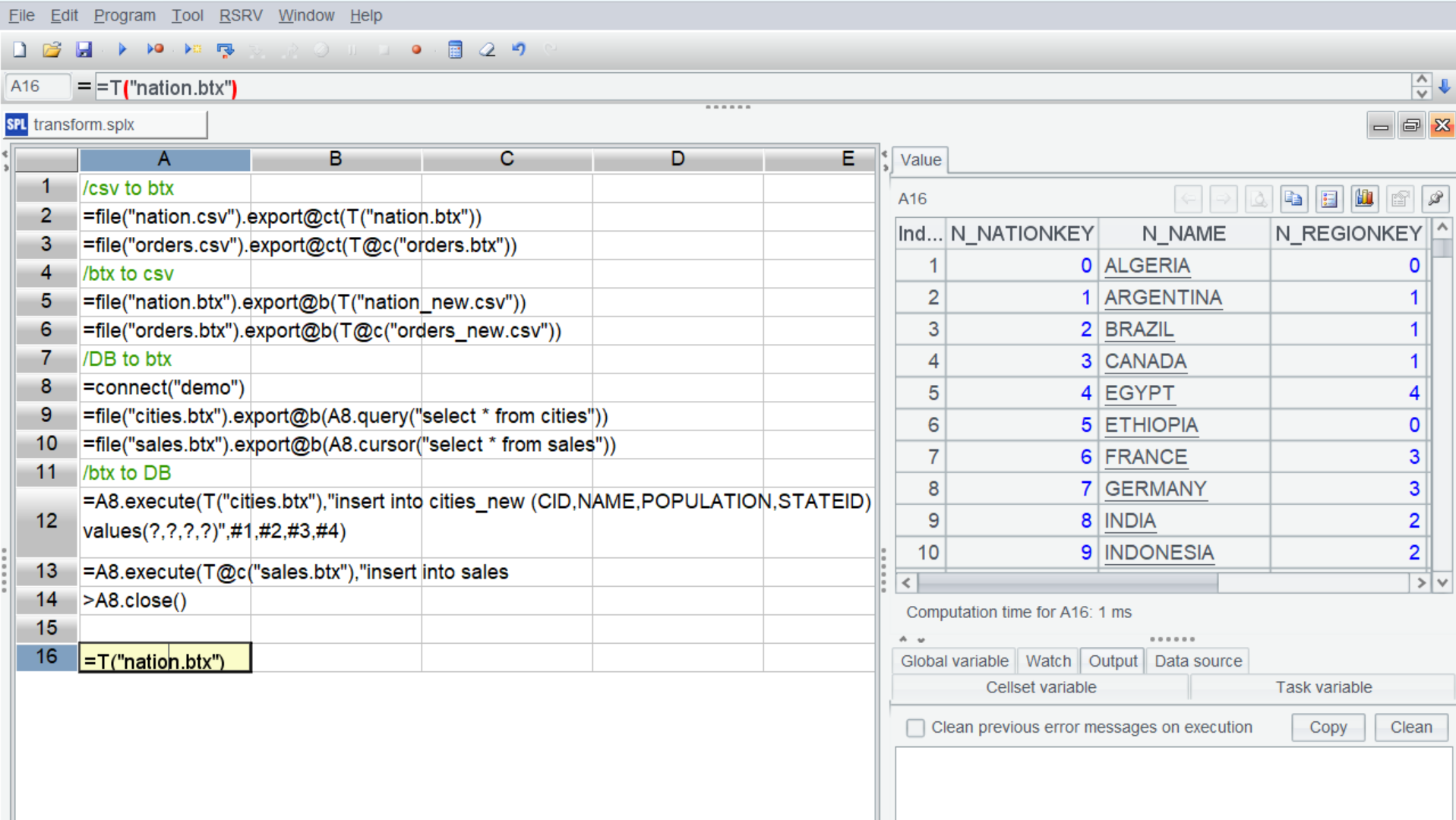
使用 esProc 提供的脚本语言 SPL 很容易实现 btx 与 csv/DB 的相互转换,可以保证 btx 的通用性:
A |
|
1 |
/btx to csv |
2 |
=file("nation.csv").export@ct(T("nation.btx")) |
3 |
=file("orders.csv").export@ct(T@c("orders.btx")) |
4 |
/csv to btx |
5 |
=file("nation.btx").export@b(T("nation_new.csv")) |
6 |
=file("orders.btx").export@b(T@c("orders_new.csv")) |
7 |
/DB to btx |
8 |
=connect("demo") |
9 |
=file("cities.btx").export@b(A8.query("select * from cities")) |
10 |
=file("sales.btx").export@b(A8.cursor("select * from sales")) |
11 |
/btx to DB |
12 |
=A8.execute(T("cities_new.btx"),"insert into cities (CID,NAME,POPULATION,STATEID) values(?,?,?,?)",#1,#2,#3,#4) |
13 |
=A8.execute(T@c("sales_new.btx"),"insert into sales(ORDERID,CLIENT,SELLERID,AMOUNT,ORDERDATE) values(?,?,?,?,?)",#1,#2,#3,#4,#5) |
14 |
>A8.close() |
除了 csv/DB 外,其他数据源都可以和 btx 相互转换,详细介绍参见 SPL 的说明文档。各种数据源转 btx 时都不需要事先建数据结构,直接写入文件就可以了,非常方便。数据量较大时,可以采用游标方式转换。
SPL 还为 btx 提供了强大的计算能力:
A |
B |
|
1 |
=T("nation.btx").select(N_NAME=="CHINA" && like(N_COMMENT,"*express*")) |
/过滤 |
2 |
=T("nation.btx").groups(N_REGIONKEY;count(1):nationCount) |
/分组汇总 |
3 |
=T("nation.btx").select(N_NATIONKEY>10).icount(N_REGIONKEY) |
/去重计数 |
4 |
=T("customer.ctx").select([2,3,5,8].contain(C_NATIONKEY)).top(3;C_ACCTBAL) |
/TOP N |
5 |
=T("nation.btx").keys(N_NATIONKEY) |
|
6 |
=T("customer.btx").switch(C_NATIONKEY,A5:N_NATIONKEY) |
/外键关联 |
7 |
=T("nation.btx").keys(N_NATIONKEY) |
|
8 |
=T("nation_info.btx").keys(NI_NATIONKEY) |
|
9 |
=join(A7:n,N_NATIONKEY;A8:ni,POPULATION) |
|
10 |
=A9.new(n.N_NAME/"-"/ni.POPULATION) |
/主键关联 |
这里每次都使用了 T() 函数读取 btx,适合独立进行多种计算。如果是连续的多步骤计算,只要读一次文件,后续计算都基于内存表就可以了。
btx 较大时,SPL 还支持大文件游标外存计算和分段并行计算。
A |
B |
|
1 |
=file("orders.btx").cursor@bm(O_ORDERKEY,O_CUSTKEY).select(between(O_ORDERDATE,date(1996,1,1):date(1996,1,31)).fetch(100) |
/大文件游标,外存过滤 |
2 |
=file("orders.btx").cursor@bm(O_ORDERDATE,O_TOTALPRICE).groups(O_ORDERDATE;sum(O_TOTALPRICE):all,max(sum(O_TOTALPRICE)):max) |
/分组汇总 |
3 |
=file("orders.btx").cursor@bm(O_CUSTKEY).total(icount(O_CUSTKEY)) |
/去重计数 |
4 |
=file("orders.btx").cursor@bm(O_ORDERKEY,O_TOTALPRICE).total(top(-10;O_TOTALPRICE)) |
/TOP N |
5 |
= T("customer.btx").keys(C_CUSTKEY) |
|
6 |
=file("orders.btx").cursor@bm(O_ORDERKEY,O_CUSTKEY,O_TOTALPRICE).switch(C_NATIONKEY,A5:N_NATIONKEY) |
/外键关联 |
7 |
=file("customer.btx").cursor@bm(C_CUSTKEY,C_ACCTBAL) |
|
8 |
=file("customer_info.btx").cursor@bm(CI_CUSTKEY,FUND) |
|
9 |
=joinx(A7:c, C_CUSTKEY;A8:ci,CI_CUSTKEY) |
|
10 |
=A9.new(c.C_ACCTBAL+ci.FUND:newValue) |
/主键关联,要求游标对主键有序 |
cursor@b 函数可以定义 btx 文件的游标进行外存计算,@m 选项表示对 btx 分段进行多线程并行计算,可以显著提高外存计算性能。
代码中文件对象 file("orders.btx") 可以定义一次反复使用。不过游标只能计算一次,每次计算都要定义新的游标。多步骤计算则可以使用延迟游标。
esProc SPL 很轻,集成开发环境 IDE 即装即用,无需像 Hadoop 那样配置各种环境,更不需要集群:
esProc 提供了标准 JDBC 驱动,使得 btx 很容易嵌入应用,只要将 esProc 核心 jar 包和配置文件放到 Java 应用的类路径中,btx 文件放到配置好的目录就可以调用了:
…
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("=T(\"nation.btx\")");
st.execute();
ResultSet set = st.getResultSet();
…
这个例子是用 Java 读取 btx 文件后进行处理,更推荐的做法是编写 SPL 脚本处理 btx 相关的各种复杂计算,代码量比 Java 简单很多。在应用中调用 SPL 脚本(比如 csv2btx.splx)也很简单,这个 Java 代码稍作修改就可以了:
…
st =con.prepareCall("call csv2btx()");
st.execute();
…
esProc 核心 jar 包非常小,只有不到 100MB。
在报表类应用中,非常适合用 btx 来存储报表的缓存数据,能够实现应用本地的可控缓存,包括部分缓存和缓存复用,效果远好于 csv 文件或数据库临时表。
在数据分析场景中,把数据库中的部分数据存入 btx 随身携带,可以随时随地使用 SPL 的 IDE 进行分析。


英文版