


数据分析编程从 SQL 到 SPL:系列事件
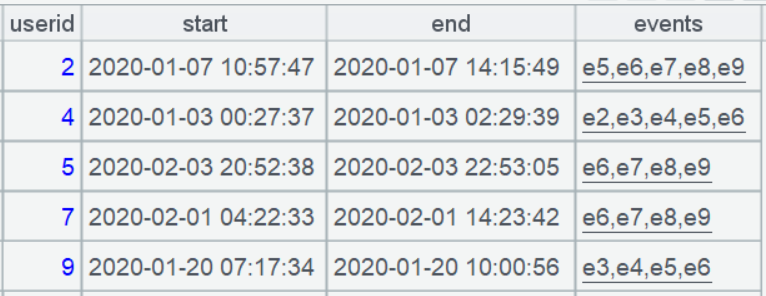
简化后的用户行为表 actions 的部分数据如下,记录各个用户 9 种事件的发生时间:
1、查找按顺序触发过 e2、e3、e7 事件的用户
顺序事件不要求连续。
按用户分组、单个用户的事件再按时间排序,循环处理该用户的每个 e2 事件,在其后查找 e3,e3 后再查找 e7,找到时当前用户就符合要求。
先看 SQL:
select distinct t1.userid
from actions t1 join actions t2 join actions t3
on t1.userid=t2.userid and t2.userid=t3.userid
and t1.etime<t2.etime and t2.etime<t3.etime
where t1.event='e2' and t2.event='e3' and t3.event='e7';
SQL 无法保持分组子集,不能针对分组后的单个用户编写处理语句,循环判断逻辑也很难实现。这里要改用自关联,用关联条件过滤出顺序事件,
条件分散在 ON 和 WHERE 子句中,其实写哪里都行,就看从什么角度理解过滤、关联,这种实现思路不自然。
SPL 能保持分组子集继续计算;处理过程循环也不难,但这里并不需要写循环, SPL 有强大的有序集合运算,其 pos 函数能在一个序列中查找子序列,容易写出契合自然思维的代码:
A |
|
1 |
="e2,e3,e7".split@c() |
2 |
=file("actions.txt").import@t().sort(etime) |
3 |
=A2.group(userid) |
4 |
=A3.select(~.(event).pos@i(A1)).(userid) |
A2 加载数据并按 etime 排序;
SPL IDE 有很好的交互性,可以单步执行并随时在右边的面板中直观地查看到每一步的结果,A3 按 userid 分组后得到多个子集,选中 A3,右侧展示它的结果数据:
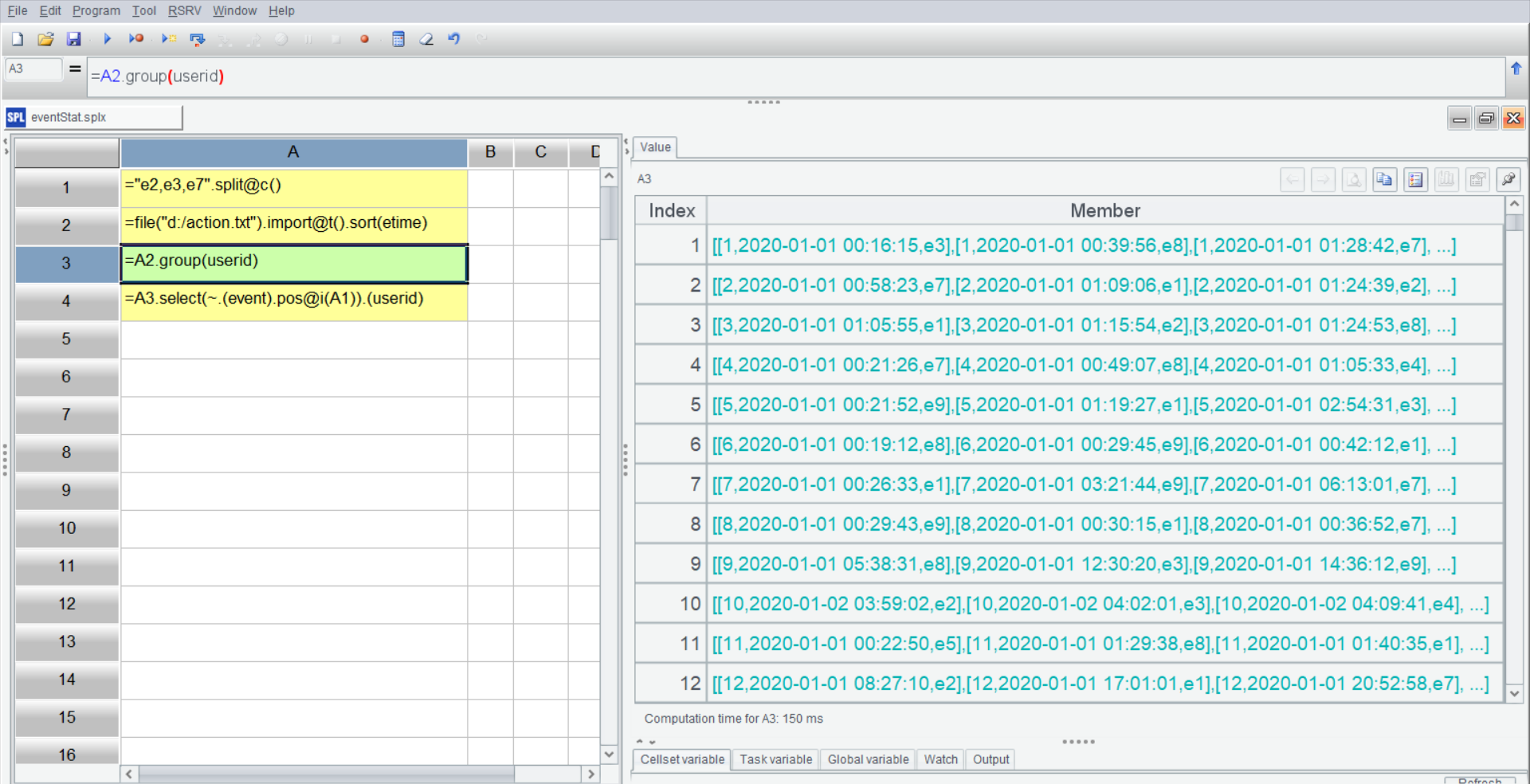
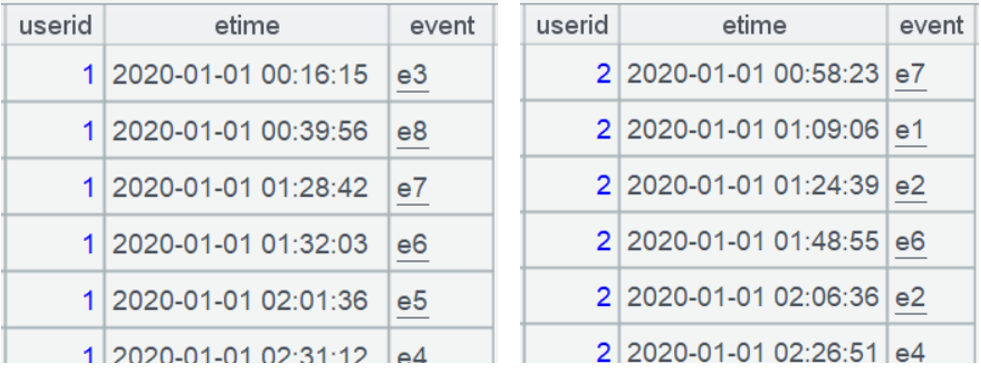
group() 函数是单纯分组,不绑定聚合运算,点开分组结果的成员能看到还是一个集合,也就是各个用户的事件集合,分组操作不会破坏原有次序,子集还会保持 etime 有序:
A4 在每个用户的 event 序列中查找 A1 递增序列出现的位置,最后用 select 选出顺序事件位置不为空的用户。
熟悉SPL后,这些步骤可以简单地写成一句:
A |
|
1 |
=file("actions.txt").import@t().sort(etime) |
2 |
=A1.group(userid) .select(~.(event).pos@i(["e2","e3","e7"])).(userid) |
2、查找连续触发过 e2、e3、e7 事件的用户
要查找连续事件,单个用户循环处理每个 e2 事件时,判断后一个是否为 e3,再后一个是否为 e7 即可。
SQL:
with t as (
select userid,etime,event,
row_number() over(partition by userid order by etime) rn
from actions)
select distinct t1.userid
from t t1 join t t2 join t t3
on t1.userid=t2.userid and t2.userid=t3.userid and t1.rn+1=t2.rn and t2.rn+1=t3.rn
where t1.event='e2' and t2.event='e3' and t3.event='e7';
SQL 的集合无序,不能直接按位置获取数据,要用窗口函数先人为生成一个序号,然后关联条件中用序号计算来表达前后关系,也有点绕。
SPL 的集合有序,也能按位置获取数据,可以直接按自然思路写代码:
A |
|
1 |
=file("actions.txt").import@t().sort(etime) |
2 |
=A1.group(userid) |
3 |
=A2.select(~.(event).pselect(~=="e2" && ~[1]=="e3" && ~[2]=="e7")).(userid) |
A3 中,针对分组子集 (~,也就是当前用户的记录),用 ~.(event) 取出 event 字段值组成序列,例如用户 1 的事件序列:

针对这个序列的每个成员,用 pselect 判断当前成员 ~,以及紧邻的后两个成员 ~[1]、~[2] 三个值是否匹配目标事件,,能匹配上时,pselect 将返回该成员的位置,所有成员都不匹配上则返回 null。最外层的 select 函数选出所有非 null 的分组,也就是连续触发过 e2、e3、e7 事件的用户分组,最后用.(userid) 获得用户 ID 组成的结果序列。
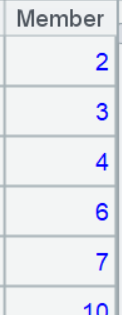
对于这个问题,SPL 的 pos 函数可以直接找连续子序列 (用 @c 选项表示),A3 还可以写成更简单的写法:
3 |
=A2.select(~.(event).pos@c(["e2","e3","e7"])).(userid) |
3、给定的多个事件,查找按次序发生过其中任意 3 个事件的用户及其事件列表
给定多个事件,用它算出来多个长度为 3 的顺续事件子序列,比如 e2,e3,e7,e6 算出 [e2,e3,e7]、[e2,e3,e6]、[e2,e7,e6]、[e3,e7,e6],要查找触发过这些事件序列的用户。
单句 SQL 做不了过程化的计算,难以算出这些连续事件,就只能认为事先知道这些事件序列,用上题中的方法算出触发每个事件序列的用户,然后再求并集。
SPL 容易逐步地做过程化计算,甚至支持递归。基于集合的有序性、按位置引用特点,能处理任意多个给定事件和目标事件序列长度:
A |
B |
C |
|
1 |
="e2,e3,e7,e6".split@c() |
||
2 |
=file("actions.txt").import@t().sort(etime) |
||
3 |
=A4.group(userid) |
||
4 |
=A3.select(incseq(~.(A1.pos(event)).select(~),3)) |
||
5 |
func incseq(s, n) |
||
6 |
if n>s.len() |
return false |
|
7 |
if n==1 |
return true |
|
8 |
return s.cor( incseq( ~[1:].select(~>s.~), n-1) ) |
||
我们把给定的事件 e2,e3,e7,e6 分别编号为 1,2,3,4,将用户的事件序列转换成编号序列,那么查找长度为 3 的顺序事件子序列,就等同于在转换后的编号序列中查找长度不少于 3 的递增子序列。
5~8 行定义 incseq 函数,用于判断任意数列中是否存在给定长度的递增子序列。
假如用户 1 的事件编号序列是 [2,3,1,4,1,3],有递增序列 2,3,4,那么 incseq([2,3,1,4,1,3], 3) 结果为 true;
假如用户 2 的事件编号序列是 [4,2,3,1,1,3],没有长度为3的递增序列,那么 incseq([4,2,3,1,1,3], 3) 为 false;但有长度为 2 的递增序列,incseq([4,2,3,1,1,3], 2) 为 true。
A4 用 pos 函数把 A3 中每个用户的事件序列转换成前面说的编号序列,不在给定事件中的事件,pos 将返回 null,然后被后面的 select 筛选掉。再用 incseq 判断每个用户是否存在长度为 3 的递增序列 (也就是长度为 3 的顺序事件) 就可以了。
incseq 函数的主要逻辑方法在 B8,其中~[1:]表示当前成员之后成员的子序列,再用 seelct(~>s.~)筛选出其中比当前成员更大的成员,这里 s.~ 是外层循环函数 s.cor()的当前成员,内层.select() 的当前成员直接用 ~ 表示。然后递归判断筛选后成员构成的序列中是否有长度为 n-1 的递归子序列,如果有,那么配合当前成员就可以构成长度为 1 的递增子序列,incseq 就可以返回 true。这里用了逻辑或函数 cor,它在循环过程中一旦发现有 true 就会立即结束返回,不再继续计算下去。
4、查询各用户所有长度超过 3 的连续事件信息
任意连续事件是指事件序号连续,最短的连续事件有两个事件,如 [e1、e2]、[e2、e3] 、[e3、e4] 等,最长连续事件为[e1,e2,……e9]。
长度超过 3 的连续事件有 21 组(6+5+…+1=21),如果再像上题一样逐个算出后求并集,那写出来的 SQL 会很冗长。
另外这里并不只是找出用户了,还要取出详细的连续事件信息 (起止时间和连续事件字串):
SQL 没有分组子集,无法针对每次连续事件这个小集合计算出这些信息,用什么替代方案去绕着写,很难,就不尝试写了。
SPL 利用集合有序、针对分组子集计算、按位置取数等特性,面对这种复杂计算,仍然容易按照自然思路逐步实现:
A |
|
1 |
=file("actions.txt").import@t().sort(etime) |
2 |
=A1.group(userid) |
3 |
=A2.(~.group@o(int(right(event,1))-#).select(~.len()>3)) |
4 |
=A3.conj() |
5 |
=A4.new(userid, ~(1).etime:start,~.m(-1).etime:end,~.(event).concat@c():events) |
A2 按用户分组,得到每个用户事件子集:
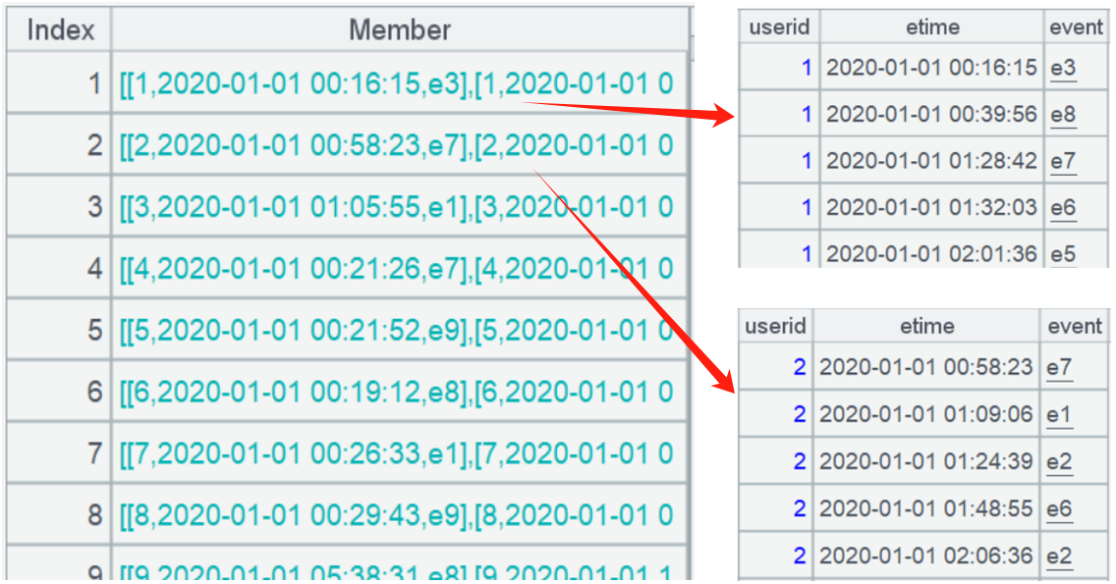
A3 中对每个用户事件子集做有序分组,即已经有序的集合用 group 函数分组,@o 表示只比对相邻值。分组表达式为事件本身序号 (e 后面的数字,1~9) 减去事件在子集中的序号(用 #表示),假如是连续事件,这两个序号都是按每次递增 1,相减后就会相等,会分到同一组,这样可以找到了所有连续事件的子集;之后过滤出成员数大于 3 的子集,也就是发生过 3 次连续事件。
结果如下,用户 39、42、44 等没找到超过 3 的连续事件;用户 40 找到两组连续事件;用户 41、43 各找到一组。现在找到了目标连续事件,连续分组等运算后仍然保留了全部原始信息:
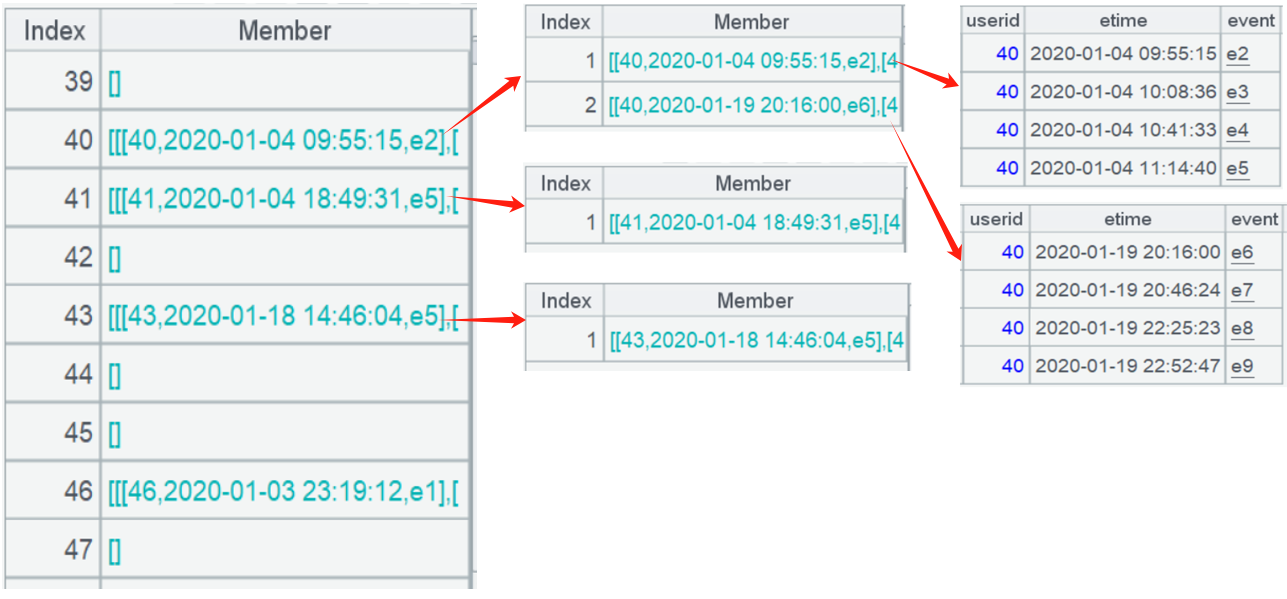
这样形成了一个三层的集合,即 A3 的值是由集合构成的集合再构成的集合。
A4 用 conj 函数把各个用户的连续事件子集合并起来,变成两层的集合。观察一下,能看到 40、41、43 三个用户的 4 组连续事件:
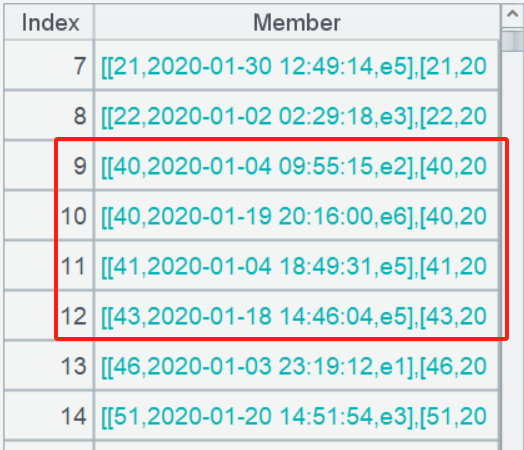
A5 用 new 函数针对每组连续事件子集计算出起止时间和连续事件字串就可以了。
熟练后,通常会把 conj 动作写到前面以简化代码:
3 |
=A2.conj(~.group@o(int(right(event,1))-#).select(~.len()>3)) |
4 |
=A3.new(userid, ~(1).etime:start,~.m(-1).etime:end,~.(event).concat@c():events) |


英文版