


数据分析编程从 SQL 到 SPL:机场分析
数据结构和样例数据:
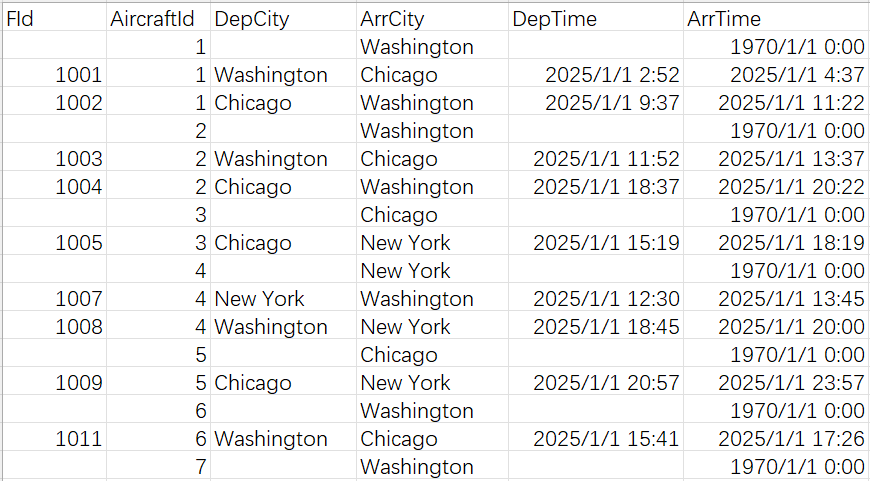
表中存储的是 2025 年 1 月 1 日飞机出发、到达城市机场的数据。
其中 FId 是航班号,AircraftId 飞机号,DepCity 出发城市,ArrCity 到达城市,DepTime 出发时间,ArrTime 到达时间。
当天 0 点时已经有些飞机停留在这些城市了。比如表中第一条记录表示 AircraftId 为 1 的飞机这一天开始的时候已经在华盛顿了,这种情况下 FId、DepCity、DepTime 被置为空,ArrTime 被置为 1970/1/1 0:0:0。
业务规定,每个航班号在一天时间内最多只会出现一次。
1. 停留在纽约的飞机,最多时有多少架
这一天中,有的飞机到达纽约、有的离开,正在这个城市停留的飞机总数是不断变化的。现在要计算停留在纽约的飞机最多时有多少架。
把到达或者离开纽约的航班数据按照时间排序,到达的以到达时间为准、离开的以出发时间为准。然后将到达的记录标记为 1,出发的记录标记为 -1,从头开始累计这个标记就能得到每条记录对应的,当时正在纽约停留的飞机数量了。如下表:
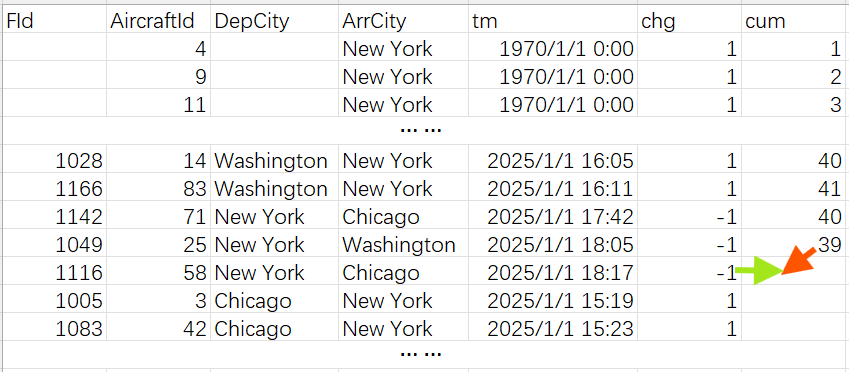
tm 是出发或到达时间,chg 是到达出发标记。循环计算这个表,用当前行的 chg 和上一行的 cum 求和得到本行的累计值 cum,就是正在纽约停留的飞机数量。
循环结束后,取 cum 的最大值即可得到期望的结果。
SQL 可以用窗口函数 sum 实现累计。
with t1 as (
select FId, DepTime tm, -1 chg
from flights
where DepCity='New York'
union all
select FId, ArrTime tm, 1 chg
from flights
where ArrCity=' New York '
),
t2 as (
select *, sum(chg) over(order by tm,chg) cum
from t1
)
select max(cum)
from t2;
SPL 也有类似的累计函数求出最大值:
A |
|
1 |
=T("flight.csv") |
2 |
=A1.select(DepCity=="New York").derive(DepTime:tm,-1:chg) |
3 |
=A1.select(ArrCity=="New York").derive(ArrTime:tm,1:chg) |
4 |
=(A2|A3).sort(tm,chg).derive(cum(chg):cum).max(cum) |
A2、A3 分别求出纽约出发、到达数据集合,计算 tm、chg 列。这里用单元格来存储两个集合,省去定义临时变量。
SPL 的 IDE 有很好的交互性,可以单步执行并随时在右边的面板中直观地查看到每一步的结果:
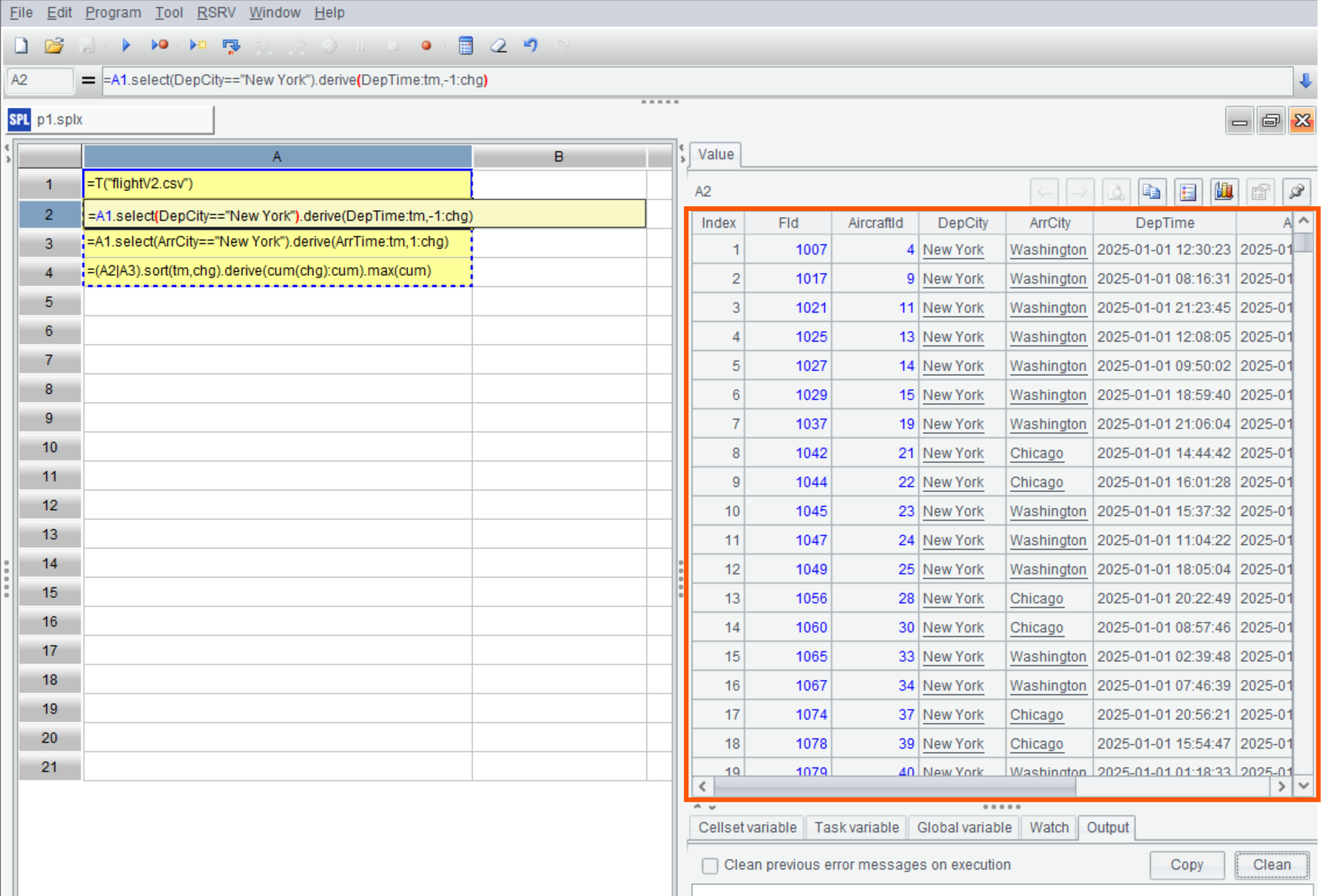
A4:合并 A2、A3,并排序、计算出 chg 累计值 cum。
derive 是循环函数,直接针对集合实施循环处理,不必再写 for…next 这样的多条语句块。循环中使用迭代累积函数 cum,就可以实现上面讲的思路,计算出 cum 列。
最后,求出 cum 列的最大值。
只计算 cum 列的最大值,可以不必生成这个列:
A |
|
1 |
=T("flight.csv") |
2 |
=A1.select(DepCity=="New York").new(DepTime:tm,-1:chg) |
3 |
=A1.select(ArrCity=="New York").new(ArrTime:tm,1:chg) |
4 |
=(A2|A3).sort(tm,chg).max(cum(chg)) |
2. 纽约停留飞机最多时,哪些航班最晚到达这个城市
假设纽约停留飞机最多时是 n 架,现在要查出:在最晚一次有 n 架飞机停留的时刻之前,最后到达纽约的 n 个航班数据。
用任务一的办法求出 cum 列,找到 cum 最后一个最大值所在的记录:
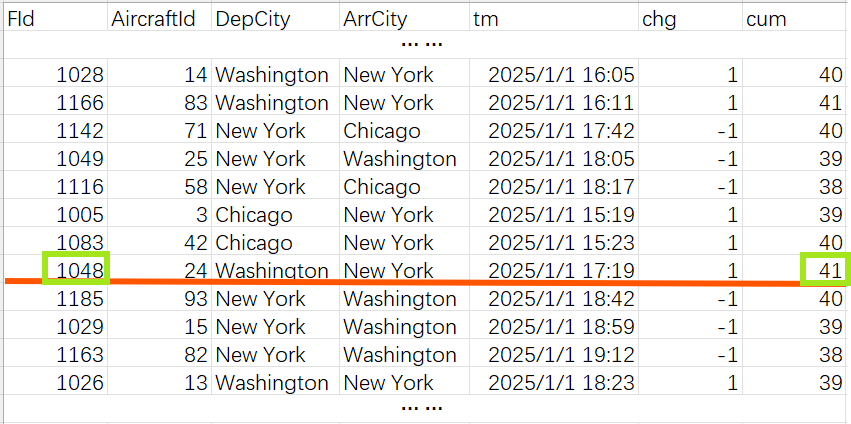
这条记录的 FId 是 1048,cum 是 41(也就是 n)。把到达纽约的航班数据按照 tm 排序,从中查出 1048 的位置:
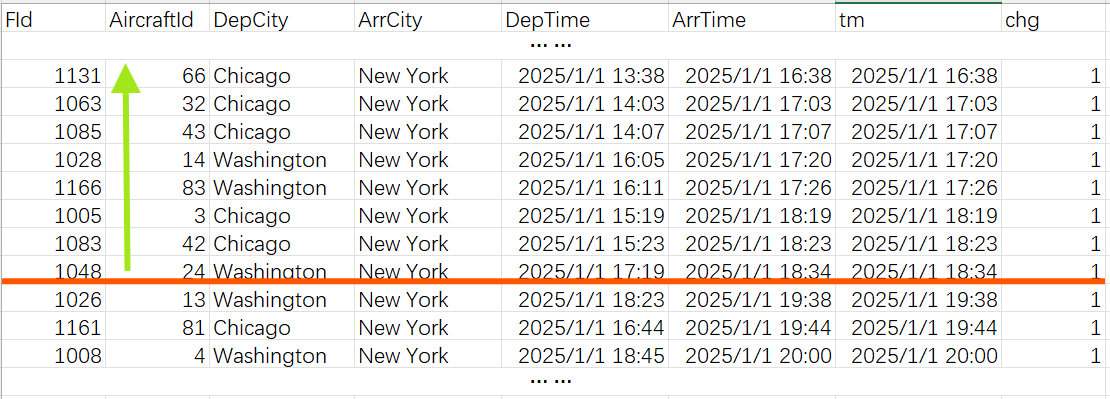
从这个位置向上取 n=41 条记录,就是期望的结果。
SQL 的聚合函数 max 只能返回最大值,不能返回最大值所在记录。找 cum 最后一个最大值所在记录的时候,要改成把数据按照 cum 和 tm 降序排序后取第一条记录。
SQL 也不直接支持用位置引用记录,在从 1048 向前取 41 条记录的时候,只能用窗口函数人为造出序号,然后在外层查询中用序号作为条件查出目标。
with t1 as (
select DepTime tm, -1 chg
from flights
where DepCity='New York'
union all
select ArrTime tm, 1 chg
from flights
where ArrCity='New York'
),
t2 as (
select tm, sum(chg) over(order by tm,chg) cum
from t1
),
t3 as (
select *
from t2
order by cum desc, tm desc
limit 1
),
t4 as (
select f.*,row_number() over(order by ArrTime desc) rn
from flights f, t3
where f.ArrCity='New York' and f.ArrTime<=t3.tm
)
select t4.*
from t4,t3
where rn<=t3.cum
order by ArrTime;
子查询从任务一的两个增加到四个,而且增加了窗口函数,语句复杂了很多。
SPL 支持位置计算,而且特有的 maxp 函数可以返回最大值所在的记录,很容易实现上述思路:
A |
|
1 |
=T("flight.csv") |
2 |
=A1.select(DepCity=="New York").derive(DepTime:tm,-1:chg) |
3 |
=A1.select(ArrCity=="New York").derive(ArrTime:tm,1:chg) |
4 |
=(A2|A3).sort(tm,chg).derive(cum(chg):cum).maxp@z(cum) |
5 |
=A3.sort(tm) |
6 |
=A5.pselect(FId==A4.FId) |
7 |
=A5.to(A6-A4.cum+1,A6) |
A4用 maxp@z 代替任务一中的max,取得最大值所在记录而不是最大值本身。maxp的@z选项表示从后往前找到第一个成员,这里就是指时间最晚的一个。
A5 把 A3 按照 tm 排序,A6 查到 FId 值 1048 在 A5 中的位置,A7 从这个位置开始向前取 n 条记录。
3. 纽约停留飞机最多时,哪些航班最晚到达并停留在这个城市
假设纽约停留飞机最多时是 n 架,要查出最后一次有 n 架飞机停留的时刻之前,最晚到达纽约且未飞走的航班数据。
先找到 cum 最后一个最大值的位置,把这个位置向前的所有记录组成新的集合:
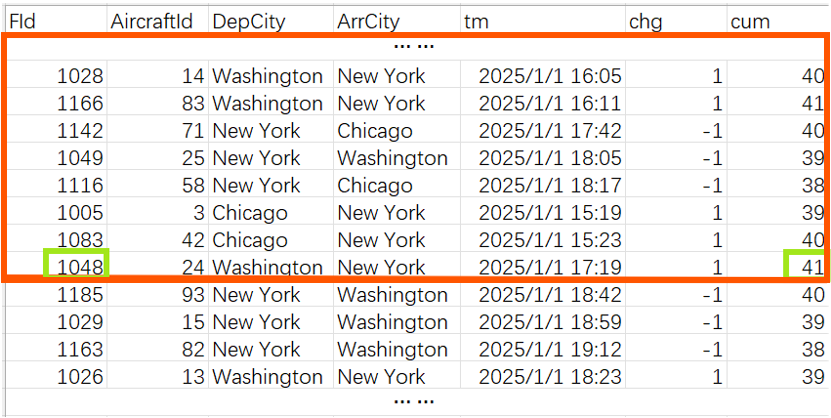 把新集合的记录调换先后顺序,倒序为下表:
把新集合的记录调换先后顺序,倒序为下表:
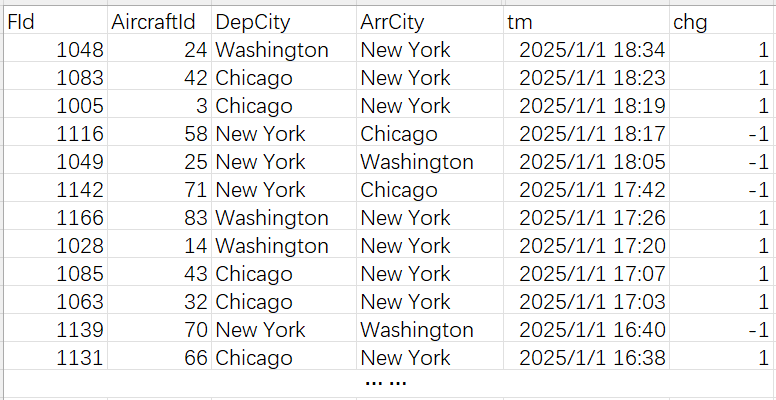
把这个表按照 AircraftId 分组。以 AircaftId 是 24 的飞机为例,分组子集是:

组内数据的时间仍是降序排序的,飞机从纽约到华盛顿,又飞回纽约,在 cum 最后一个最大值出现之前没有离开纽约。可以看出,若组内第一条记录的 chg 是 1,那么这就是到纽约而且没有飞走的航班记录。
接下来,每组只取第一条记录,再以 chg=1 为条件过滤一下,就能得到期望的结果。
SQL 不能直接取组内第一条记录,要用窗口函数人为造出组内序号,然后在外层查询中用序号作为条件查出目标:
with t1 as (
select *, DepTime tm, -1 chg
from plane
where DepCity='New York'
union all
select *, ArrTime tm, 1 chg
from plane
where ArrCity='New York'
),
t2 as (
select *, sum(chg) over(order by tm,chg) cum
from t1
),
t3 as (
select *
from t2
order by cum desc, tm desc
limit 1
),
t4 as (
select t1.*,
row_number() OVER(PARTITION BY AircraftId ORDER BY tm desc) AS rno
from t1,t3
where t1.tm<=t3.tm
)
select * from t4 where chg=1 and rno=1
SPL 支持直接取组内第一条记录,可以轻松实现这个思路:
A |
B |
|
1 |
=T("flight.csv") |
|
2 |
=A1.select(DepCity=="New York").derive(DepTime:tm,-1:chg).sort(tm) |
|
3 |
=A1.select(ArrCity=="New York").derive(ArrTime:tm,1:chg).sort(tm) |
|
4 |
=[A2,A3].merge(tm,chg) |
=A4.to(A4.pmax@z(cum(chg))).rvs() |
5 |
=B4.group@1(AircraftId).select(chg==1) |
|
A4 有序归并 A2、A3,IDE 左边预览窗口可以看到计算结果:
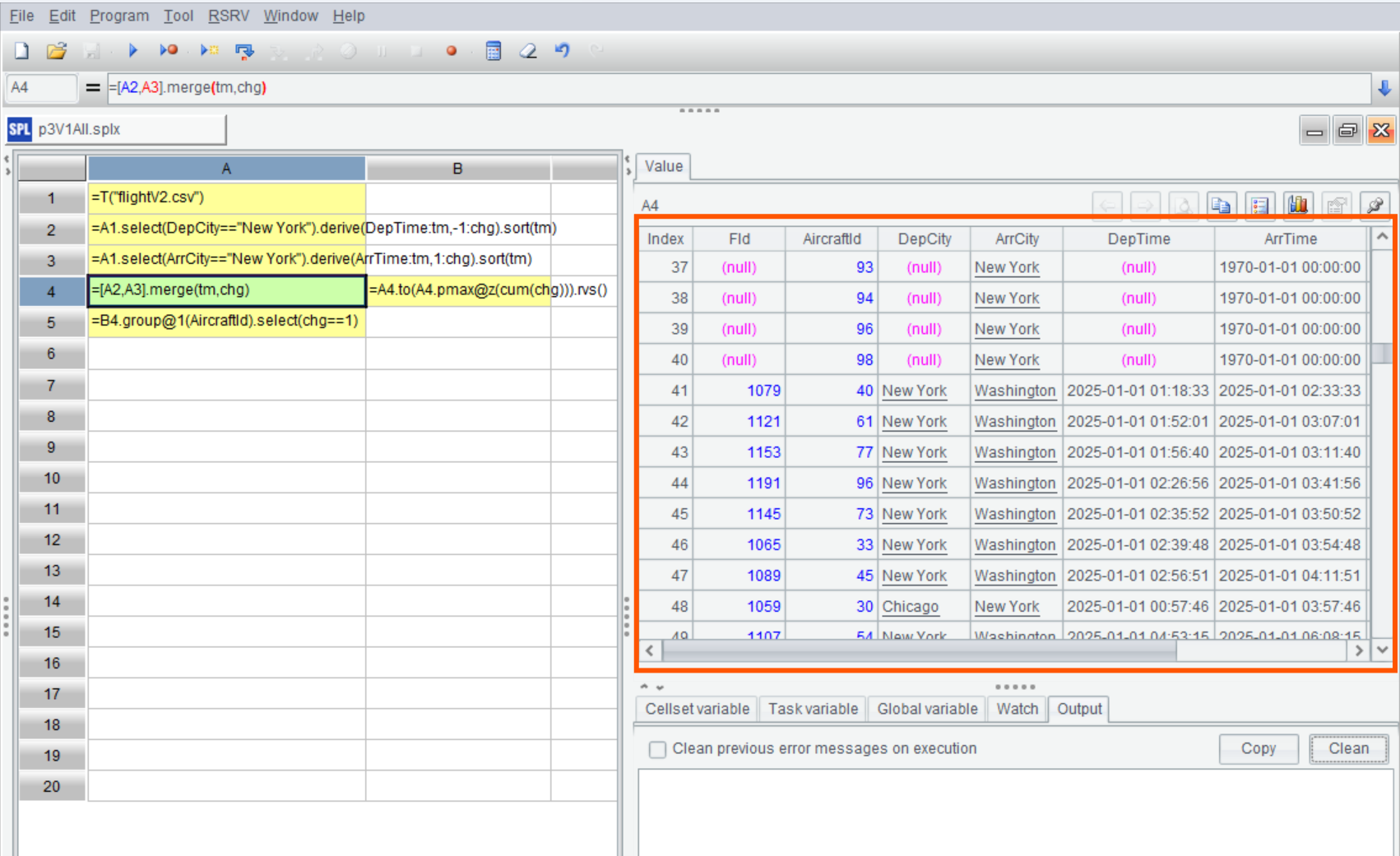
B4 按照上述思路,找到 cum 最后一个最大值所在的位置,把这个位置之前的所有记录组成的集合倒置。这里用 pmax 函数代替任务二中的 maxp,是找到最大值所在记录的位置序号,而非记录本身。
A5 中的 group@1 表示取每组第一条记录。最后用 chg 为 1 的条件过滤这些记录,就能得到期望的结果。


点击这里下载数据文件
英文版