


数据分析编程从 SQL 到 SPL:用户事件统计 - 续
本篇接续《数据分析编程从 SQL 到 SPL:用户事件统计》,
延用用户行为表 actions,记录各个用户 9 种事件的发生时间:
3、连续 4 天活跃度排名前 500 的用户
用户每天的事件数量越多则认为越活跃,活跃度排名就是事件数量排名。
按日期和用户分组汇总事件数量,继而找出每天事件数最多的前 500 个用户,针对每连续的 4 天,计算其交集,也就是连续 4 天活跃度都在前 500 名的用户,最后计算这些用户的并集再去重。
先看 SQL:
with t1 as (
select date(edate) edate, userid, count(*) cnt
from actions
group by date(edate), userid),
t2 as (
select edate, userid, rank() over(partition by edate order by cnt desc) rn from t1),
t3 as (
select * from t2 where rn<=500),
t4 as (
select a2.edate,a2.userid from t3 a1
join t3 a2 on a1.userid=a2.userid and a1.edate=a2.edate-interval 1 day
join t3 a3 on a1.userid=a3.userid and a1.edate=a3.edate-interval 2 day
join t3 a4 on a1.userid=a4.userid and a1.edate=a4.edate-interval 3 day
)
select distinct userid from t4 order by userid;
SQL 分组时不能保持分组子集,不能直接针对每天的用户实施排名,要针对已经分组汇总过的子查询(t1)继续用窗口函数再对 edate 二次分组(partition by)才能算出日内排名,分组写法重复。
而且,SQL 窗口函数要在查询结果集上才能计算,这就迫使过滤前 500 名不能和排名在一句 SQL 语句中完成,要拆成两个子查询(t2,t3)。
SQL 集合无序,不能简单按位置引用连续的 4 天,要用 JOIN 自关联将连续 4 天拼到一起计算,实现思路很不自然。
SPL 能保持分组子集,也能用位置引用集合成员,简单用自然思维写出代码就可以:
A |
|
1 |
=file("actions.txt").import@t() |
2 |
=A1.group(date(etime)).( ~.groups(userid;count(1):cnt).top@r(-500;cnt) .(userid) ) |
3 |
=A2.(if(#>3,~[-3:0].isect())) .conj() .id() |
A2 按日期分组,得到每天的事件子集;针对每天的事件子集 ~,再分组汇总各个用户的事件数 cnt,用 top() 函数即可取出事件数最多的前 500 名用户。
A3 针对每日计算,这里 ~ 是当日,~[-3:0] 就是前 3 天到当日的连续 4 天,用 isect()函数计算这四天(前 500 名)用户的交集,再用 conj() 求并集,最后用 id() 去重。
大部分过程式程序语言的集合运算能力较弱,而有一定集合运算能力的SQL对过程的支持又弱,SPL则改善了两者缺陷,过程式步骤很清晰,基本一个函数就实现一个计算步骤,还提供了强大的集合运算,特别是有序集合的运算。
4、每天统计最近 7 天 (含当天) 中连续活跃 3 天及以上人数
用户在一天中有一个事件发生,即被认定为活跃。
用最早、最晚日期算出目标日期序列,然后用每个用户的事件和这些日期去匹配,匹配不到事件的日期为 null,然后判断每个用户每天之前的七天中是否有连续 3 天活跃,最后统计出每天符合条件的人数。
with recursive edates as (
select min(date(etime)) edate from actions
union all
select date_add(edate, interval 1 day) from edates
where edate<(select max(date(etime)) from actions)
),
users as (
select distinct userid from actions
),
crox as (
select u.userid, d.edate, t.edate rdate
from edates d cross join users u
left join (select distinct userid, date(etime) edate from actions) t
on d.edate=t.edate and u.userid=t.userid
),
crox1 as (
select userid,edate, rdate, row_number() over(partition by userid order by edate) rn,
case when rdate is null or
(lag(rdate) over(partition by userid order by edate) is null and rdate is not null)
then 1 else 0 end f
from crox
),
crox2 as (
select userid, edate, rdate,
cast(rn as decimal) rn, sum(f) over(partition by userid order by edate) g
from crox1
),
crox3 as (
select t1.userid, t1.edate, t2.g, case when count(*)>=3 then 1 else 0 end active3
from crox2 t1 join crox2 t2
on t1.userid=t2.userid and t2.rn between t1.rn-6 and t1.rn
group by t1.userid,t1.edate,t2.g
),
crox4 as (
select userid, edate, max(active3) active3
from crox3
group by userid,edate
)
select edate, sum(active3) active3
from crox4
group by edate;
这句 SQL 非常复杂,子查询很多,还用了递归语法,看懂就很难,写出来就更困难。这里不再解释了,感兴趣的同学可以自己尝试。
SPL 还是能按照自然思路写出代码:
A |
|
1 |
=file("actions.txt").import@t() |
2 |
=periods(date(A1.min(etime)), date(A1.max(etime))) |
3 |
=A1.group(userid).(~.align(A2,date(etime))) |
4 |
=A3.(~.(~[-6:0].pselect(~&&~[-1]&&~[-2]))) |
5 |
=A2.new(~:date, A4.count(~(A2.#)):count) |
A2 用最早、最晚日期生成目标日期序列;
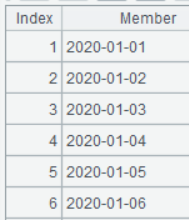
A3 按用户分组后,用 align 函数把每个用户的事件与日期序列 A2 的每天对齐,形成每个用户每天的活跃状态序列:
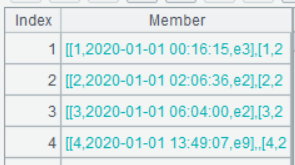
点开其中某个成员,可以看到这样的序列:
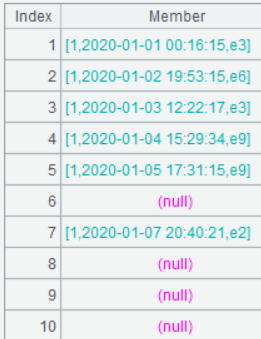
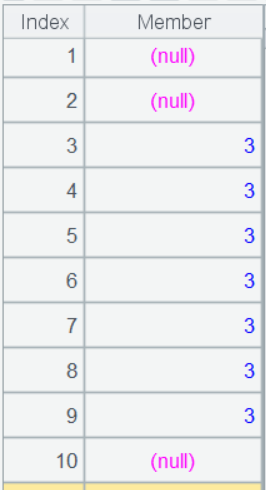
某天有对应的事件即表示该用户活跃,如用户 1 前 10 日中有 6 天活跃,对应不上的为 null:
A4 继续处理每个用户的活跃状态序列,对于每一天,在当天及其前 6 天这 7 天的活跃状态序列(~[-6:0])中用 pselect() 查找是否有一天及其前 2 天(即连续 3 天)都活跃(状态不为 null),找到则返回该天在 7 天中的第几天,找不到返回 null,即可判断这 7 天中是否有连续 3 天活跃,pselect 的返回值即构成一个描述该用户在每 7 天中是否有 3 天活跃的状态序列。
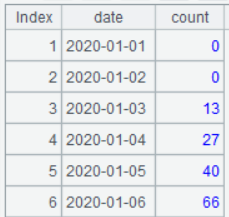
A5 只要针对每天统计所有用户在 A4 中的状态序列中对应位置的成员(即某用户在该天的状态)不为 null 的次数,也就是该天及其前 6 天的 7 天中有 3 天活跃的用户数量:
随着计算需求变复杂,SQL 的编写难度并非线性变化,无法针对分组子集定义运算、集合无序、跨行复杂运算总得找迂回替代方案等因素会加剧困难。而 SPL 可以按照自然思维逐步追加新计算步骤,容易调试,能大幅提高编码效率。


英文版