


数据分析编程从 SQL 到 SPL:用户事件统计
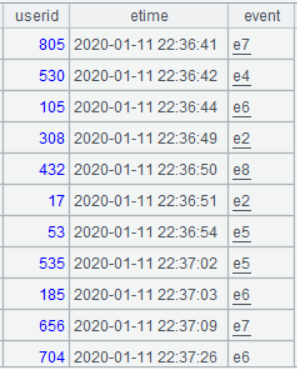
简化后的用户行为表 actions 的部分数据如下,记录各个用户 9 种事件的发生时间:
1、计算每个用户会话次数
一个用户超过 2 天无操作或 e8 事件后 2 小时无操作,则认为一次会话结束。
基本思路是按用户分组后,在每个用户的事件集合中统计会话结束条件成立的的次数,再加 1 就是会话次数了(有过 n 次会话结束就是 n+1 个会话)。
SQL 代码:
with t1 as (
select userid,etime,event,
lag(event) over(partition by userid order by etime) event1,
lag(etime) over (partition by userid order by etime) etime1
from action)
select userid, sum(
case when timestampdiff(second,etime1,etime)>172800
or (event1='e8' and timestampdiff(second,etime1,etime)>7200) then 1
else 0 end)+1 cnt
from t1 group by userid;
SQL 的集合无序,成员没有位置的概念,不能按位置引用集合成员,要用窗口函数 lag 把前一个事件算出来,条件中涉及前一个事件的 event 和 etime,就要把较长的 lag 语句写两遍,比较繁琐。
受限于 SQL 语言的复杂度,窗口函数算出来的值还不能直接用在主查询里,要用子查询预先算成 event1、etime1,给解题又增加了麻烦。
SQL 不能保持分组子集,每一步计算都要针对全体数据临时再分组,这里出现两次 partition by 和一次 group by 共 3 次分组运算,书写也很复杂。
SPL 的集合有序,能方便地用相对位置引用数据,也可以保持分组子集,按照自然思路写代码即可:
A |
|
1 |
=file("actions.txt").import@t().sort(etime) |
2 |
=A1.group(userid ; ~.count( interval@s(etime[-1],etime) >172800 || (event[-1]=="e8" && interval@s(etime[-1],etime)>7200) )+ 1 : cnt) |
A1 读入数据后按 etime 排序。
A2 按 userid 分组,group 函数中的 ~ 代表分组子集,也就是当前用户的事件集合,其成员仍然是按 etime 有序的,SPL 分组后的数据会保持住原本次序。SPL 提供了 [] 实现相对位置引用数据,etime[-1]和 event[-1]分别表示是上一行 etime 和 event,判断会话结束条件就很简单。
2、统计新用户第二天的留存率
新用户第二天留存率 = 第二天继续访问人数 / 第一天新用户人数。
找出每个用户的活跃 (即有事件发生) 的日期,找出这些日期的最早那天,也就是该用户作为新用户出现的那一天,再看第二天是否仍在该用户的活跃日期中,如果在,则表明该用户留存了。最后计数后即可算出每日的留存率。
with t1 as (
select userid, date(etime) edate from actions group by userid,date(etime)),
t2 as (
select userid, edate, row_number() over(partition by userid order by edate) rn
from t1
),
firstday as (
select userid, min(edate) frst from t2 group by userid),
retention as (
select fd.userid, frst, t.edate nxt
from firstday fd left join t2 t
on fd.userid=t.userid and date_add(fd.frst, interval 1 day)=t.edate
group by fd.userid, frst, nxt
)
select frst edate, count(nxt)/count(frst) rate
from retention
group by edate
order by edate;
子查询 t1 用 group by 找到了各个用户的活跃日期,但这时的结果集合是无序的,还要在 t2 中用窗口函数在每个用户范围内标记事件的序号 rn,以获取第一个事件所在的日期。
再用这个日期算出第二天,然后看该日期是否在用户活跃日期集合中,SQL 不能保持单个用户的事件子集,无法直接针对这些子集做计算,只能变换思路实现,用第一天加 1 去左连接整个日期集合,以获得用户是否留存的判断,代码理解难度变大。
SPL 的集合有序,也能针对分组子集运算,能完全贴合思路写出代码:
A |
|
1 |
=file("actions.txt").import@t() |
2 |
=A1.groups(userid,date(etime):edate) |
3 |
=A2.group(userid) |
4 |
=A3.new(userid, edate:frst, ~.select@1(edate==frst+1).edate:nxt) |
5 |
=A4.groups(frst ; count(nxt)/count(frst):rate) |
A2 中 groups() 函数计算日期的同时按 userid、edate 分组,分组结果聚合了日期,并且是有序的,不用再人为标记序号了:
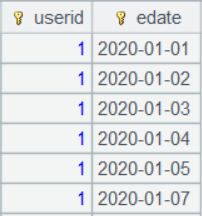
SPL IDE 有很好的交互性,可以单步执行并随时在右边的面板中直观地查看到每一步的结果,A3 按 userid 分组后得到多个子集,选中 A3,右侧展示它的结果数据:
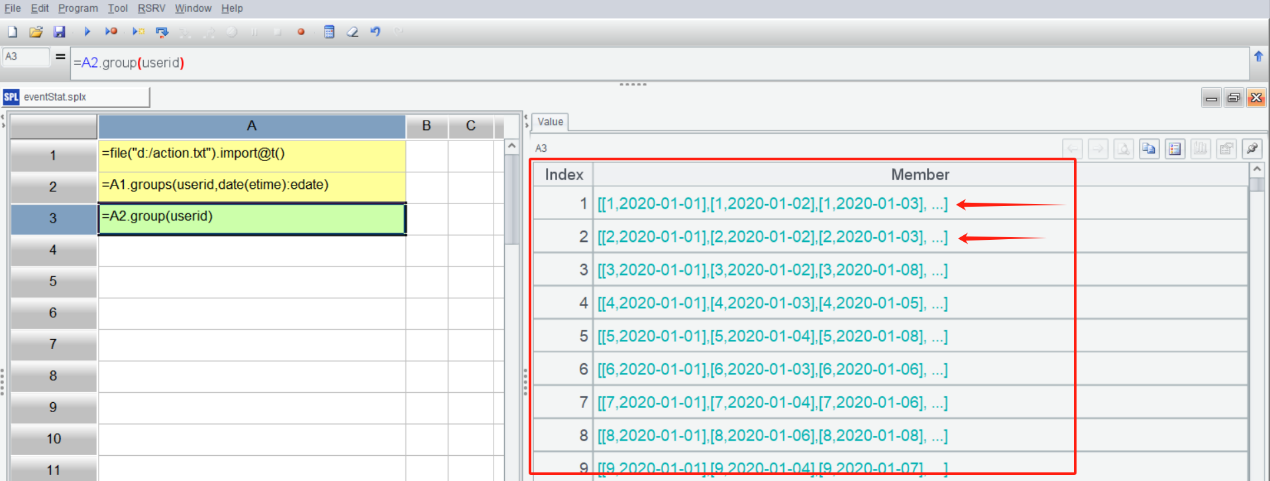
group() 函数是单纯分组,不强制绑定聚合运算,点开分组结果的成员能看到还是一个集合,也就是各个用户的日期集合:
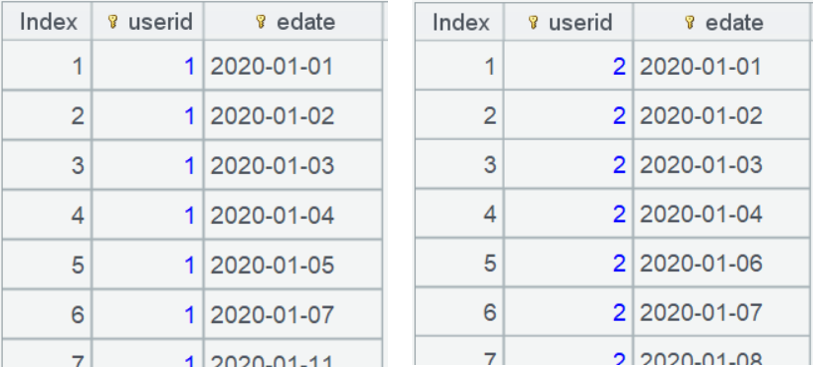
A4 中 new() 函数内针对每个用户事件集合计算,其中 edate 默认是第一个日期,也就是第一天,~ 表示当前分组子集,在其中查找第二天 nxt 是否存在,找不到返回 null 表示该用户未留存:
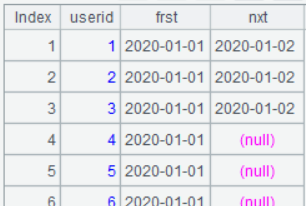
最后简单计数并计算比率就可以了。
熟悉SPL后,这些步骤可以简单地写成一句:
A |
|
1 |
=file("actions.txt").import@t() |
2 |
=A1.groups(userid,date(etime):edate).group(userid) .new(userid, edate:frst, ~.select@1(edate==frst+1).edate:nxt) .groups(frst ; count(nxt)/count(frst):rate) |
更多示例请看下一篇:《数据分析编程从 SQL 到 SPL:用户事件统计 - 续》


英文版