


SPL 报表开发:不依赖逻辑数仓的轻量级多数据源报表
背景
报表经常会基于多种数据源,如 RDB、NoSQL、文本、Excel、MQ 等。
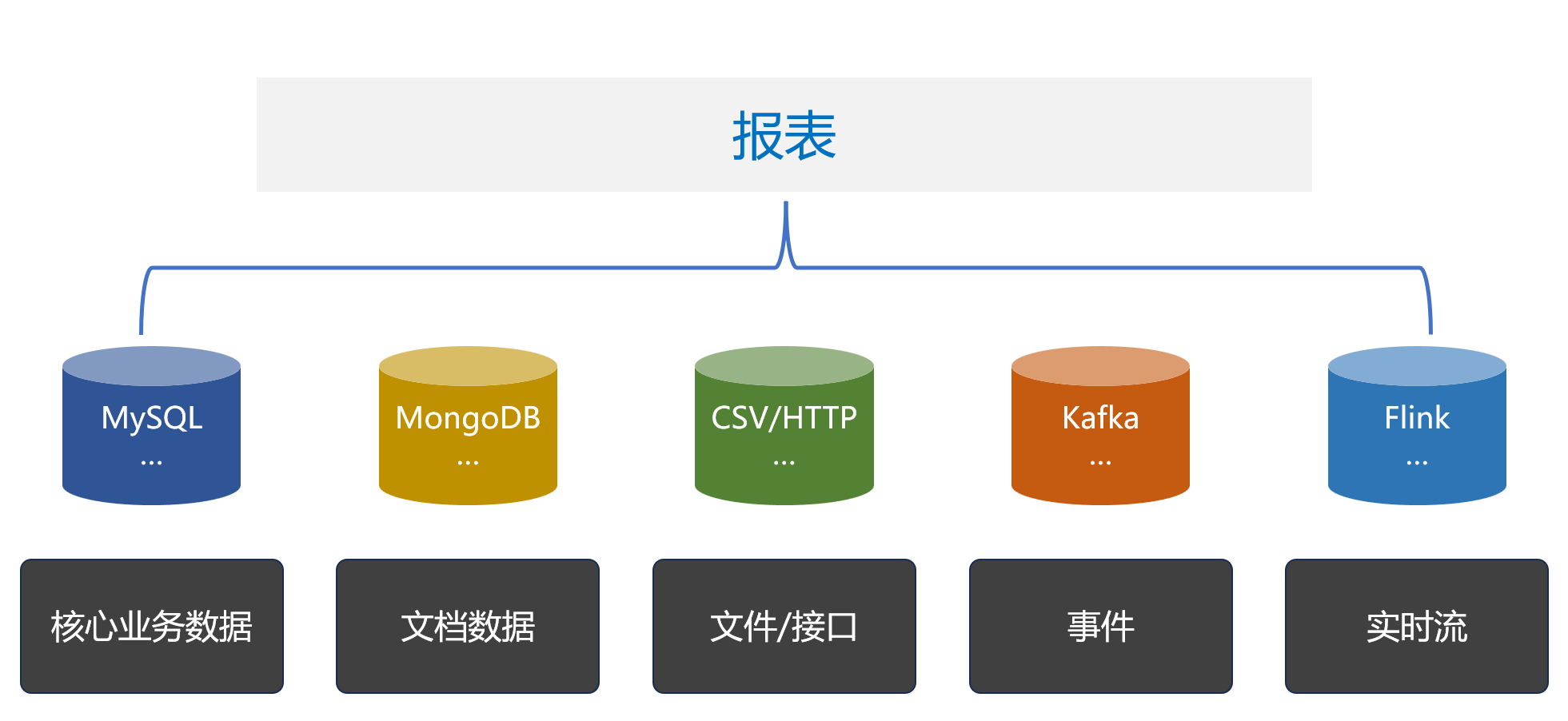
借助逻辑数据仓库可以一定程度上实现多源混算,但其架构往往过于复杂和沉重,需要繁琐的预处理过程以运维管理工作,更适合大型机构的平台级解决方案。对于一个普通报表应用来说就太沉重了,专门建设逻辑数仓有点得不偿失。
SPL 方案
SPL 提供了多数据源实时混合计算功能,无论何种数据源只要能访问到就都能混算,非常轻量,还能直接嵌入到报表应用工作。报表、SPL、数据源的关系如下:
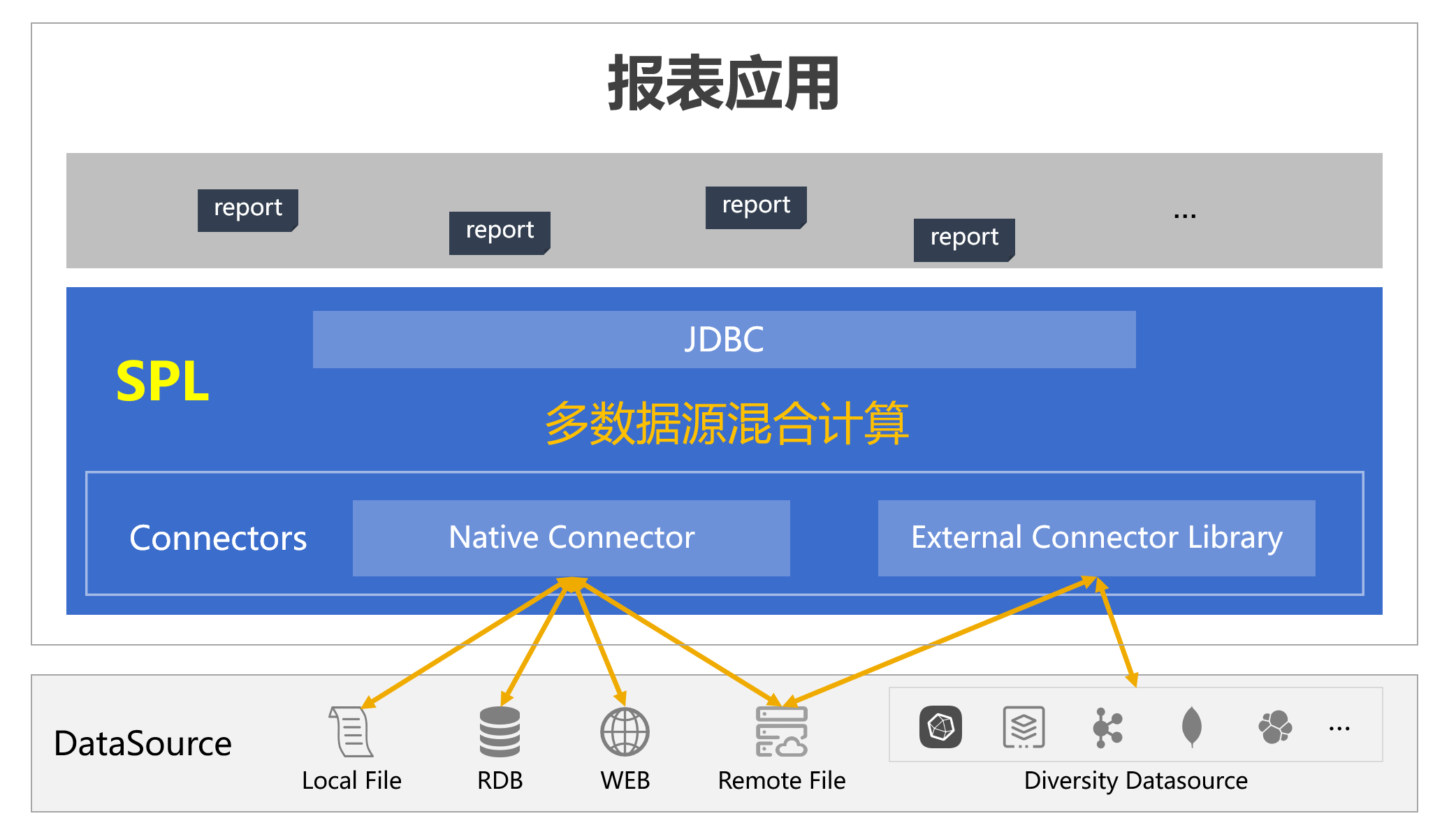
SPL 的数据源连接器分为两种:原生连接器和外部连接器。最常见的 RDB,文本、Excel、JSON 等本地文件,以及 HTTP 数据源等都属于原生连接器,内置在 SPL 核心体系中。而其他多样性数据源,如 MongoDB、Kafka、ElasticSearch、云存储都属于外部连接器,不在 SPL 核心体系内,需要另外部署。
与逻辑数仓的映射方式不同,SPL 支持并提倡使用数据源的原生语法实现数据访问和计算,如果数据源本身的计算能力不足,则可以使用 SPL 来补充,在后面实例中会具体看到。
SPL 支持数据源种类很多,这里列出了 SPL 支持的部分数据源,基本常见的数据源都包含了。

其中,原生连接器支持的数据源种类包括:MySQL、Oracle 等 JDBC 数据源;CSV、Excel、JSON 文件等 Local File;HTTP、RestAPI 等 Web 数据源,以及远程文件等。
SPL 提供了两种数据对象(序表和游标)用于访问数据源,分别对应内存数据表和流式游标。
包括关系数据库在内,几乎所有的数据源都会提供这两种数据对象的接口:小数据一次性读出,使用内存数据表;大数据要逐步返回,使用流式游标。有了这两种数据对象,就可以覆盖几乎所有的数据源了。
和逻辑数仓不同,SPL 不需要事先定义元数据做映射,直接使用数据源本身提供的方法来访问数据,只要封装成这两种数据对象之一即可。
这样可以保留数据源的特点,充分利用其存储和计算能力。当然更不需要像物理数仓那样先把数据做“某种”入库动作,实时访问就可以。
接下来看一下具体使用。
SPL IDE 配置连接器配置数据源
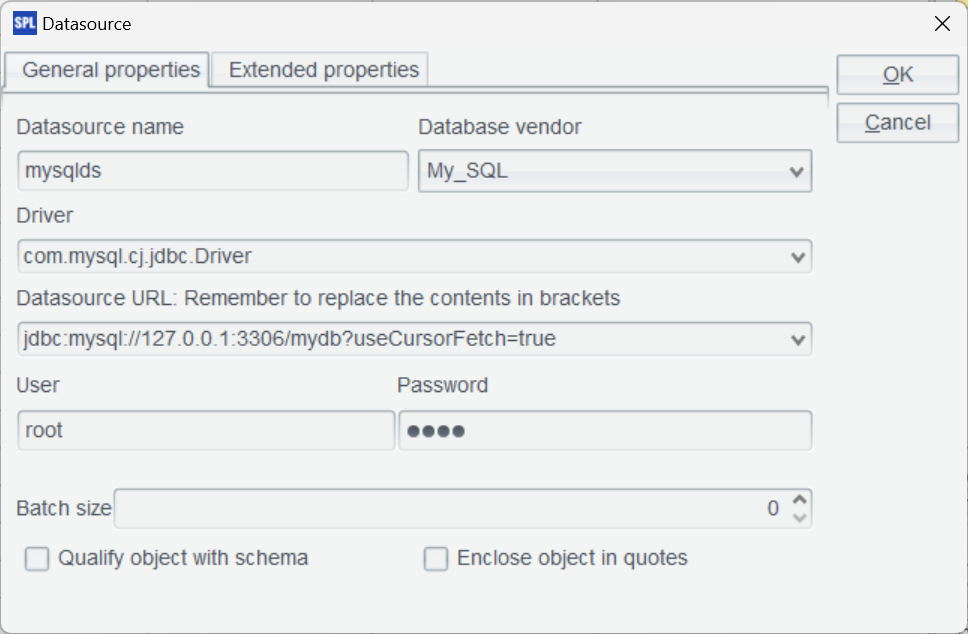
对于原生连接器,在 IDE 内配置最常见的 JDBC 连接,这里使用 MySQL。复制数据库驱动 jar 到:[SPL 安装目录]/ common/jdbc 下,如图示配置 MySQL 标准 JDBC 连接。
使用外部连接器,需要下载外部库驱动包,具体地址请参照 SPL 论坛上的下载链接。将其解压至任意目录(缺省在 [SPL 安装目录]\esProc\extlib)加载外部库。
外部库列表包括以下数十种非常规数据源及函数:
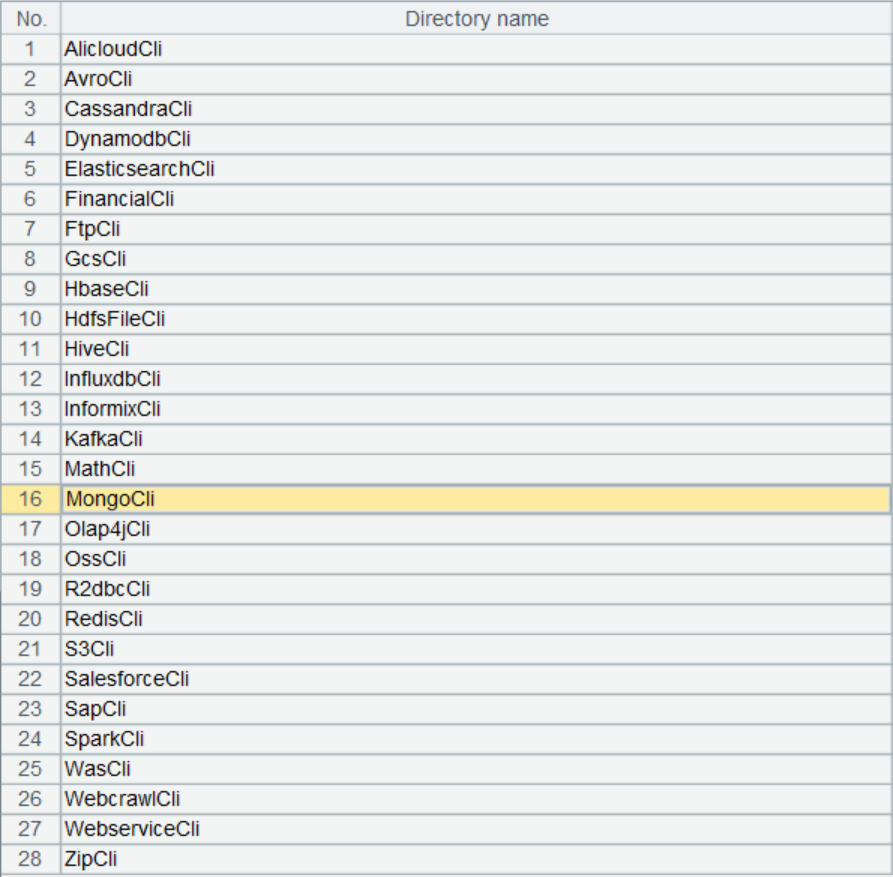
外部连接器放在外部库中,外部库是 SPL 提供的外部函数扩展库,将一些在普遍场景使用频率不高的专门用途函数以外部库形式提交,这样可以根据需要临时加载。
外部数据源种类繁多,也不是每种数据源都很常用,所以将这些连接器以外部库的形式提供会更为灵活,以后发现有新的数据源也可以及时补充而不影响现有的数据源。
绝大多数外部库都是外部连接器。
在 IDE 的菜单 tool-Options,Environment 选项卡下选择刚刚下载解压的外部库目录。
这时所有外部库都会列出来,然后勾选需要加载的外部库。
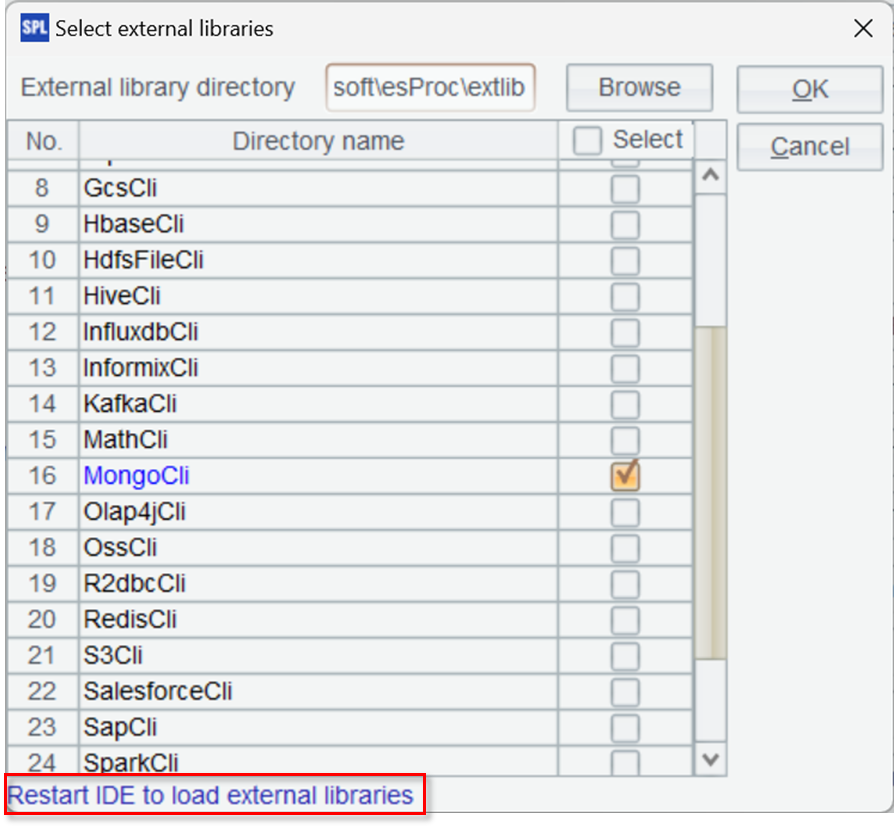
这里选择了 MongoDB,勾选确定后需要重启 IDE 才能生效。
混算实例
Mongodb 与 MySQL 混合查询
我们的报表查询实例来源于电商业务,使用 MySQL 存储订单相关信息,涉及的两个表 orders 和 order_items 结构是这样的:
Orders:
字段 |
类型 |
说明 |
order_id |
INT (PK) |
订单标识 |
user_id |
INT |
用户 ID |
order_date |
DATETIME |
订单日期 |
total_amount |
DECIMAL(10, 2) |
订单金额 |
Order_items:
字段 |
类型 |
说明 |
order_item_id |
INT (PK) |
商品项标识 |
order_id |
INT(FK) |
订单 ID |
product_id |
VARCHAR(20) |
商品 ID |
quantity |
INT |
购买数量 |
price |
DECIMAL(10, 2) |
单价 |
两个表通过 order_id 关联。
由于商品信息会根据类型动态变化,比如电子产品有品牌、型号和规格,而服装则包括品牌、尺寸和颜色,因此使用 MongoDB 来存储商品信息,其中 attributes 字段为动态属性。
字段 |
说明 |
product_id |
商品 ID(与 MySQL 关联) |
name |
名称 |
brand |
品牌 |
category |
分类 |
attributes |
动态属性 |
商品集合通过 product_id 与 MySQL 关联。
这是 MySQL 和 MongoDB 的示例数据。
Orders:
order_id |
user_id |
order_date |
total_amount |
1 |
101 |
2024-09-01 |
1999.99 |
2 |
102 |
2024-09-02 |
1599.99 |
… |
Order_items:
order_item_id |
order_id |
product_id |
quantity |
price |
1 |
1 |
prod_1001 |
1 |
999.99 |
2 |
1 |
prod_1002 |
1 |
1000.00 |
3 |
2 |
prod_1003 |
1 |
1599.99 |
… |
MongoDB:
{
"product_id": "prod_1001",
"name": "Smartphone X",
"brand": "BrandA",
"category": "Electronics",
"attributes": {
"color": "Black",
"storage": "128GB"
}
},
{
"product_id": "prod_1002",
"name": "Laptop Y",
"brand": "BrandB",
"category": "Computers",
"attributes": {
"processor": "Intel i7",
"ram": "16GB"
}
…
}
基于订单销售统计报表,查询最近一个月(时间段),‘Tablets’, ‘Wearables’, ‘Audio’ (商品种类)这三类商品的销售总额,会涉及跨 MySQL 和 MongoDB 混合查询。
SPL 实现脚本(orderAmount.splx):
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date >= CURDATE()- INTERVAL 1 MONTH") |
3 |
=mongo_open("mongodb://127.0.0.1:27017/raqdb") |
4 |
=mongo_shell@d(A3, "{'find':'products', 'filter': { 'category': {'$in': ['Tablets', 'Wearables', 'Audio'] } }}” ) |
5 |
=A2.join@i(product_id,A4:product_id,name,brand,category,attributes) |
6 |
=A5.groups(category;sum(price*quantity):amount) |
7 |
return A6 |
A1 连接 MySQL,并在 A2 通过 SQL 查询一个月内的订单数据,选项 @x 表示查询后关闭数据库连接。查询结果是这样的。
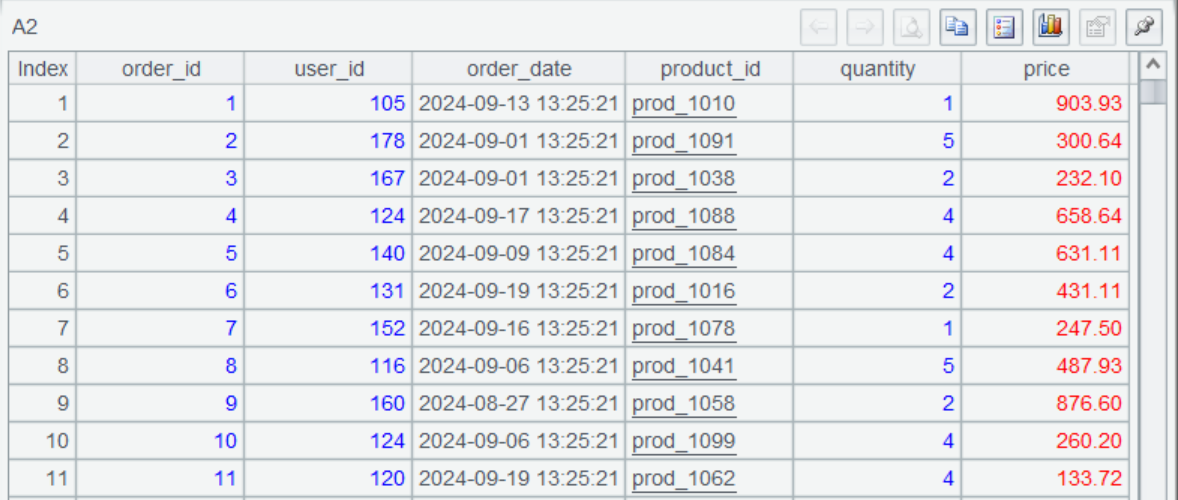
A3 连接 MongoDB。
A4 使用 mongo_shell 函数查询并过滤数据,@d 选项表示返回序表。函数参数是 MongoDB Command 标准的 JSON 字符串,也就是 MongoDB 的原生语法。可以看到符合条件的数据查出来了。
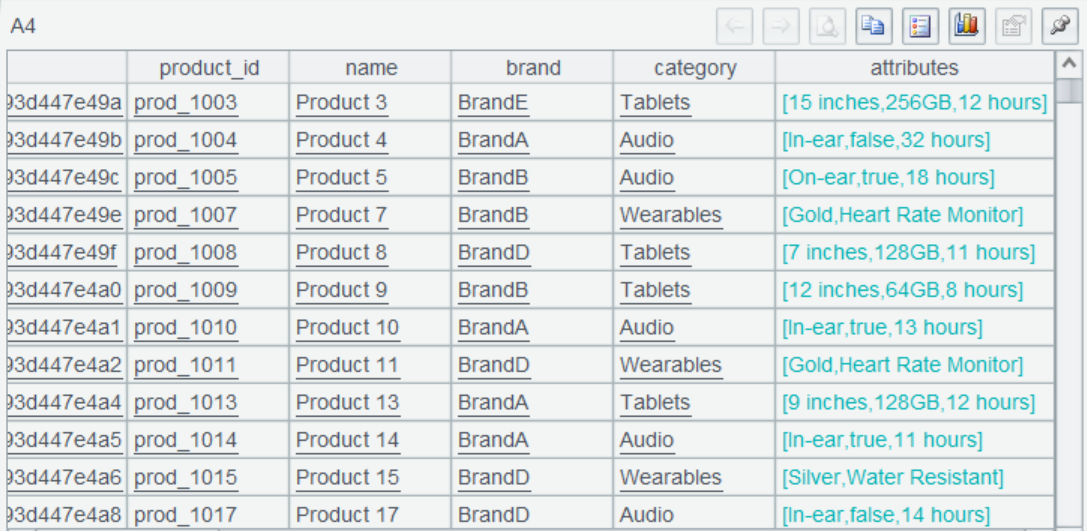
A5 将两部分通过 product_id 进行关联,这是关联结果。
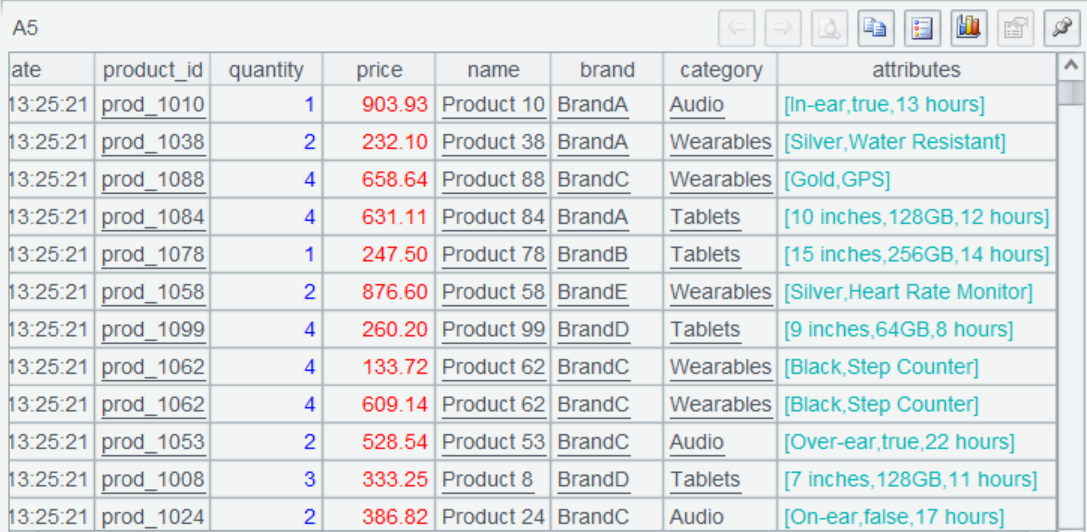
A6 按产品种类汇总订单金额,算出最终结果。
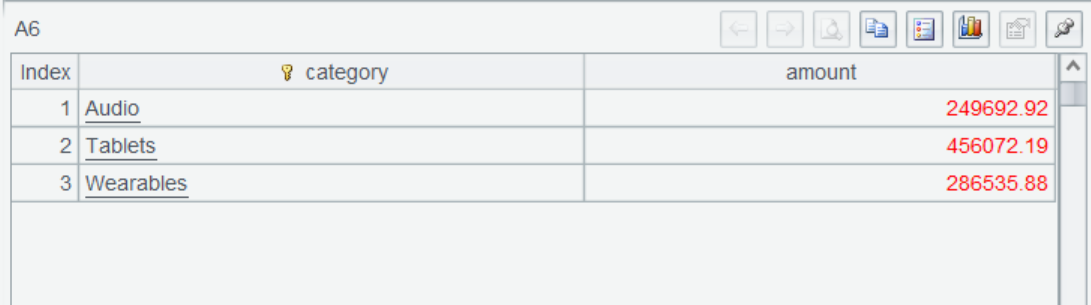
A7 通过 return 为报表返回计算后结果集。
Kafka 与 MongoDB 混合查询
接下来再使用 kafka 来参与计算。
基于前面的场景,使用 kafka 进行订单信息和商品信息发布,用户下单时,订单数据将被发送到 order 主题。
生产者脚本示例:
A |
|
1 |
=kafka_open("/mafia/my.properties","topic-order") |
2 |
[ { "order_id": "1", "user_id": "101", "product_id": "prod_1001", "quantity": 1 }, … ] |
3 |
=kafka_send(A1, "A101", json(A2)) |
4 |
=kafka_close(A1) |
A1 连接 kafka 服务器,用到的属性文件 my.properties 内容是这样的:
bootstrap.servers=localhost:9092
client.id=SPLKafkaClient
session.timeout.ms=30000
request.timeout.ms=30000
enable.auto.commit=true
auto.commit.interval.ms=1000
group.id=spl-consumer-group
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
A2 是要发送的订单数据,正常需要接收来自程序传递,这里仅是示例就直接写好。
A3 发送订单数据,A4 关闭连接。
报表数据来源是消费数据的脚本 (orderConsumer.splx),我们要查询指定分类下的商品信息,首先要设置商品分类参数:
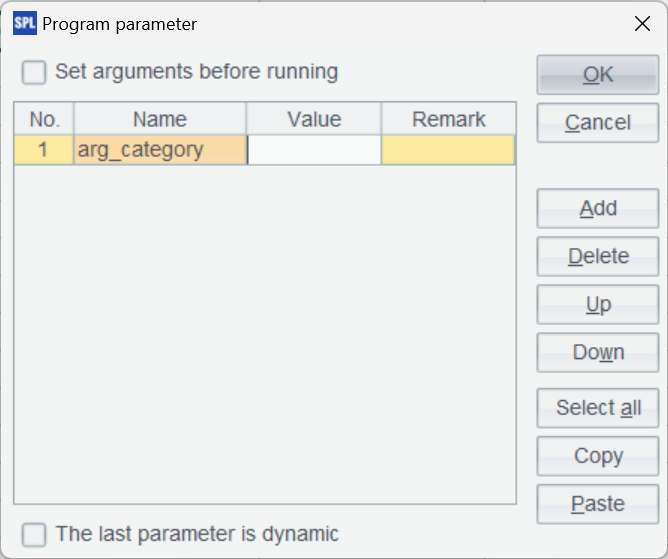
脚本如下:
A |
|
1 |
=kafka_open("/mafia/my.properties","topic-order") |
2 |
=kafka_poll(A1) |
3 |
=json(A2.value) |
4 |
=mongo_open("mongodb://127.0.0.1:27017/raqdb") |
5 |
=mongo_shell@d(A4,"{'find':'products'}") |
6 |
=A3.join(product_id,A5:product_id,product_id,name,brand,category,attributes) |
7 |
return A6.select(category== arg_category) |
A2 获取 consumer 消息记录,返回序表,结果是这样:
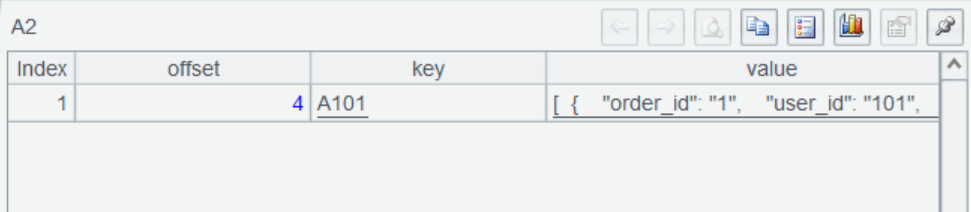
A3 将订单数据 JSON 串转换成序表。
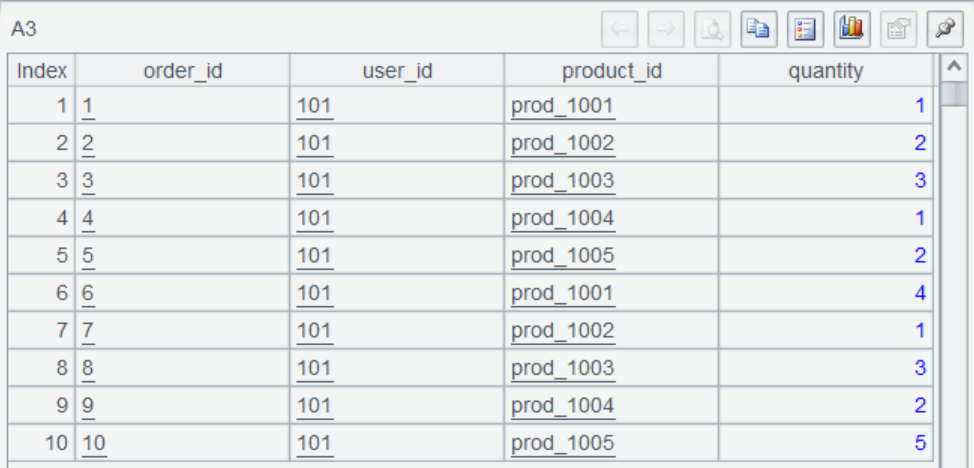
A5 查询商品数据。
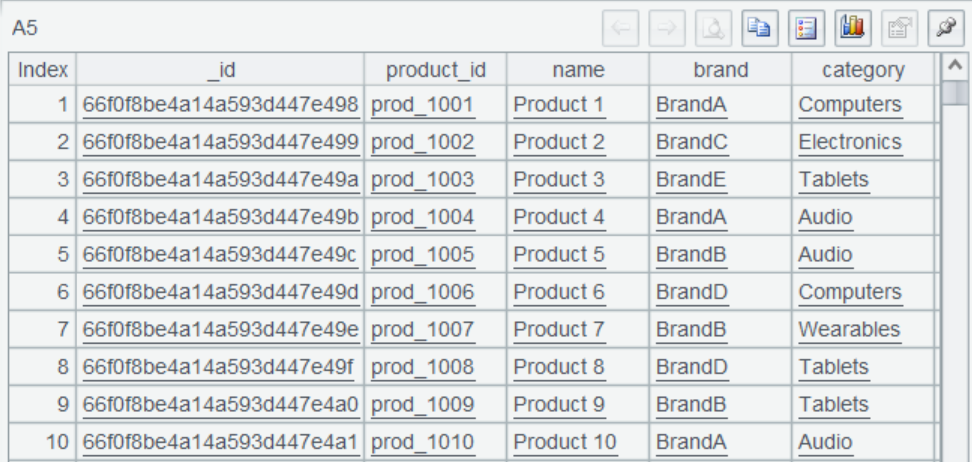
A6 根据 product_id 关联,得到订单及商品所有信息。
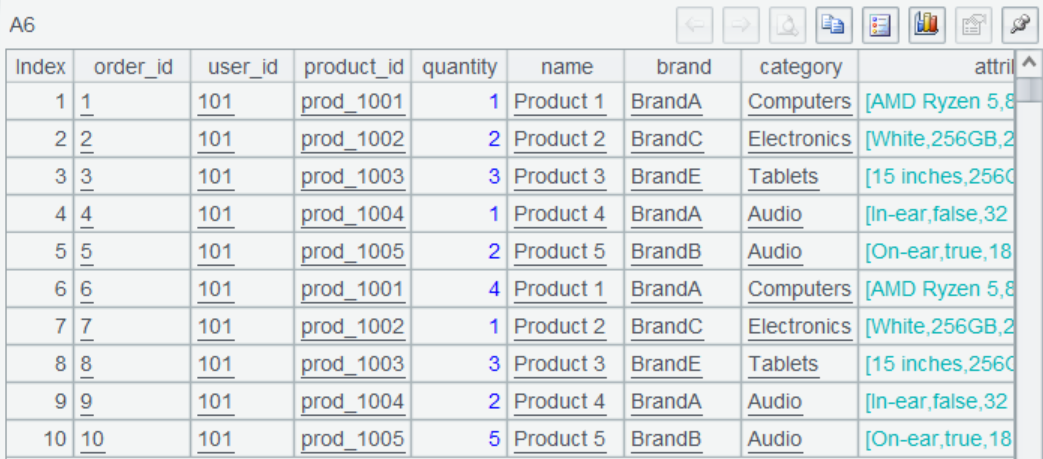
最后在 A7 根据条件筛选符合的数据并为报表返回查询的结果集。至此,kafka 与 MongoDB 的混合查询报表也完成了。
大数据支持
报表查询还可能涉及较大数据量,这时都全量读取会很慢,甚至可能导致内存溢出。SPL 提供了游标机制将数据以流的形式逐步读出。
我们改一下前面 MySQL 和 MongoDB 混算的例子:
A |
|
1 |
=connect("mysql") |
2 |
=A1.cursor@x("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date >= CURDATE() - INTERVAL 1 MONTH ORDER BY oi.product_id ASC") |
3 |
=mongo_open("mongodb://127.0.0.1:27017/raqdb") |
4 |
=mongo_shell@dc(A3,"{'find':'products','filter': {},'sort': {'product_id': 1}}") |
5 |
=joinx(A2:o,product_id;A4:p,product_id) |
6 |
=A5.groups(p.category;sum(o.price*o.quantity):amount) |
7 |
return A6 |
A2 将原来的 query 改成 cursor,即返回游标,结果是一个游标对象,此时数据还并未真正读取。

A4 使用 @c 选项,意味着查询的 MongoDB 数据也返回游标,结果同样是游标对象。
A5 使用 joinx 函数将两个游标进行关联,使用该函数要求两个游标对关联字段有序,所以在 A2 的 SQL 和 A4 的 MongoDB 命令中都进行了排序。
A5 的关联结果仍然是游标,如果使用 fetch 取数可以看到真实结果是一个多层序表。
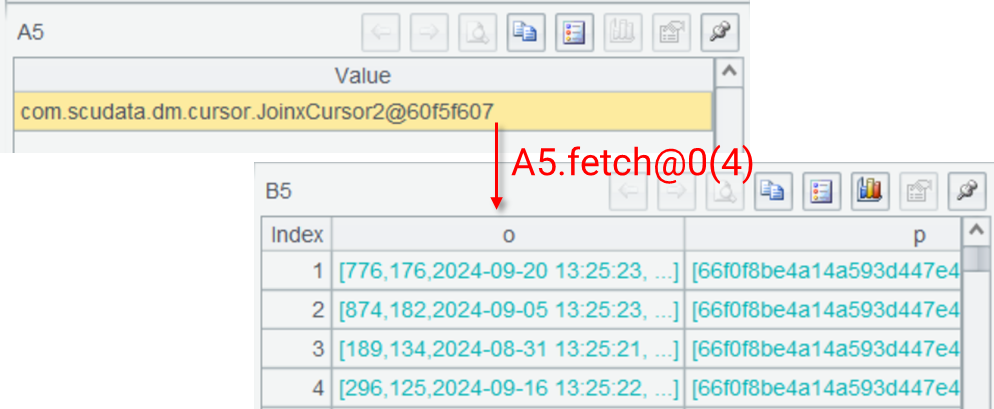
A6 按照分类进行汇总,得到计算结果。直到此时所有游标才真正开始取数计算。
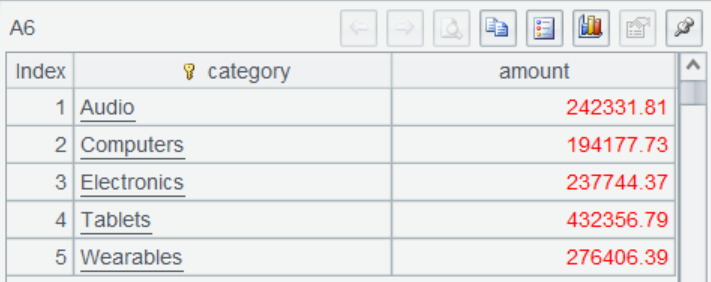
A7 为报表返回计算后结果。几乎所有数据源都可以使用 SPL 游标来应对大数据查询报表。
与报表应用结合使用
下面看一下如何在报表应用中使用 SPL。
应用集成
SPL 与报表应用集成非常简单,只要将 SPL 的 esproc-bin-xxxx.jar 和 icu4j-60.3.jar 两个 jar 包引入到应用中(一般在 [安装目录]\esProc\lib 下),然后复制 raqsoftConfig.xml(也在上述路径下)到应用的类路径下即可。
raqsoftConfig.xml 是 SPL 的核心配置文件,名称不可更改。
在 raqsoftConfig.xml 中,需要配置外部库,使用到哪个配置哪个即可。比如这里用到的 MongoDB 和 Kafka:
<importLibs>
<lib>KafkaCli</lib>
<lib>MongoCli</lib>
</importLibs>
同时 MySQL 数据源也需要配置在这里,在 DB 节点下配置连接信息:
<DB name="mysql">
<property name="url" value="jdbc:mysql://127.0.0.1:3306/raqdb?useCursorFetch=true"/>
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="type" value="10"/>
<property name="user" value="root"/>
<property name="password" value="root"/>
<property name="batchSize" value="0"/>
<property name="autoConnect" value="false"/>
<property name="useSchema" value="false"/>
<property name="addTilde" value="false"/>
<property name="caseSentence" value="false"/>
</DB>
报表访问 SPL
SPL 封装了标准 JDBC 接口,报表可以通过配置 JDBC 数据源来访问 SPL。 比如,在报表数据源处进行如下配置:
<Context>
<Resource name="jdbc/esproc"
auth="Container"
type="javax.sql.DataSource"
maxTotal="100"
maxIdle="30"
maxWaitMillis="10000"
username=""
password=" "
driverClassName=" com.esproc.jdbc.InternalDriver "
url=" jdbc:esproc:local:// "/>
</Context>
标准 JDBC,与普通数据库无异,这里不赘述。
然后在报表数据集中,使用访问存储过程的方式调用 SPL 脚本即可获得 SPL 的计算结果。调用前面计算订单汇总的脚本 orderAmount.splx:
call orderAmount()
调用带参数的订单查询脚本 orderConsumer.splx:
call orderConsumer(?)
其中,? 代表指定的商品类别参数,参数值由报表查询时指定。
这里我们仅演示了部分数据源间的混合计算,SPL 支持的数据源很多,而且还能扩展。
由于提供了统一数据对象,只要 SPL 能访问到,就都能混合计算,非常简单,这样报表就可以获得实时数据混合查询的能力,快速实现多源、T+0 报表。


英文版