


这可能是交互性最强的数据分析编程语言
强计算和交互性的两难
Excel 和 BI 是常用的数据分析工具,很适合完成初级的数据分析任务,比如统计各月销售总额,计算各组的平均订单金额和购买频次等。但随着业务需求升级,更复杂的任务用 Excel 或 BI 就很难完成了,比如要找出股票连续上涨 5 天以上的区间;求每 7 天中连续 3 天活跃的用户数;统计每个用户从“注册”到“首次购买”间隔 3 天、7 天、30 天等不同时间段内的用户数分布。这些任务通常涉及跨行数据、复杂分组、滑动窗口或条件判断,用 Excel 很难做,BI 更是没戏,这时就只能指望编程了。
然而,编程语言虽然有更强的运算能力,但交互性却远不如 Excel 和 BI。在 Excel 中每编写或修改一个公式,结果都能实时呈现,有新想法可以立即修改再观察。这样,分析师可以根据前一步的结果决定下一步的动作,逐步探索分析,但编程语言通常却缺少这样的结果反馈机制。如果都是简单语句,SQL 可以每次生成中间表来查询结果,但这种任务 Excel 做起来更方便,期望用编程实现的运算经常会较复杂,写出的 SQL 常常嵌套多层,子查询还不能独立运行,想看中间结果就非常费劲了;Python 在分步方面略好一点,但也要主动 print 输出,而且代码要整体运行才有结果。这些编程语言在交互方面的方便程度都远远不如 Excel,不能像 Excel 那样随时想看哪里看哪里。
交互性和强计算似乎不可兼得,享受交互性就要容忍弱计算能力,想要强计算能力就没法兼顾交互性。这是很多数据分析场景面临的两难。
SPL 解决之道
SPL 可以很好解决这个问题。SPL(Structured Process Language)是一门特别适合数据分析的编程语言,在具备强计算能力的同时也拥有堪比 Excel 等界面工具的交互性。
交互能力
SPL 采用网格式编程,代码写在格子里,这与大多数文本编程语言有很大不同。
这是 SPL 的 IDE 整体外观和特点: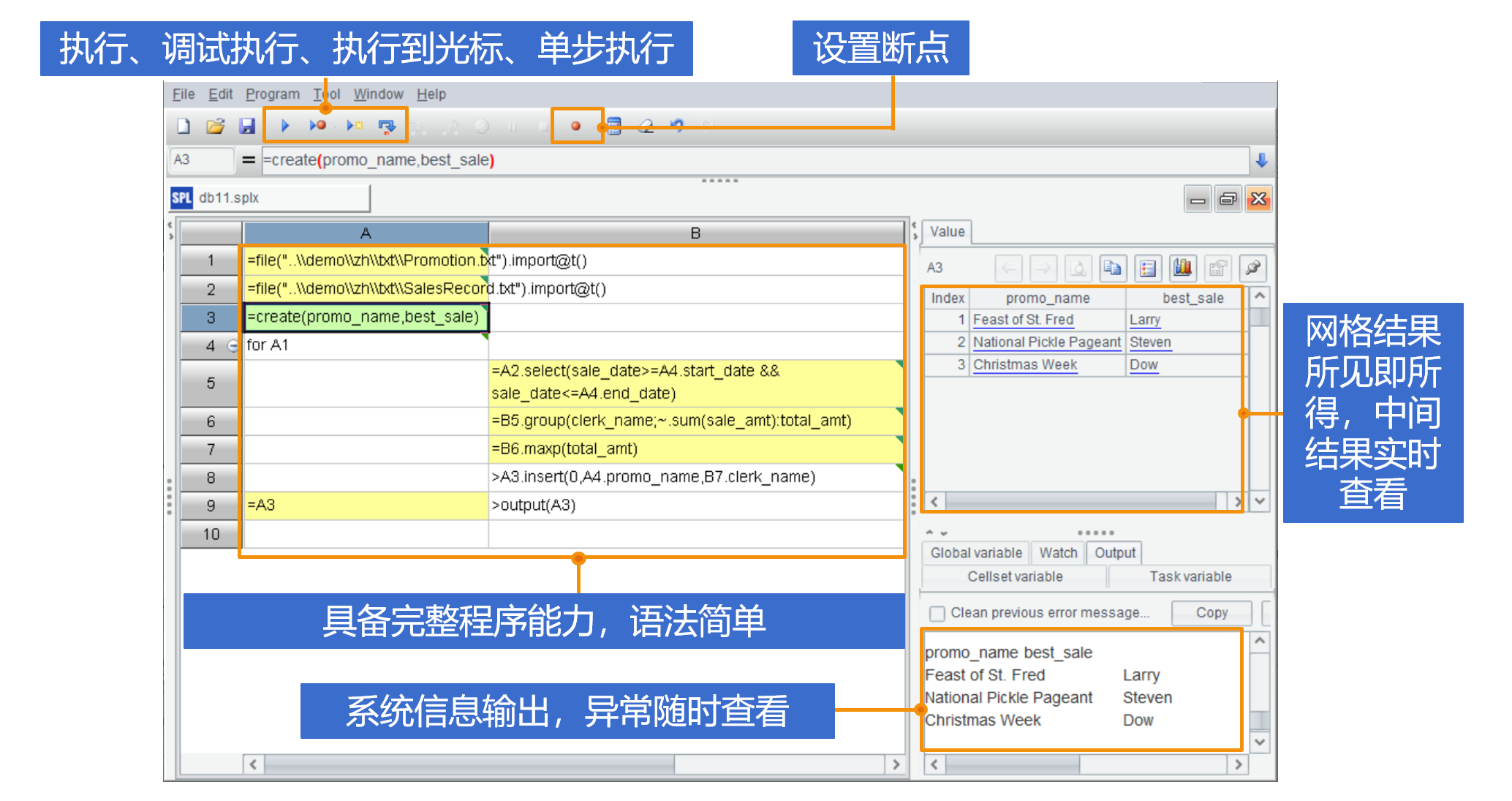
网格代码带来一大好处在于,可以像 Excel 一样用单元格承载计算结果。多个步骤落在不同格子里,每个格子的计算结果实时查看,像 Excel 一样想看哪里看哪里。后面的格子也可以像 Excel 一样通过单元格名(如 A1、B2)来引用前面格子的计算结果,非常方便且直观。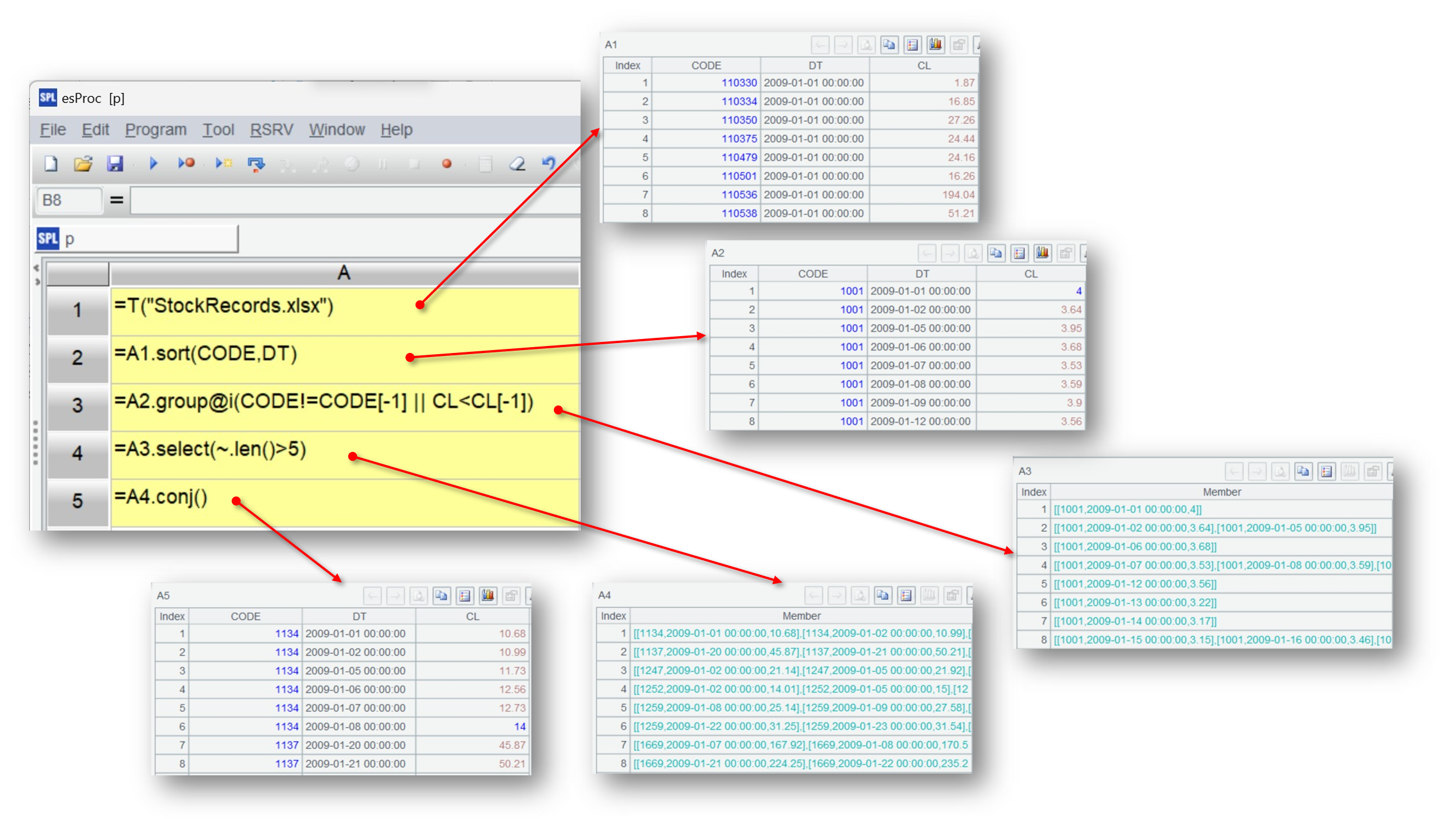
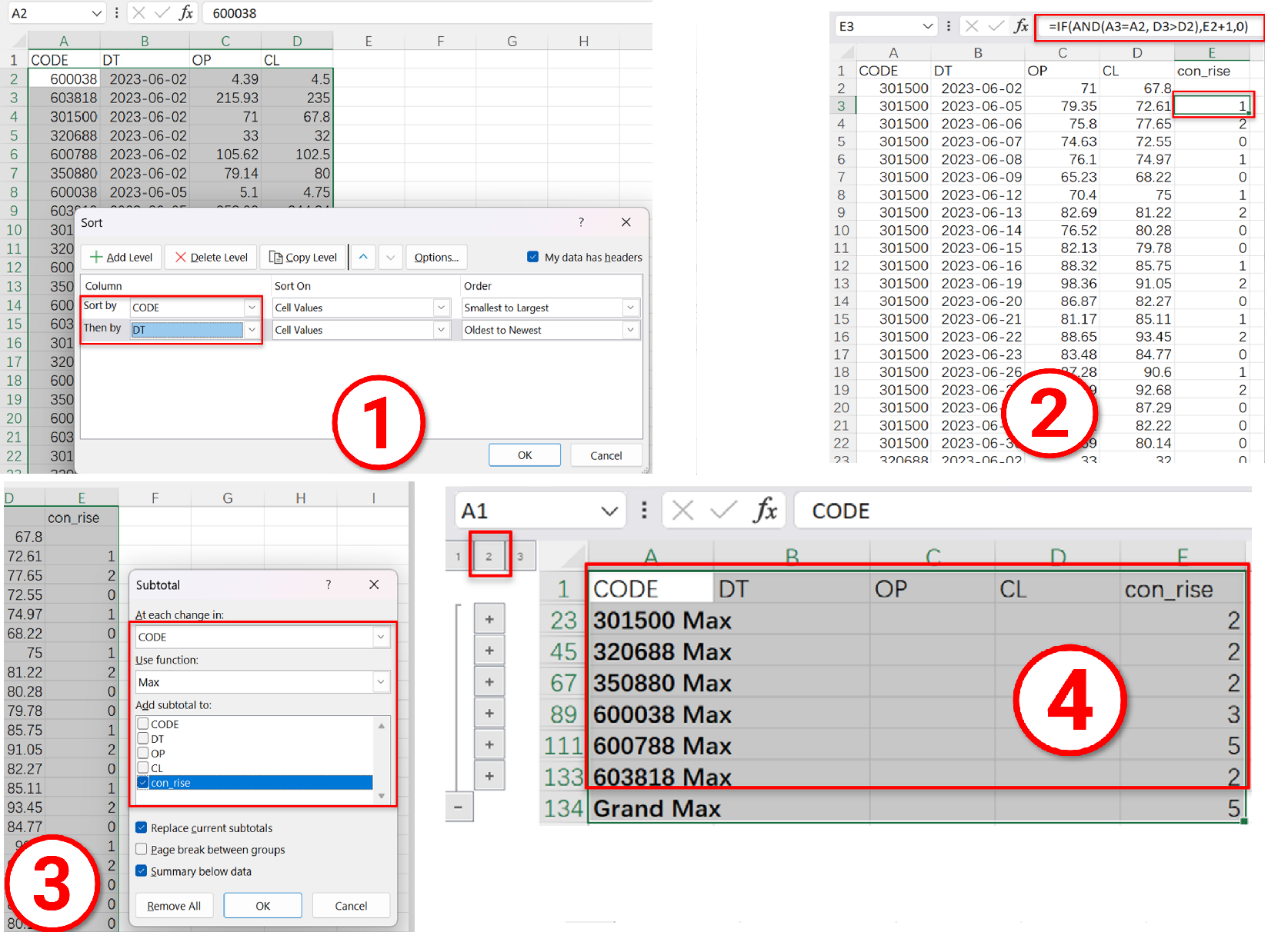
计算股票连续上涨 5 天以上的区间
代码写在像 Excel 的格子里,每个格子的计算结果实时查看;通过格名引用计算结果
我们来解释这段代码,细致地感受一下 SPL 的交互性。
在 A1 中使用 T 函数读入股票交易记录: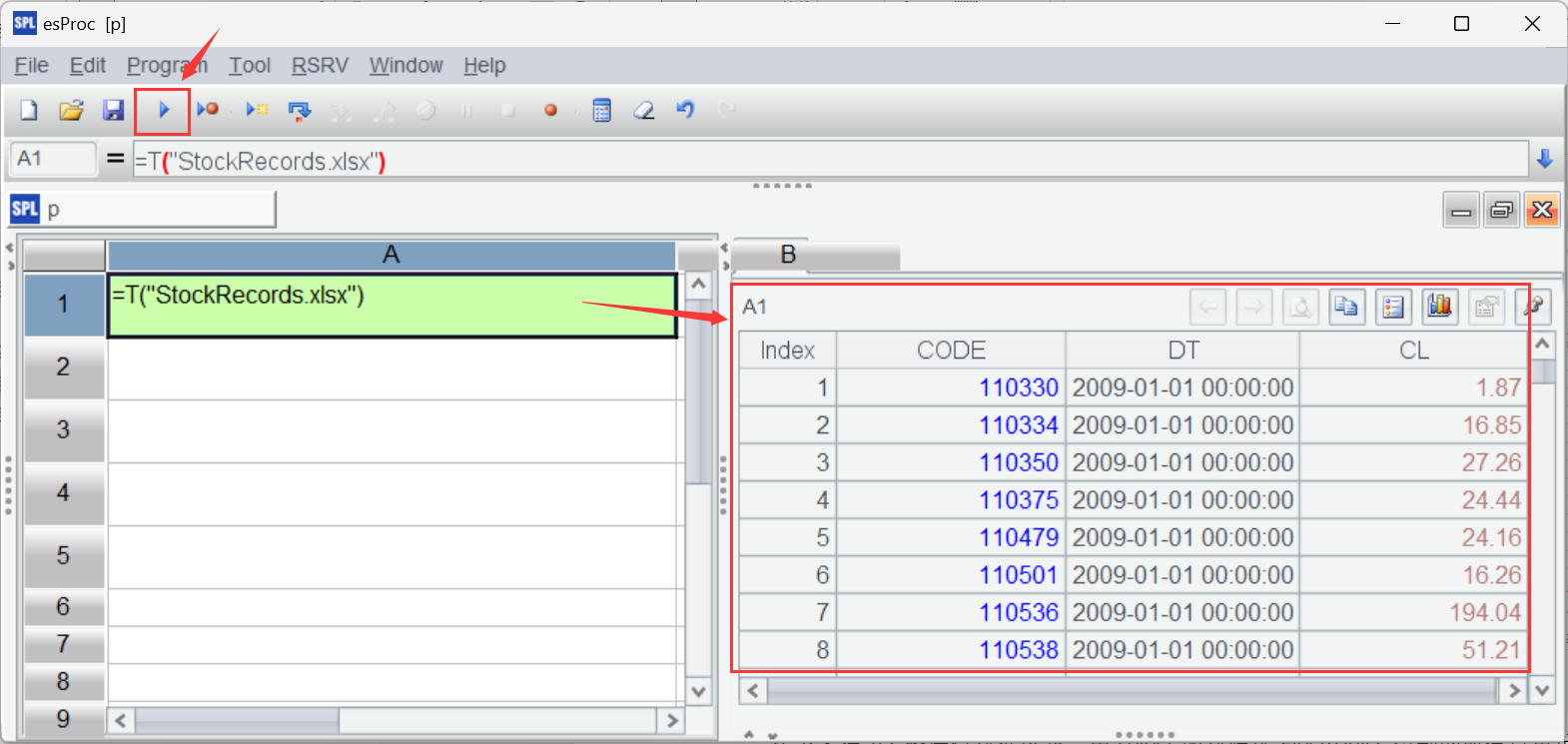
点击工具栏上的执行(三角图标)按钮,在右侧结果面板就能看到读入的数据。数据分析师可以实时查看运行结果,这个面板是 SPL 与分析师交互的重要窗口。
接下来在 A2 格按照股票代码 CODE 和交易日期 DT 排序,同样点击执行后在右侧可以看到排序后的结果。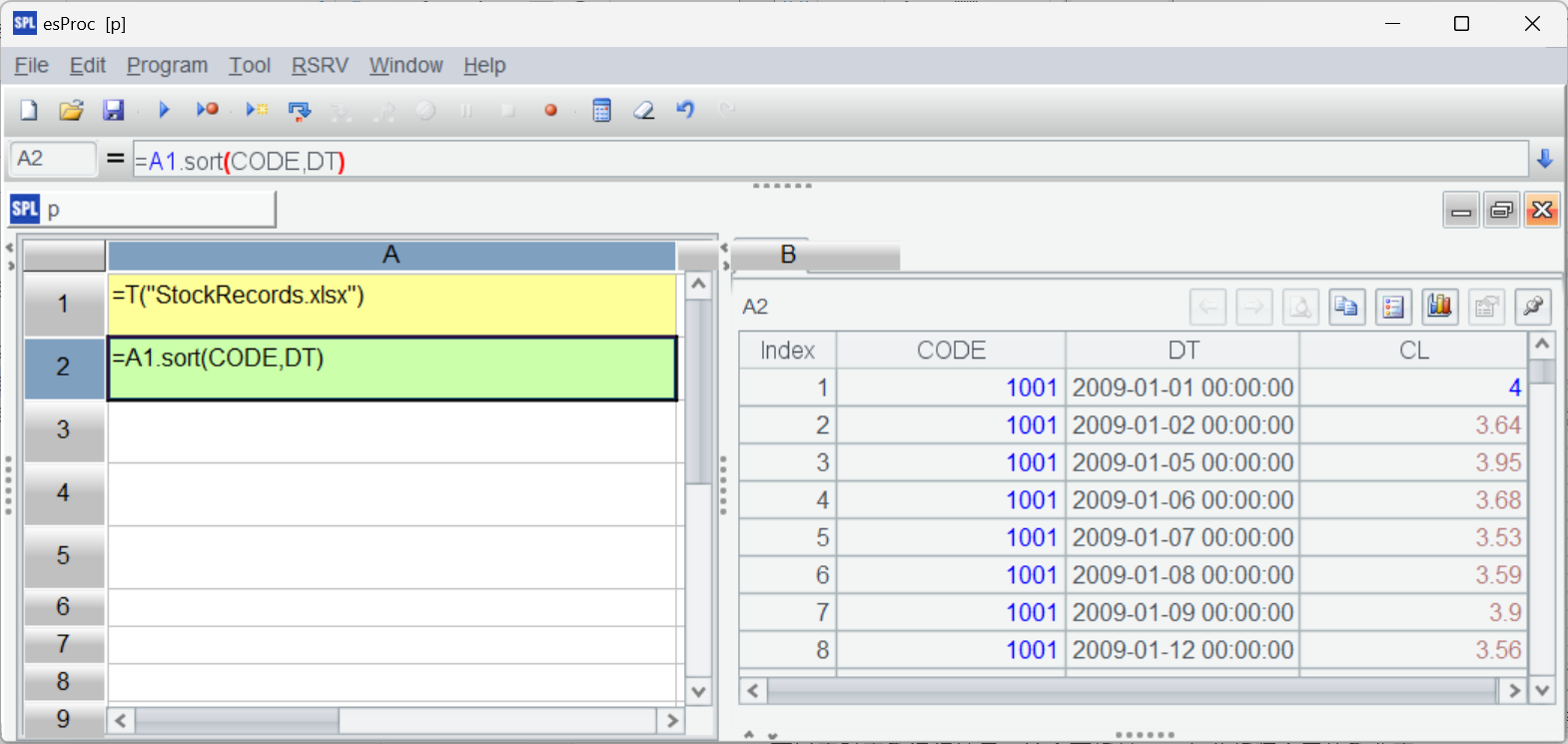
然后按照条件分组,将 CODE 相同且收盘价 CL 大于上一日的数据分到一组,group 的 @i 选项表示满足条件将产生新的分组。代码中的 CODE[-1] 和 CL[-1[ 表示对上一行的引用,这是 SPL 特有的语法,可以很方便地实现有序计算。而且,SPL 的分组可以保持分组子集,即分组的结果是由分组子集构成的集合,这也是许多程序语言不具备的能力。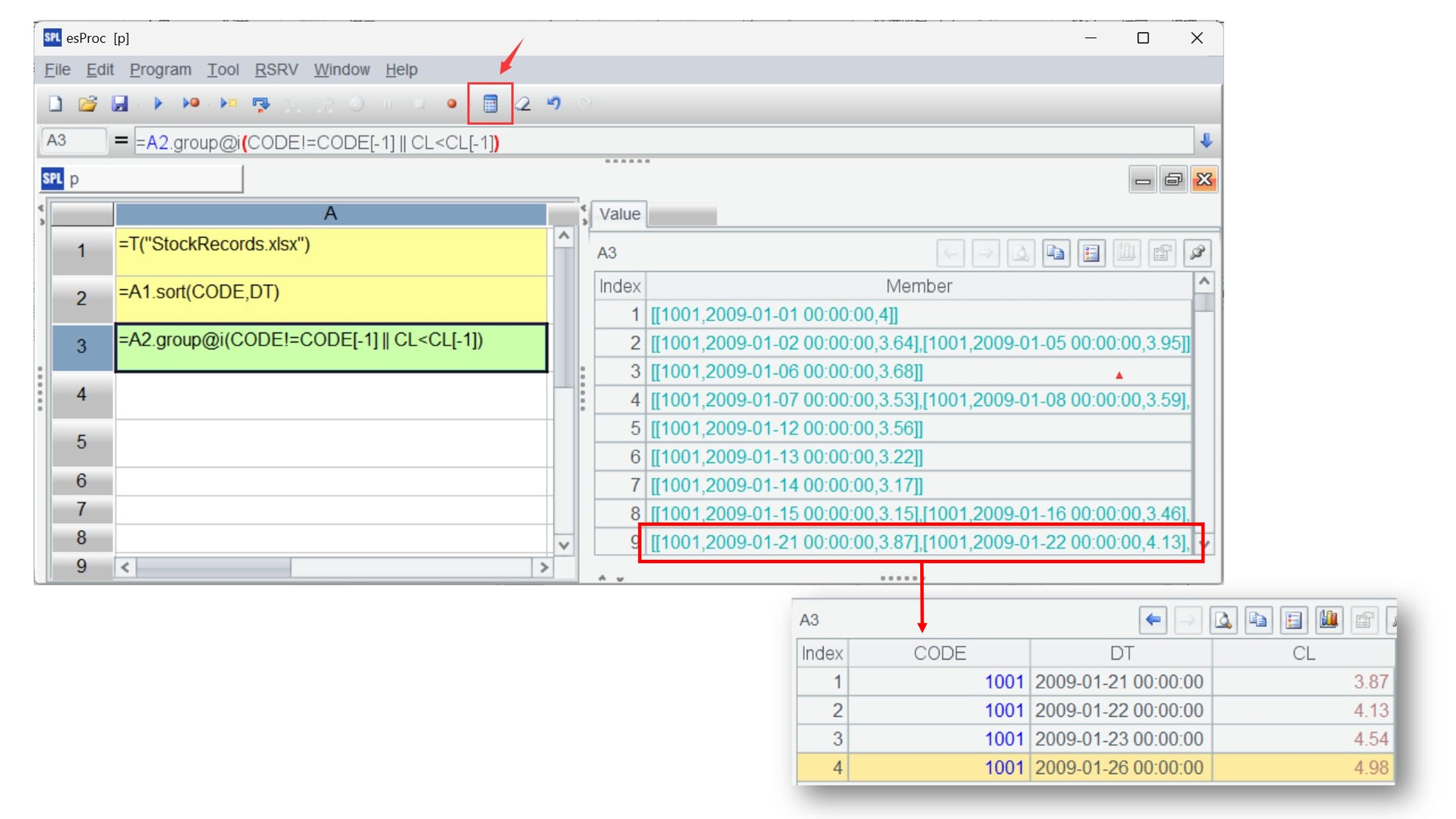
使用“计算当前格”在当前环境下计算
点击其中一个分组子集,可以看到构成这个子集的成员
前面执行过的代码已经有了结果,不必再重复执行,否则步骤较多或者数据量较大时执行慢会浪费时间。这时可以使用“计算当前格”功能。点击工具栏上的计算器图标就可以只计算当前格,在右侧即可看到计算结果。
相比之下,SQL 连分步的能力都没有,自然享受不到这样的便利;而 Python 也要整体执行,不能单独执行某一步,交互便利性远不如 SPL。
接下来用 select 函数筛选符合条件(连续上涨 5 天)的区间: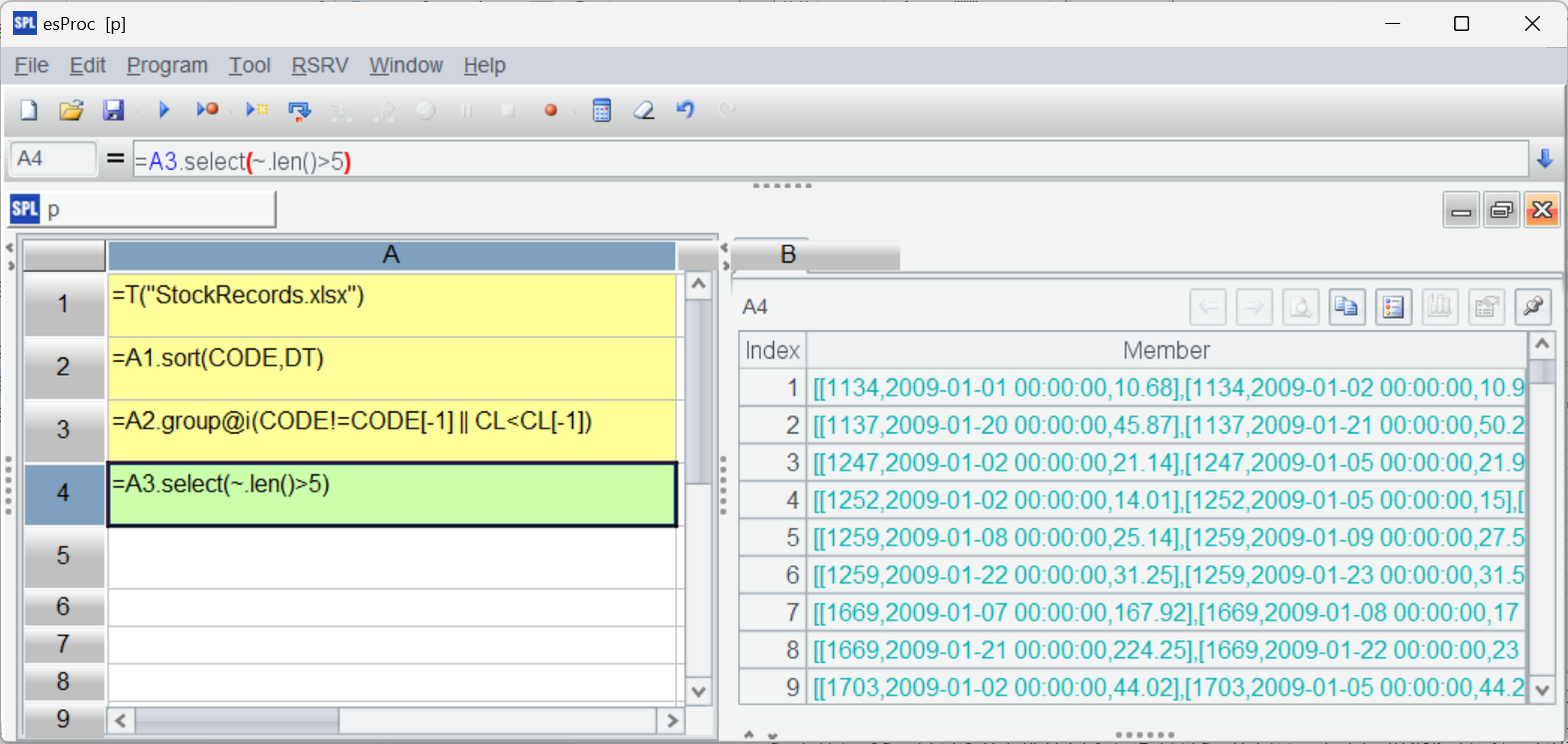
因为保持了分组子集,过滤条件直接用子集成员数大于 5 就能实现目标。
最后把所有符合的结果整合到一起: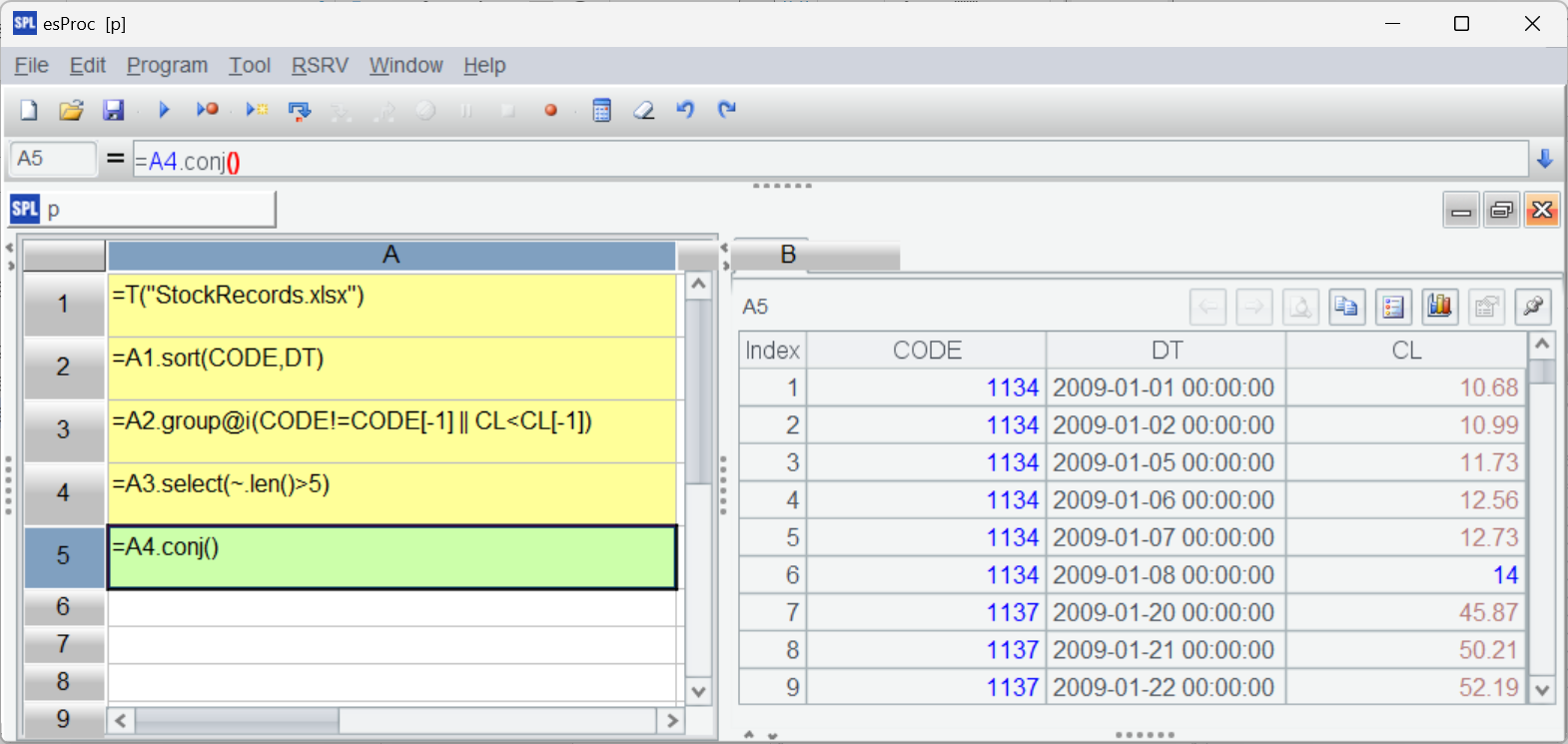
Excel 计算出连续上涨的天数并不难,但也没有保持分组子集的方法,更不能进一步筛选出相应区间,所以难以完成这个任务。这时只能人工肉眼筛选了,数据较多时显然不太现实。SPL 拥有比 Excel 更方便的计算能力,在这个任务中也可见一斑。
这时如果发现目标结果较多,想要改变筛选条件,比如查看连涨 10 天的区间。只要将 A4 中的筛选条件大于 5 改成 10,再使用“计算单元格”功能就可以了: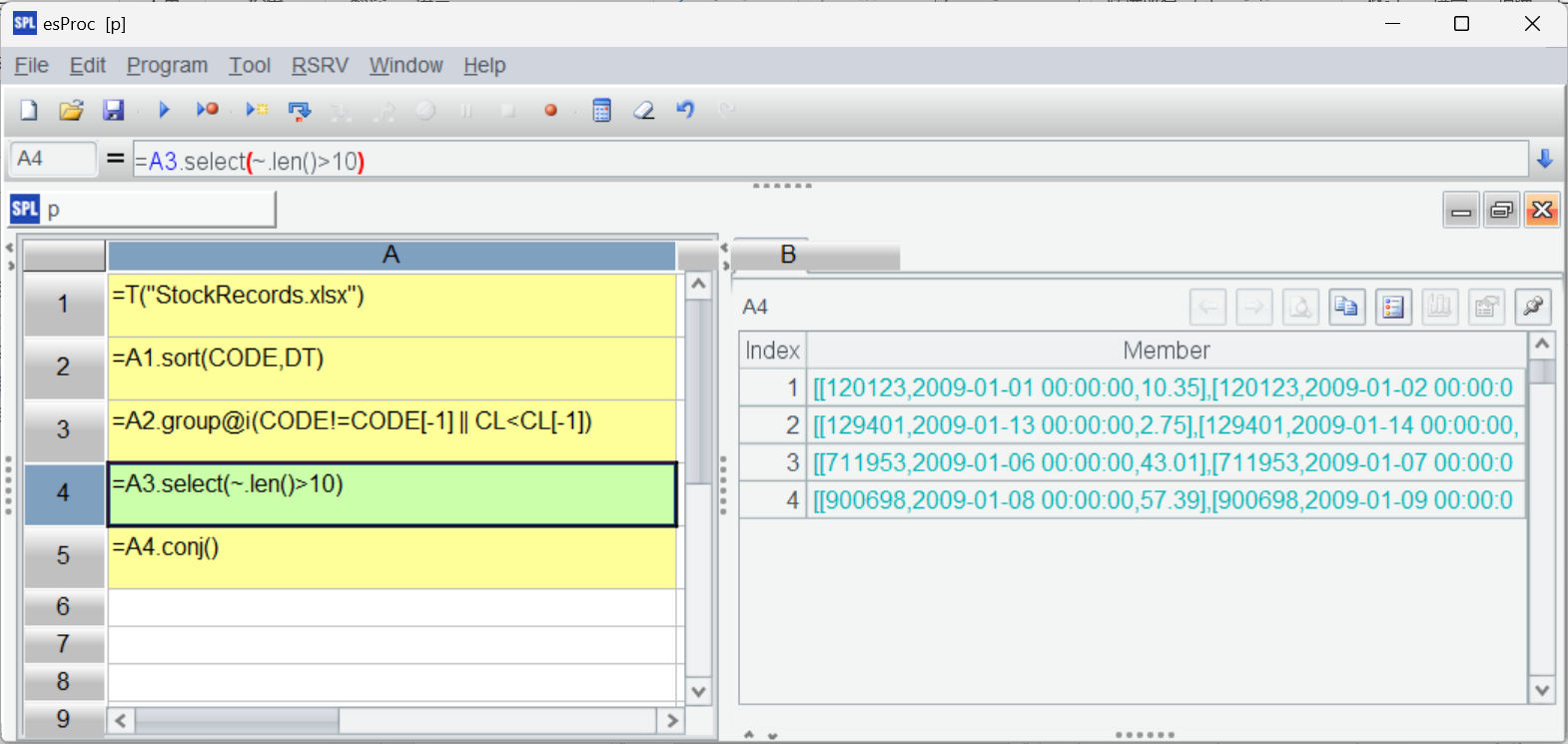
如果还不满意,则可以继续调整,“观察 - 调整 - 反馈”逐步完成分析任务。
从这个过程可以看出,SPL 作为一种程序语言,却具备了与 Excel 相当的交互能力。探索分析过程中写的代码都留在格子,必要时还可以重复执行(比如更换了源数据)。
程序能力
作为编程语言,SPL 提供所有程序语言都具备的循环、分支流程,提供丰富的计算类库和数据对象。上面计算连涨区间的示例过程中就运用了 SPL 的有序和集合相关运算,在强计算能力的支持下,可以很轻松完成各类复杂的数据分析任务。
相比之下,SQL 和 Python 这方面要更弱,这个连涨区间的任务用 SQL 就很难写出来,Python 也不容易。为了写出代码对比,我们把问题简化成计算每只股票最长连续上涨天数。
SQL:
SELECT CODE, MAX(con_rise) AS longest_up_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT,
SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE
嵌套多层,看懂都不容易,专业程序员都未必写得出。
Python:
import pandas as pd
stock_file = "StockRecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['CODE','DT'],inplace=True)
stock_group = stock_info.groupby(by='CODE')
stock_info['label'] = stock_info.groupby('CODE')['CL'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('CODE'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.DataFrame(list(max_increase_days.items()), columns=['CODE', 'max_increase_days'])
比 SQL 要容易些,但还是要硬写循环,仍不简单。
有了强大有序和集合运算的 SPL 只要三行搞定:
A |
|
1 |
StockRecords.xlsx |
2 |
=T(A1).sort(DT) |
3 |
=A2.group(CODE;~.group@i(CL<CL[-1]).max(~.len()):max_increase_days) |
从这个例子上看,SQL 和 Python 针对很多分析任务时表现出来计算方便度还不如 Excel。
总结一下,SPL 就像是插上了编程语言翅膀的 Excel,完美结合了 Excel 和编程语言在数据分析方面的优点,交互性与编程能力强强联合,助力数据分析师。


英文版