


一文读懂数据挖掘预测
什么是数据挖掘?
人们总是希望能预测未来,比如预测明天的天气,预测某地区的房价,预测下个季度的销量,预测客户的购买喜好等等。
那么,我们到底有没有办法做预测呢?
举个例子。
傍晚,路面上沁出微雨后的湿润,和煦的西风吹来,抬头看看天边的晚霞。
嗯,明天又是一个好天气。
走到水果摊旁,挑了个根蒂蜷缩,敲起来声音浊响的青绿西瓜,心里期待着享受这个好瓜。
我们由微湿路面感到微风,看到晚霞,根据经验,预测出明天是个好天气。
色泽青绿,根蒂蜷缩,敲声浊响,还是根据经验,预测出西瓜是个好瓜。
这两个预测都是根据以往的经验做出的。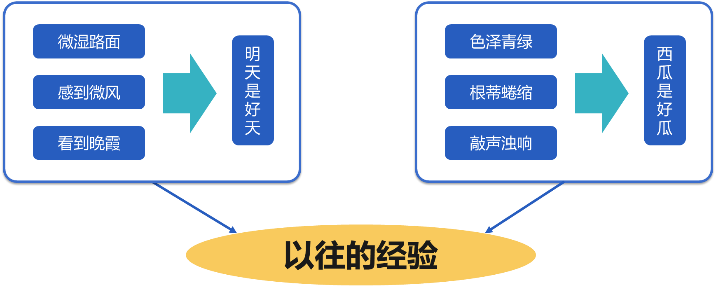
用数学语言来讲,预测的本质就是找到一个可计算的函数,能够用可以观察到的信息作为输入,计算出期望的预测结果作为输出。
挑西瓜的例子中,瓜的色泽,根蒂和敲声是可以观察到的信息,是输入值。而这个瓜的好坏,就是我们期望预测的结果。有了这样的函数,就可以做预测了。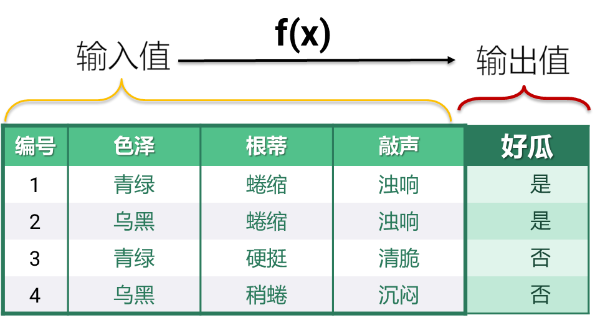
拿到一个新瓜,观察它的色泽,根蒂和敲声,代入函数计算一下,就能得到预测结果。
这个函数,我们就称为一个预测模型,也简称模型。
那么,这个函数是怎么找出来的呢?
想想如果让一个人拥有判断好瓜坏瓜的能力,应该怎么做?
肯定需要拿一些瓜来练习。
先观察剖开前的特征,即色泽根蒂等,然后再剖开看它的好坏,久而久之,你就能用瓜的外部特征来预测瓜的好坏了。
朴素地想,用来练习的瓜越多,以后的预测也会越准确。
每次练习,都有一套输入值,瓜的色泽根蒂等,也会有一个输出值,好瓜还是坏瓜。
多次练习,就会积累出很多套输入输出值,而这,就是历史数据。
用来做预测的函数就是用历史数据找出来的。
再用专业的术语来说一遍。
用来预测的函数,我们也叫模型。
模型输入值的学名叫做特征变量,一般用 x 表示。特征变量常常有多个,呈现为一个多列的表,每一列都是一个特征变量。比如西瓜例子中的色泽,根蒂等。
模型输出值的学名叫做目标变量,通常用 Y 表示,比如这里的好瓜还是坏瓜。目标变量也可以拼到特征变量表上,这就是历史数据的一般形式。
找到模型的过程,就是建模。碰到新情况用这个模型来计算,就是预测。
整套技术叫做数据挖掘,顾名思义,就是从数据中挖掘出某些有价值的东西,也就是模型。
需要注意的是模型通常不能做到 100% 准确,再有经验的瓜农也不能保证每次都挑出好瓜,天气预报也不是次次都准。模型都会有一个准确率,只要准确率足够高,仍然有应用价值。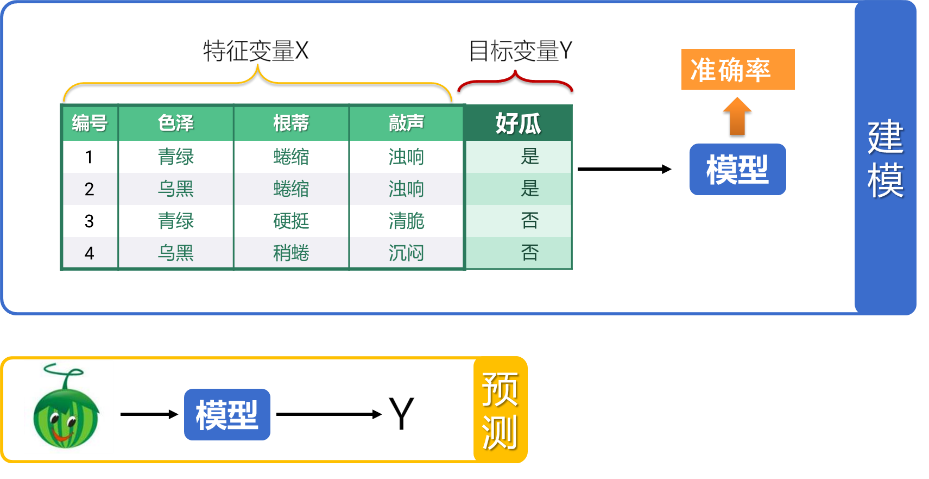
数据挖掘包含哪些工作
那么,到底怎样利用历史数据找到模型呢?
这就要讲到数据挖掘的算法了。
比如有一组房屋面积和其销售价格的数据。房屋面积为特征变量 x,价格是目标变量 y。我们希望用房屋面积来预测价格 。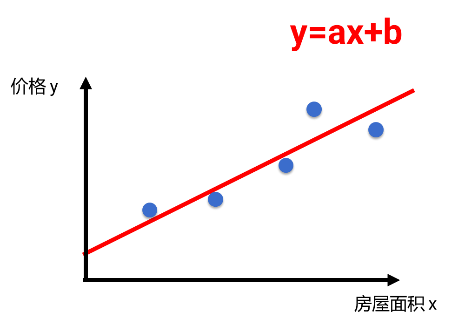
观察会发现,随着房屋面积的增大,价格大体呈线性趋势上升,于是我们猜测 x, y 之间就是线性关系。
然后,利用数学中的线性拟合方法,计算出一条直线 y=ax+b,就可以近似描述这组 x,y 的关系,也就是能从 x 近似地计算出 y,相当于找到了模型。
这就是一种数据挖掘算法,叫做线性回归,它可以用于 x,y 都是数值时的建模。
挑西瓜的问题不是两组数值之间的关系,线性回归算法就不适用了,这时候有可能用到决策树算法。
决策树的原理和线性回归完全不同,它可以看成是一个树状结构 if-then 规则的集合。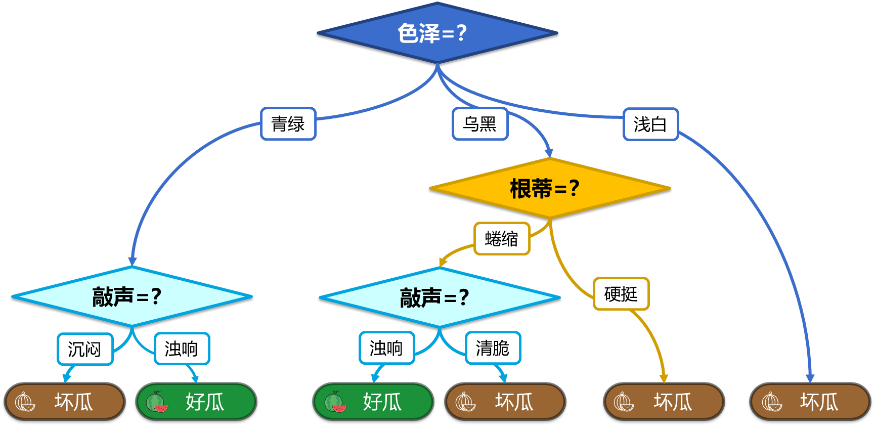
即由决策树的根节点到叶节点的每一条路径构建一条规则,路径上内部节点的特征对应着规则的条件,而叶节点的类对应于规则的结论。
使用历史数据可以逐步把整个决策树构建出来,也就是建模。
即使是两组数值之间的关系,也不一定总能用线性回归算法。
比如另一组房屋面积和其销售价格的数据。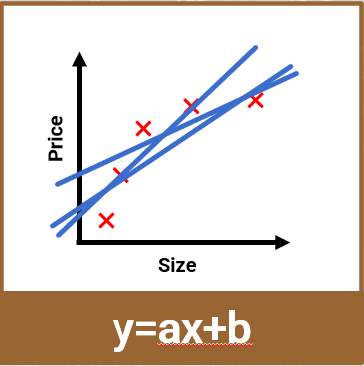
由图中可以看出在这组数据中,随着房屋面积的增大,价格也在上升,但明显不是线性趋势,这时候再用线性回归来计算,就会发现无论怎样选择直线,拟合效果都不太好。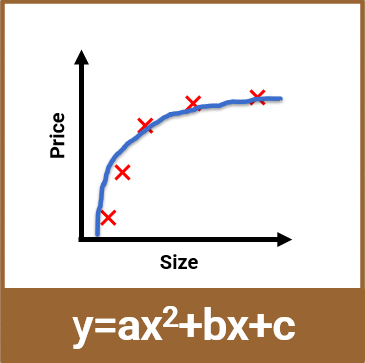
如果改变一下算法,增加非线性因素,比如用二次函数,就可以拟合的很好了。
所以,即使是相同的问题,也可能会用不同的算法。
数据挖掘也确实有很多种算法,比如 lasso 回归,逻辑回归,支持向量机,决策树,随机森林等等。
每种算法都有自己的数学原理,也有一定的适用性,不同的问题需要不同的算法。
包括现在很火的 AI 大模型,本质上也是一种预测模型,它是在预测一句话中下一个词出现的概率,选择概率较高的词输出。所以说数据挖掘是 AI 的前世。
大模型采用的算法叫做神经网络,这种算法很复杂,由一层层数学函数构成的节点关联起来。它的规模很大,建模时需要海量的历史数据。
这些算法是数据挖掘的核心,需要很多数学知识才能熟练掌握,比如要理解回归算法,就要懂最小二乘法,梯度下降,多重共线性等等。每种算法还有很多参数,不懂其中的数学原理就不知道怎么样去做。
而且,这还不够,历史数据通常不能直接使用,还要先做预处理
预处理的方法也有很多,比如补缺失值,做数据纠偏,降基数,标准化,离散化,数据平滑等。而且每种也不简单,比如补缺失值就有十多种方法。这些都需要丰富的数学知识才能掌握。
建完模型,还要去测试,看看它和真实情况的误差有多大,这决定了模型能不能用来预测。
而且,建模过程不是一簇而就的。如果误差太大,也就是准确率太低,那就还要反复不断的调整。
所以,建一个可用的模型常常要几天甚至数周时间,大部分时间都是在不断地调整优化。并不是对着数据应用一下算法就完了。
当然这一切都还要利用计算机编程,如果你不是程序员,还要顺带学下编程。
好用的工具
数据挖掘建模是一件复杂度很高的事情,只有少数专业人员会做,这就是所谓的数据科学家。
显然,数据科学家并不容易培养出来,所以好的数据科学家很贵,是个非常有前景的职业。但同时优秀的数据科学家也很少,这也会制约数据挖掘技术的应用范围。
不过,近年来出现的数据挖掘自动建模工具,可以打破这个制约。
比如易明建模,它固化了建模所需的数学知识和顶级统计学家的丰富经验,不懂这些高深数学的人也可以一键建模。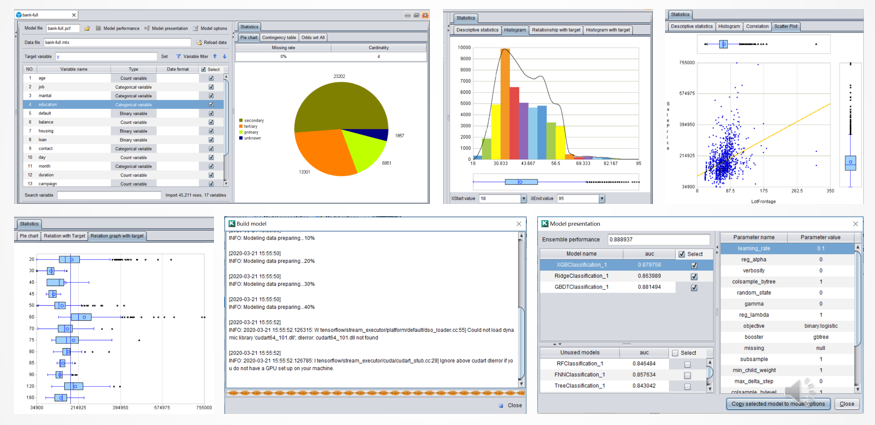
易明建模可以自动分析数据,并做好预处理,然后自动建模和调参。几分钟就能建好模型。它做的模型质量能够达到中上等数据科学家的水平,远比缺乏数学知识的程序员要好。
不过,即使有了自动建模工具,也不是简单把历史数据丢进去转一圈就行了。要建出好模型,还需要丰富的业务知识。
建模时常常要基于原始的特征变量产生一些新的特征变量,称为衍生变量。有了好的衍生变量,模型质量可能得到大幅提升。
比如有个特征变量是交易日期,如果从它衍生出节假日,那做商业预测时的效果会比使用原始的日期好得多,因为商业活动确实和节假日关系密切。
这个信息和业务相关,有更多从业经验的人能想到更多更准确的衍生变量,这并不需要数学知识。
相反,自动建模软件则是数学能力更强,能弥补用户在数学方面的不足,但没有也不可能有业务知识,不能替用户做依赖于业务经验的事情。
作为工具,需要支持用户添加衍生变量,比如易明建模就支持添加比率、交互、分箱、转换、日期时间相关等各种衍生变量。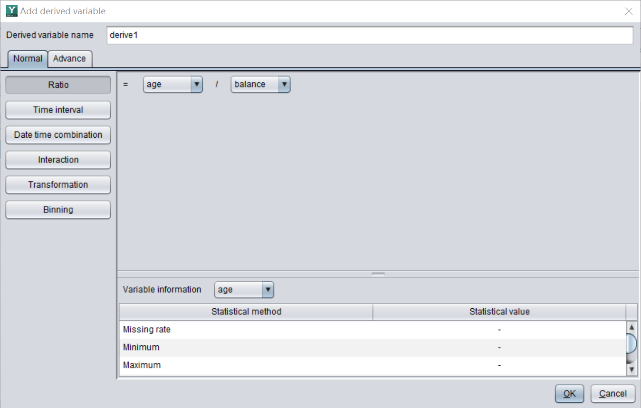
用来建模的历史数据量也要适中。和 AI 大模型不同,数据挖掘并不需要海量的数据,大概几万或几十万条就够了,太多的数据量并不会显著提高模型效果,但计算时间和成本则会大幅度增加。而太少的数据量,比如只有几条或几十条,则不足以找出数据中的规律。
从这个角度上看,数据挖掘技术的可操作性极强,大多数机构只要运营过几年都能积累出这种规模的数据,而且建模也不需要多大的算力,像易明建模处理这种规模的数据,使用普通 PC 机笔记本就可以了,完全不需要专业的服务器集群。
学会评估模型
另外,还要了解一些模型评估相关的知识,知道这个模型到底好不好。
一个基本的指标就是准确率了,它表示在所有预测结果中,有多大比例是预测正确的。
我们当然希望预测更准,所以通常也会选择准确率更高的模型。
不过,准确率并不是评判模型好坏的唯一指标。这是易明建模的界面,它可以自动计算出很多指标,比如精确率,查全率,AUC 等。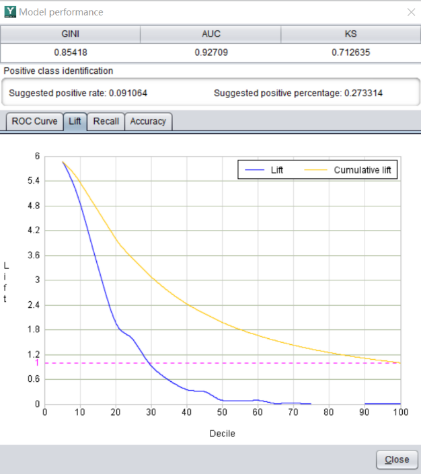
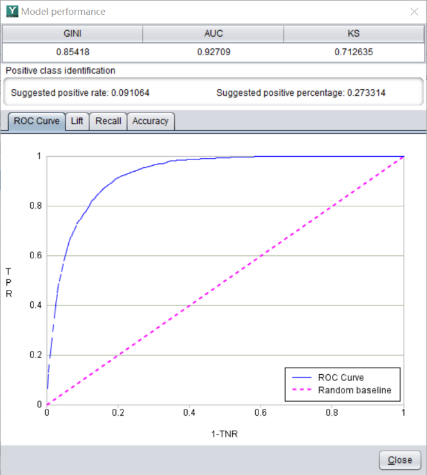
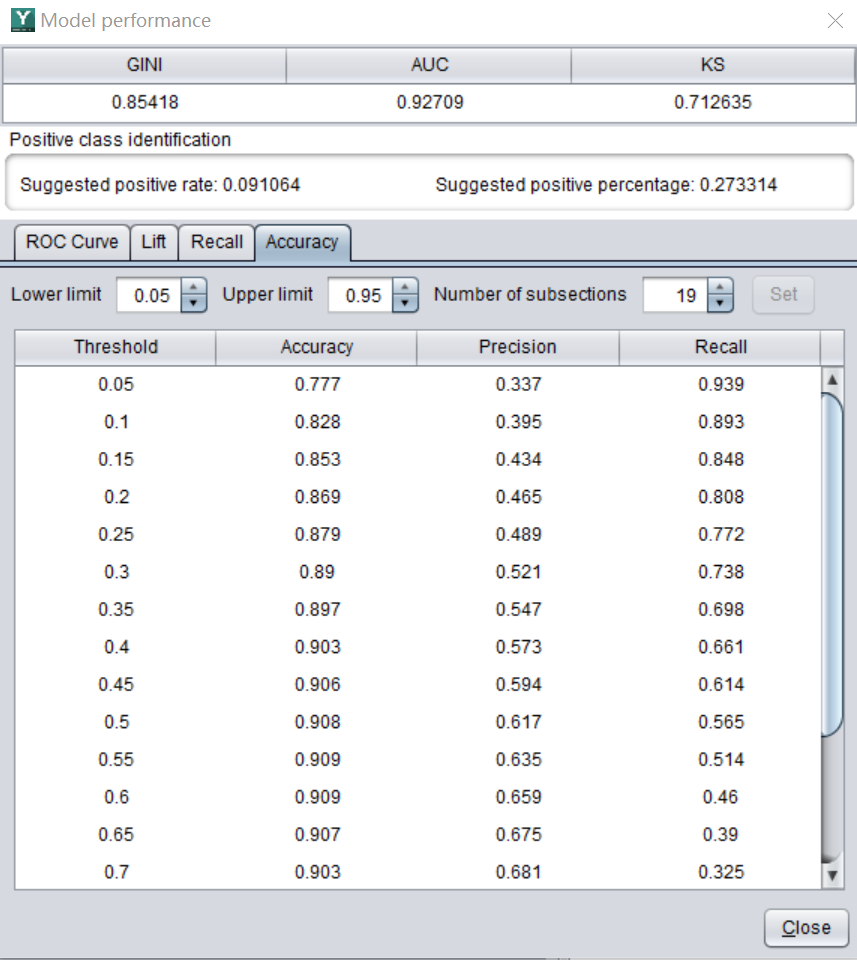
不同的指标有不同的含义。在不同的业务场景中,也会侧重不同的指标。
比如某企业希望销售 50 件产品,并且有一份潜在的客户名单。
如果随机找,大概要推销几百个客户,才能卖出去 50 件产品。
这时候,可以建立模型来选择待推销客户。
那些最终购买产品的客户,在数据挖掘的术语中称为正样本或者阳性样本,相反,那些不会购买产品的客户称为负样本或阴性样本。
要提高推销效率,我们会更关注模型在预测出的正样本中的准确率,因为我们只会对预测要购买的客户进行推销。而并不会关心它预测出的负样本中的准确率有多高,因为这批客户是会丢弃的。
这个指标叫做精确率。
精确率表示预测结果为正的样本中,有多少是真正的正样本。比如预测 100 个会购买该产品的客户中,实际上有 60 个真正的购买了,那么它的精确率就是 60%。
例如,模型 A 的精确率为 67%,准确率为 70%。
就说明在 A 模型预测会购买的客户中,实际有 67% 的人会真正地购买。因此不难推算出要卖出 50 件产品,只要向 75 个客户推销就能实现目标。工作效率有了大幅度提高。
再来看模型 B。
它准确率降低了,但是精确率提高了。使用模型 B,只要对 60 个客户推销,就能卖出 50 件产品。营销成本反而降低了。
因此,我们要学会用合适的指标来评估模型,并不是一味地追求准确率。
再比如,机场要建立模型来识别恐怖分子。假设在一百万人里面有五个是恐怖分子。
因为恐怖分子是极少数人,如果使用准确率来评估模型的话,那么只要把所有人都识别成正常人,模型的准确率就能高达 99.999%,比如模型 A。但显然这种模型并没有什么意义。这时候需要建立一个查全率比较高的模型。
查全率表示在实际的正样本中,有多少被正确预测了。也就是 5 个恐怖分子中,有多少个能被抓到。
比如模型 B,虽然准确率有些低,但是,查全率很高,它可以将全部的恐怖分子都识别出来。尽管可能会冤枉几个好人,但是总比被恐怖分子钻空子要好得多。这样的模型是有意义的。
不同的准确率和查全率,产生的影响完全不同。
在易明建模这样的工具里,可以自动算出一系列的准确率、精确率和查全率,用起来一目了然。
除了数值的指标可以用来评估模型效果外,还有一些图形也会用到。比如 lift 曲线。
它表示使用模型后效果会提升多少倍,也就是提升度。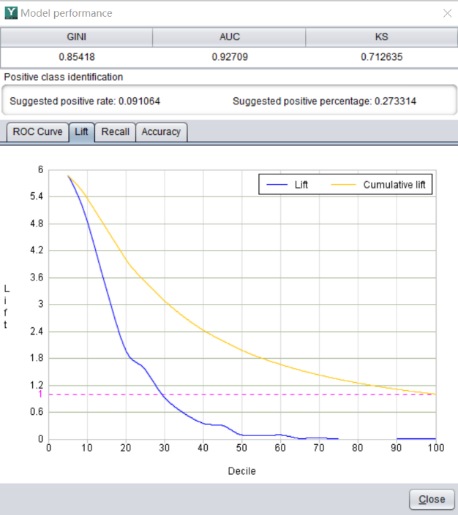
比如,在某产品的电话营销场景中,有一百万个潜在客户,客户的平均购买率为 1.5%,也就是说随机选取一百个客户,平均会有 1.5 个人购买该产品。
然后我们用易明建模针对该产品做了推销预测模型,提升度曲线如图中所示。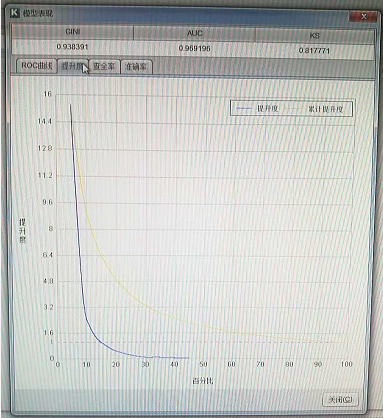
模型预测的成交概率最高的前 5% 客户的提升度为 14.4,也就是在前 5% 的客户中,平均每一百个人中会有 21.6 个人购买该产品。
这远远高于随机选取的 1.5 个人,从而大幅度提高了营销效率,减少了无效的推销动作。
查全率图也很有用,比如在风险理赔场景中。
下图是易明建模针对建出的理赔预测模型绘制的分析图,可以看到在三十多万的保单中,发生理赔的只有 1246 单,正样本比率仅为 0.4%。
保险公司在意的是如何从众多的保单中,快速的找到这些高风险客户,从而采取措施来降低理赔风险损失。
从易明建模绘制的查全率图中可以看到,从前 10% 的数据中就可以捕获 75% 的高风险客户。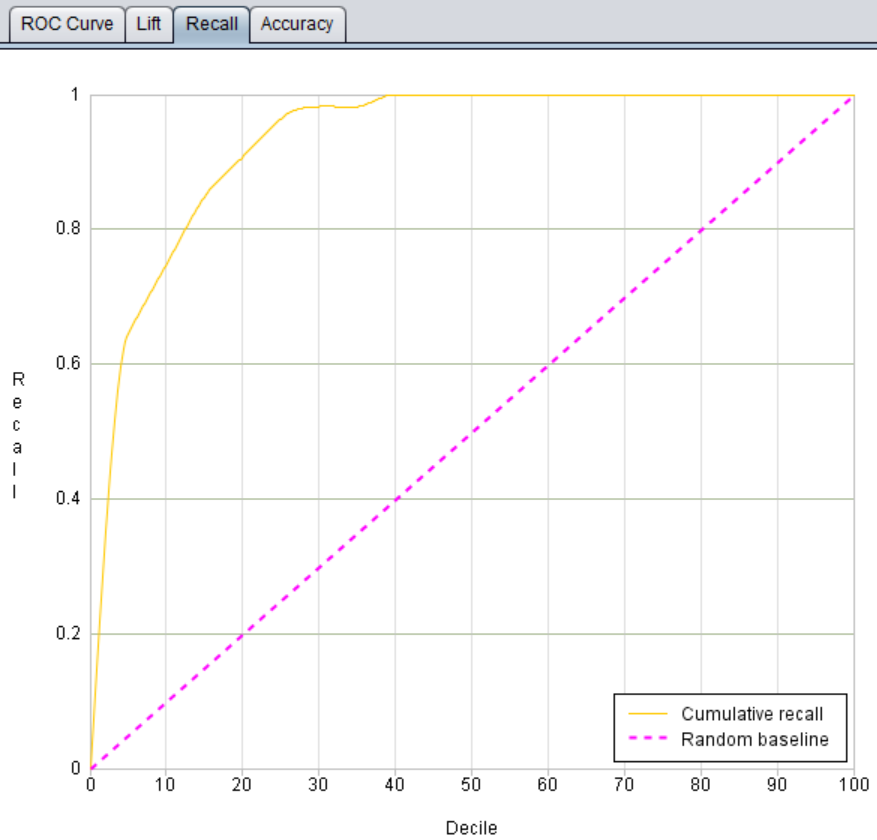
也就是说,在三十多万保单中,只需要筛选三万个保单,就可以抓到 75% 的高风险客户,大大提高了工作效率。
除了模型评估指标,在实际应用中还要考虑模型的稳定性。
比如前面房价预测的数据,有 3 个模型。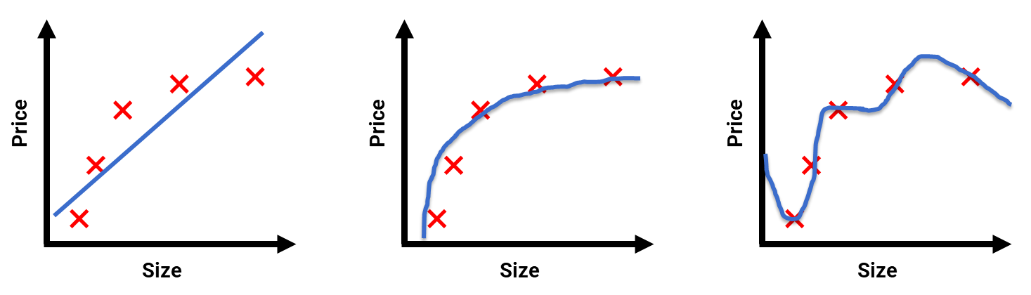
蓝色线条表示模型拟合出来的预测值。红色点则表示真实值。
很显然最右边的模型,准确率是最高的。
但是要知道,我们建模的目标不是为了描述历史,而是要预测未来。
我们更希望它在未知的数据上表现良好。用专业的术语来讲就是我们需要的是泛化能力比较好的模型。
第 3 个的模型虽然在历史数据上能够完美预测,但是并没有体现出数据的发展趋势,泛化能力较差。这种情况称为过拟合。
而第 1 张图拟合效果太差,称为欠拟合。
第 2 张图虽然准确率没那么高,但是泛化能力好,在预测数据上会表现比较稳定,是较为理想的模型。
过拟合是非常容易犯的错误,建模时要特别注意避免。统计学家们也有很多防止过拟合的办法,例如易明建模里就嵌入了很多统计学家的这类经验和办法,所以能比普通程序员做得更好。
数据挖掘是一项十分有用的 AI 技术,它可以帮助人们做各种各样的预测,赋予我们更强的洞察未来的能力。
随着技术的发展,自动建模技术也越来越成熟,借助像易明建模这样的自动建模工具,可以大幅度降低数据挖掘的门槛,使得非专业人士也能轻松应用数据挖掘技术,预测未来变得切实可行。


英文版