1.2 结构化数据
1.2.1 常数数据表
SPL
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | Rebecca | Male | 80 | 1.75 | 1974-11-20 |
| 2 | Ashley | Male | 60 | 1.68 | 1980-07-19 |
| 3 | Rachel | Female | 51 | 1.64 | 1970-12-17 |
| 4 | Emily | Female | 49 | 1.6 | 1985-03-07 |
| 5 | =create(name,gender,weight,height,birthday) | ||||
| 6 | =A5.record([A1:E4]) | ||||
SQL
CREATE TABLE emp (
name VARCHAR2(50),
gender VARCHAR2(10),
weight NUMBER(5,2),
height NUMBER(5,2),
birthday DATE);
INSERT INTO emp (name, gender, weight, height, birthday) VALUES ('Rebecca', 'Male', 80, 1.75,
TO_DATE('1974-11-20', 'YYYY-MM-DD'));
INSERT INTO emp (name, gender, weight, height, birthday) VALUES ('Ashley', 'Male', 60, 1.68,
TO_DATE('1980-07-19', 'YYYY-MM-DD'));
INSERT INTO emp (name, gender, weight, height, birthday) VALUES ('Rachel', 'Female', 51, 1.64,
TO_DATE('1970-12-17', 'YYYY-MM-DD'));
INSERT INTO emp (name, gender, weight, height, birthday) VALUES ('Emily', 'Female', 49, 1.6,
TO_DATE('1985-03-07', 'YYYY-MM-DD'));
Python
info = [["Rebecca","Male",80,1.75,"1974-11-20"],
["Ashley","Male",60,1.68,"1980-07-19"],
["Rachel","Female",51,1.64,"1970-12-17"],
["Emily","Female",49,1.6,"1985-03-07"]]
data = pd.DataFrame(info,columns=['name','gender','weight','height','birthday'])
1.2.2 成员取出
SPL
| A | |
|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc() |
| 2 | =A1(3) |
| 3 | =A1([2,6,5]) |
| 4 | =A1.to(2,4) |
| 5 | =A1.step(2,2) |
| 6 | =A1.m(-1) |
| 7 | =A1.m([1,3],5:7,-2) |
SQL
1. 取出第 3 个成员
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE rnum = 3;
2. 取出第 2,6,5 个成员
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE rnum IN (2,5,6)
ORDER BY CASE rnum WHEN 2 THEN 1 WHEN 6 THEN 2 WHEN 5 THEN 3 END;
3. 取出第 2 到 4 个的成员
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE rnum BETWEEN 2 AND 4;
4. 取出偶数位置成员
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE MOD(rnum,2)=0;
5. 取出最后一个成员
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE rnum=( SELECT COUNT(*)
FROM EMPLOYEE);
6. 取出第 1,3 个, 第 5 到 7 个, 倒数第 2 个成员
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE (rnum IN (1,3)) OR (rnum BETWEEN 5 AND 7) OR (rnum=(
SELECT COUNT(*)-1
FROM EMPLOYEE));
Python
emp = pd.read_csv('EMPLOYEE.csv')
result1 = emp.iloc[2]
result2 = emp.iloc[[1, 5, 4]]
result3 = emp.iloc[1:4]
result4 = emp.iloc[1::2]
result5 = emp.iloc[-1]
result6 = emp.iloc[[0, 2, *range(4, 7), -2]]
1.2.3 字段引用
1. 记录取出字段
2. 取出多个字段
3. 动态字段名取出字段
4. 按位置取出字段
5. 取出全部字段
6. 记录集合取出字段
SPL
| A | |
|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc() |
| 2 | =A1(1) |
| 3 | =A2.NAME |
| 4 | =A2.([NAME,GENDER]) |
| 5 | =A2.field(“NAME”) |
| 6 | =A2.([#2,#3]) |
| 7 | =A2.array() |
| 8 | =A1.(NAME) |
SQL
SQL 虽有记录这个概念,但记录并不能独立存在,只能以只有一条记录的新表存在。所以 SQL 不能根据记录取出字段。
Python
emp = pd.read_csv('EMPLOYEE.csv')
emp1 = emp.iloc[0]
result1 = emp1.NAME
result2 = emp1[['NAME', 'GENDER']].values
result3 = emp1['NAME']
result4 = emp1.iloc[[1,2]].values
result5 = emp1.values
result6 = emp.NAME
1.2.4 记录比较
1. 不同数据表记录比较指针
2. 不同数据表记录比较值
SPL
| A | B | |
|---|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc(EID,NAME,SALARY) | |
| 2 | =file(“EMPLOYEE.csv”).import@tc(EID,NAME,SALARY) | |
| 3 | =file(“EMPLOYEE.csv”).import@tc(EID,NAME) | |
| 4 | =A1(1)==A2(1) | /false |
| 5 | =cmp(A1(1),A2(1)) | /0 |
| 6 | =cmp(A1(1),A2(2)) | /-1 |
| 7 | =cmp(A1(1),A3(1)) | /1 |
A4: 不同序表记录比较指针
A5-A7:不同序表记录比较值
SQL
SQL 不支持记录直接比较。
Python
Pandas 不支持记录直接比较,需要转成 list 比较。
1.2.5 集合运算
1. 交集
2. 差集
3. 并集
4. 和集
SPL
| A | B | |
|---|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc() | |
| 2 | =A1.select(GENDER==“F”) | |
| 3 | =A1.select(DEPT==“Sales”) | |
| 4 | =A2^A3 | =[A2,A3].isect() |
| 5 | =A2\A3 | =[A2,A3].diff() |
| 6 | =A2&A3 | =[A2,A3].union() |
| 7 | =A2|A3 | =[A2,A3].conj() |
SQL
1. 交集
SELECT * FROM EMPLOYEE
WHERE GENDER = 'F'
INTERSECT
SELECT * FROM EMPLOYEE
WHERE DEPT = 'Sales';
2. 差集
SELECT * FROM EMPLOYEE
WHERE GENDER = 'F'
MINUS
SELECT * FROM EMPLOYEE
WHERE DEPT = 'Sales';
3. 并集
SELECT * FROM EMPLOYEE
WHERE GENDER = 'F'
UNION
SELECT * FROM EMPLOYEE
WHERE DEPT = 'Sales';
4. 和集
SELECT * FROM EMPLOYEE
WHERE GENDER = 'F'
UNION ALL
SELECT * FROM EMPLOYEE
WHERE DEPT = 'Sales';
Python
Pandas 没有记录构成的集合数据类型。
1.2.6 泛型数据表
1) 字段值是集合
SPL
| A | B | C | |
|---|---|---|---|
| 1 | 1 | 91993.67 | [82] |
| 2 | 2 | 96754.54 | [88,12] |
| 3 | 3 | 28409.55 | [73,71] |
| 4 | 4 | 32972.12 | [29,82] |
| 5 | 5 | 51869.75 | [60,1] |
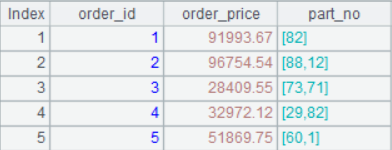
| 6 | =create(order_id,order_price,part_no) | ||
| 7 | =A6.record([A1:C5]) | ||
| 8 | =A6(2).part_no(1) | /88 |
可以把上表看作订单表的一部分,包括订单号,订单价格和该订单下的零件编号。
A7 结果:
SQL
CREATE OR REPLACE TYPE NUMBER_LIST_TYPE AS VARRAY(5) OF NUMBER;
--之前创建过这个类型了,这里可以不创建。
CREATE TABLE order_gen (ORDER_ID NUMBER,ORDER_PRICE NUMBER,PART_NO NUMBER_LIST_TYPE);
INSERT ALL
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (1,91993.67,number_list_type (82))
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (2,96754.54,number_list_type (88,12))
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (3,28409.55,number_list_type (73,71))
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (4,32972.12,number_list_type (29,82))
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (5,51869.75,number_list_type (60,1))
SELECT * FROM dual;
SELECT COLUMN_VALUE FROM TABLE(
SELECT PART_NO FROM (
SELECT PART_NO, ROWNUM AS rnum FROM order_gen)
WHERE rnum = 2)
WHERE ROWNUM = 1;
表 order_gen 结果如下:
ORDER_ID ORDER_PRICE PART_NO
-----------------------------------------------------------------------
1 91993.67 NUMBER_LIST_TYPE(82)
2 96754.54 NUMBER_LIST_TYPE(88, 12)
3 28409.55 NUMBER_LIST_TYPE(73, 71)
4 32972.12 NUMBER_LIST_TYPE(29, 82)
5 51869.75 NUMBER_LIST_TYPE(60, 1)
Python
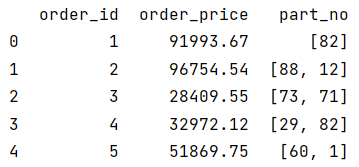
info = [[1,91993.67,[82]],
[2,96754.54,[88,12]],
[3,28409.55,[73,71]],
[4,32972.12,[29,82]],
[5,51869.75,[60,1]]]
data = pd.DataFrame(info,columns=['order_id','order_price','part_no'])
data_list1 = data.iloc[1].part_no[0] #88
data 结果:
2) 字段值是记录
SPL
| A | |
|---|---|
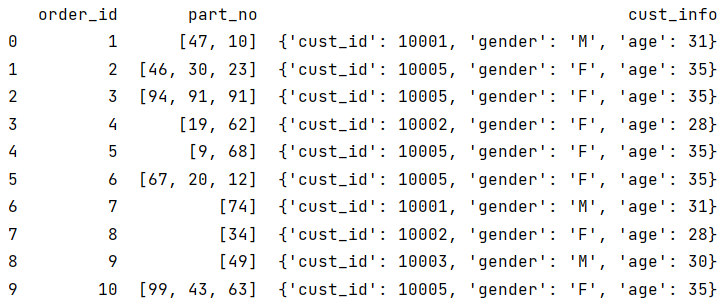
| 1 | [{“order_id”:1,“part_no”:[47,10],“cust_info”:{“cust_id”:10001,“gender”:“M”,“age”:31}},{“order_id”:2,“part_no”:[46,30,23],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}},{“order_id”:3,“part_no”:[94,91,91],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}},{“order_id”:4,“part_no”:[19,62],“cust_info”:{“cust_id”:10002,“gender”:“F”,“age”:28}},{“order_id”:5,“part_no”:[9,68],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}},{“order_id”:6,“part_no”:[67,20,12],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}},{“order_id”:7,“part_no”:[74],“cust_info”:{“cust_id”:10001,“gender”:“M”,“age”:31}},{“order_id”:8,“part_no”:[34],“cust_info”:{“cust_id”:10002,“gender”:“F”,“age”:28}},{“order_id”:9,“part_no”:[49],“cust_info”:{“cust_id”:10003,“gender”:“M”,“age”:30}},{“order_id”:10,“part_no”:[99,43,63],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}}] |
| 2 | =A1(2).cust_info |
| 3 | =A2.gender |
SPL 支持把 json 格式的数据识别成序表,A1 结果如下:
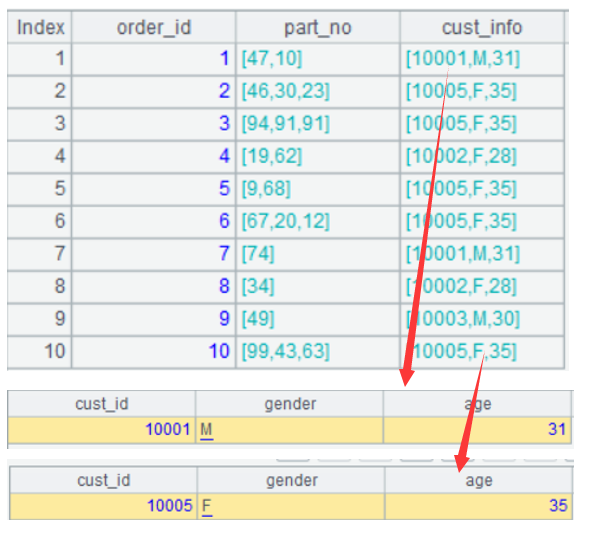
A2 是条记录:

A3 是取 cust_info 的 gender 字段:

SQL
SQL 很难直接根据 json 串生成带记录的表。
Python
data=[
{"order_id":1,"part_no":[47,10],"cust_info":{"cust_id":10001,"gender":"M","age":31}},
{"order_id":2,"part_no":[46,30,23],"cust_info":{"cust_id":10005,"gender":"F","age":35}},
{"order_id":3,"part_no":[94,91,91],"cust_info":{"cust_id":10005,"gender":"F","age":35}},
{"order_id":4,"part_no":[19,62],"cust_info":{"cust_id":10002,"gender":"F","age":28}},
{"order_id":5,"part_no":[9,68],"cust_info":{"cust_id":10005,"gender":"F","age":35}},
{"order_id":6,"part_no":[67,20,12],"cust_info":{"cust_id":10005,"gender":"F","age":35}},
{"order_id":7,"part_no":[74],"cust_info":{"cust_id":10001,"gender":"M","age":31}},
{"order_id":8,"part_no":[34],"cust_info":{"cust_id":10002,"gender":"F","age":28}},
{"order_id":9,"part_no":[49],"cust_info":{"cust_id":10003,"gender":"M","age":30}},
{"order_id":10,"part_no":[99,43,63],"cust_info":{"cust_id":10005,"gender":"F","age":35}}
]
df=pd.DataFrame(data)
cust_info_rec=df.iloc[1].cust_info #{'cust_id':10005,'gender':'F','age':35}
rec_gender=cust_info_rec['gender'] #F
Python 把 cust_info 作为字典来生成 DataFrame,df 结果:
DataFrame 中每一行其实是一个 Series,而这里的 cust_info 的数据格式只是一个字典,不再是 Series,所以只能用字典的规则来获取 gender,即 rec_gender=cust_info_rec[‘gender’],而不能用 Series 的方式取数,比如 cust_info_rec.gender。
3) 字段值是序表
现有 json 文件如下图,请将文件读成表:
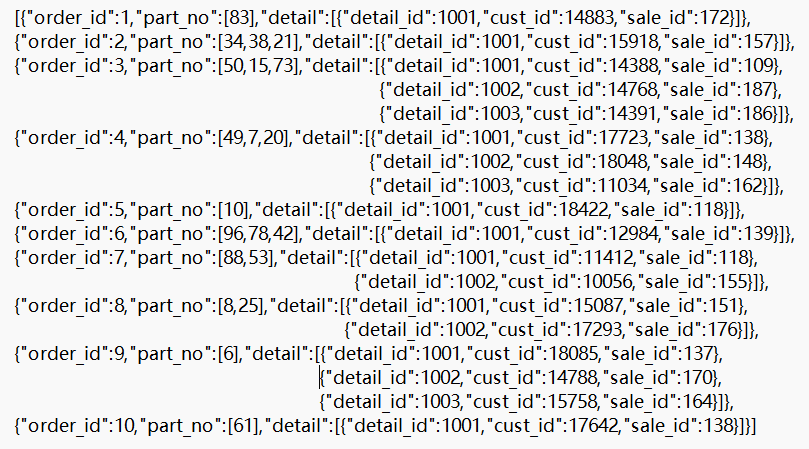
SPL
| A | |
|---|---|
| 1 | =file(“table_data.txt”).read() |
| 2 | =json(A1) |
| 3 | =A2(3).detail |
| 4 | =A3(2) |
| 5 | =A4.cust_id |
A1 读取 json 文件;
A2 将 json 串转换成序表,结果如下:
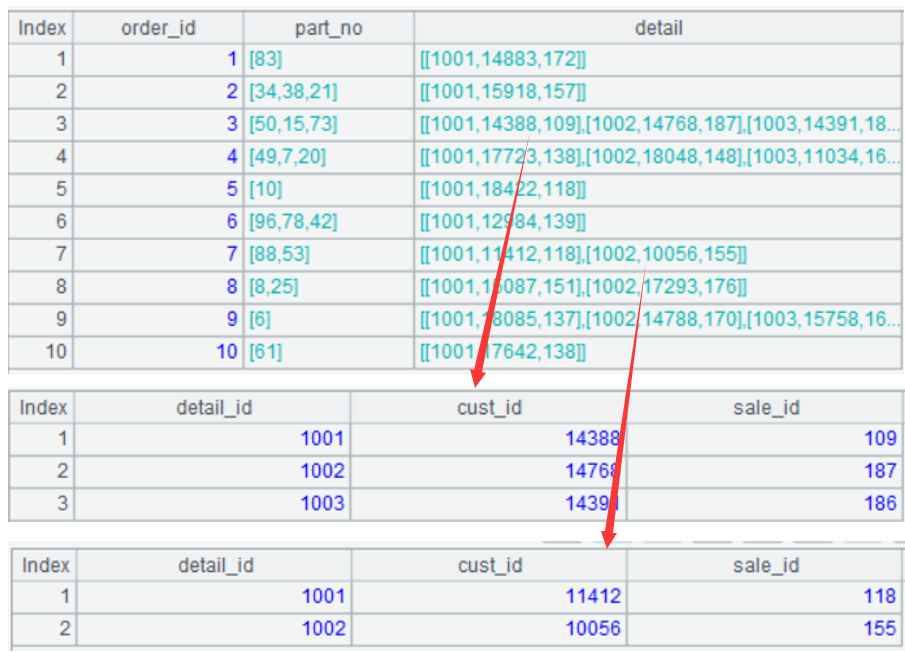
A3:第 3 条记录的 detail 信息:

A4:第三条记录 detail 信息中第 2 条记录

A5:第三条记录 detail 信息中第 2 条记录的 cust_id 字段。
SQL
SQL 很难直接用 json 文件生成带子数据表的表。
Python
df=pd.read_json('table_data.txt')
detail_info_table=df.loc[2].detail #第3条记录的detail信息
detail_2=detail_info_table[1] #第三条记录detail信息中第2条
detail_2_cust_id=detail_2['cust_id'] #第三条记录detail信息中第2条的cust_id字段
Python 把 detail 读成字典的列表,df 结果如下:
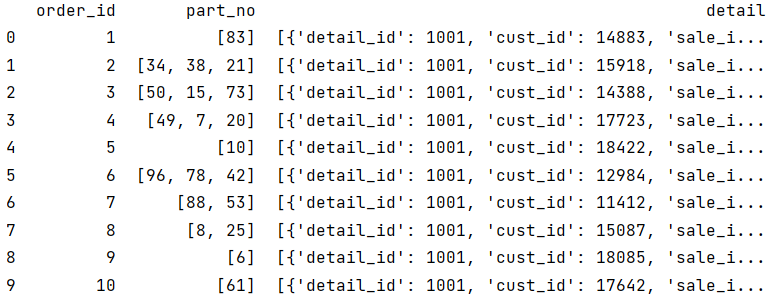
detail_info_table:第 3 条记录 detail 的信息:
[{'detail_id': 1001, 'cust_id': 14388, 'sale_id': 109},
{'detail_id': 1002, 'cust_id': 14768, 'sale_id': 187},
{'detail_id': 1003, 'cust_id': 14391, 'sale_id': 186}]
detail_2:detail_info_table 中的第 2 条:
{'detail_id': 1002, 'cust_id': 14768, 'sale_id': 187}
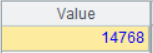
detail_2_cust_id 是 detail_2 中的 cust_id:
14768
和上例类似,detail_info_table 是一个字典的列表,并不是 DataFrame 这一数据结构。所以在获取 detail_info_table 中的第 2 条信息时,只能用 list 的取数方式 detail_info_table[1] 得到,而不能用 detail_info_table.loc[1] 得到,得到的结果 detail_2 是一个字典,而不是 Seires,所以在获取 detail_2 中的 cust_id 时,只能用字典的取数方式 detail_2[‘cust_id’] 得到,而不能用 detail_2.info 得到。
1.2.7 泛型记录序列
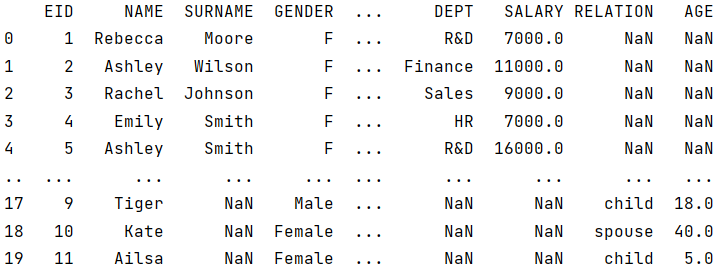
员工表和家属表结构不同,但都有 GENDER 字段,请统计员工和家属中,有多少女性。
SPL
| A | |
|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc() |
| 2 | =file(“FAMILY.csv”).import@tc() |
| 3 | =A1|A2 |
| 4 | =A3.count(left(GENDER,1)==“F”) |
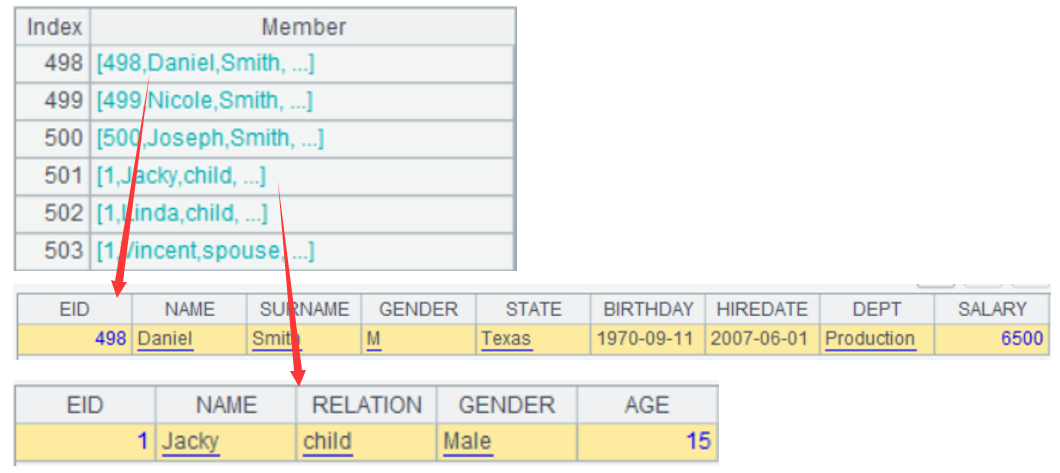
SPL 允许来自不同序表的记录构成新集合,比如 A3,还可以对新集合进行计算。
A3 的结果是记录的集合,集合的每个成员都是一条记录:
SQL
SQL 不允许两张不同结构的表直接合并。
Python
emp = pd.read_csv("EMPLOYEE.csv")
fam = pd.read_csv("FAMILY.csv")
df = pd.concat([emp,fam])
cnt = len(df[df['GENDER'].str[0]=='F'])
Python 不支持不同结构的 DataFrame 简单合并,合并时要把两个表的数据结构调整到相同。
df 结果: