


SPL 实践系列:多源混算
SPL 实践系列:多源混算
背景
应用数据的生成方式和存储形式多样,不仅依赖传统的关系型数据库,还有 NoSQL 数据库、云存储、API、文件系统等多种数据源。整合和分析这些数据就面临多样性数据源混合计算问题。
逻辑数据仓库可以一定程度上实现多源混算,由于逻辑数仓大部分是基于 SQL 的,RDB 数据源可以通过表映射访问。但其他类型的数据源就比较困难,需要借助复杂的数据虚拟化技术,还只能部分实现。
而且,逻辑数仓体系过于沉重,它经常会比应用本身还复杂,只适合应用于大型场景中。
SPL 方案
SPL 提供了多数据源实时混合计算功能,无论何种数据源只要能访问到就都能混算。而且 SPL 的多源混算功能非常轻量,可以直接嵌入到应用程序工作。
SPL 多源混算结构与特性
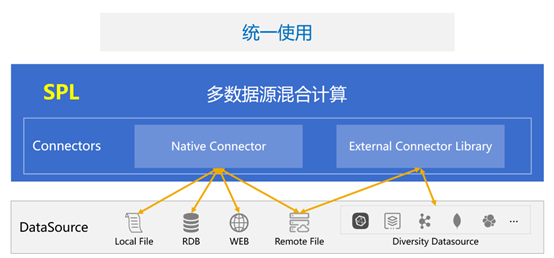
SPL 的数据源连接器分为两种:原生连接器和外部连接器。最常见的 RDB,文本、Excel、JSON 等本地文件,以及 HTTP 数据源等都属于原生连接器,内置在 SPL 核心体系中。而其他多样性数据源,如 MongoDB、Kafka、ElasticSearch、云存储都属于外部连接器,不在 SPL 核心体系内,需要另外部署。
与逻辑数仓的映射方式不同,SPL 支持并提倡使用数据源的原生语法实现数据访问和计算,如果数据源本身的计算能力不足,则可以使用 SPL 来补充,在后面实例中我们会具体看到。
SPL 支持数据源种类很多,这里列出了 SPL 支持的部分数据源,基本常见的数据源都包含了。

其中,原生连接器支持的数据源种类包括:MySQL、Oracle 等 JDBC 数据源;CSV、Excel、JSON 文件等 Local File;HTTP、RestAPI 等 Web 数据源,以及远程文件等。
外部库列表则包括以下数十种非常规数据源及函数:
外部连接器放在外部库中,外部库是 SPL 提供的外部函数扩展库,将一些在普遍场景使用频率不高的专门用途函数以外部库形式提交,这样可以根据需要临时加载。
外部数据源种类繁多,也不是每种数据源都很常用,所以将这些连接器以外部库的形式提供会更为灵活,以后发现有新的数据源也可以及时补充而不影响现有的数据源。
绝大多数外部库都是外部连接器。
SPL 提供了两种数据对象用于访问数据源,序表和游标,分别对应内存数据表和流式数据表。
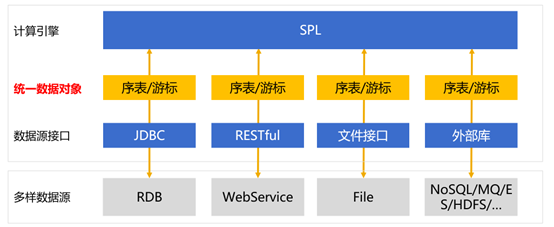
包括关系数据库在内,几乎所有的数据源都会提供这两种数据对象的接口:小数据一次性读出,使用内存数据表;大数据要逐步返回,使用流式数据表。有了这两种数据对象,就可以覆盖几乎所有的数据源了。
和逻辑数仓不同,SPL 不需要事先定义元数据做映射,直接使用数据源本身提供的方法来访问数据,只要封装成这两种数据对象之一即可。
这样可以保留数据源的特点,充分利用其存储和计算能力。当然更不需要先把数据做“某种”入库动作,实时访问就可以。这两种数据对象是多样性数据源访问接口共有的能力,而逻辑数仓采用的映射数据表方法并没有合理抽象出多样性数据源的公共特征,与 SPL 的差异很大。
接下来我们看一下具体使用。
在 IDE 内使用
配置数据源
对于原生连接器,在 IDE 内配置最常见的 JDBC 连接,这里我们使用 MySQL。复制数据库驱动 jar 到:[安装目录]/ common/jdbc 下,如图示配置 MySQL 标准 JDBC 连接。
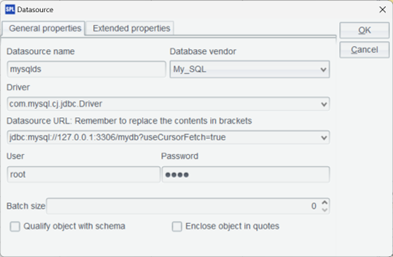
使用外部连接器,需要下载外部库驱动包,具体地址请参照 SPL 论坛上的下载链接。将其解压至任意目录,如 [安装目录]\esProc\extlib,加载外部库。
在 IDE 的菜单 tool-Options,Environment 选项卡下选择刚刚下载解压的外部库目录。
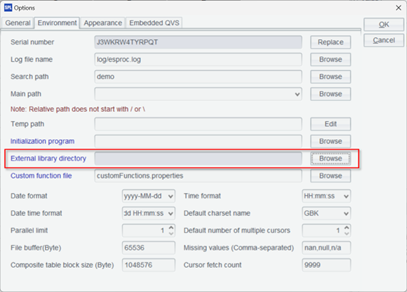
这时所有外部库都会列出来,然后勾选我们需要加载的外部库。
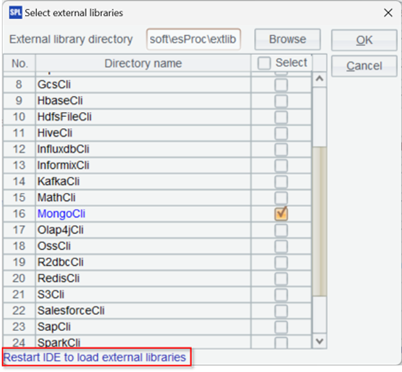
这里选择了 MongoDB,勾选确定后需要重启 IDE 才能生效。
混算实例
Mongodb 与 MySQL 混合查询
我们的实例来源于电商业务,使用 MySQL 存储订单相关信息,涉及的两个表 orders 和 order_items 结构是这样的:
Orders:
| 字段 | 类型 | 说明 |
|---|---|---|
| order_id | INT (PK) | 订单标识 |
| user_id | INT | 用户 ID |
| order_date | DATETIME | 订单日期 |
| total_amount | DECIMAL(10, 2) | 订单金额 |
Order_items:
| 字段 | 类型 | 说明 |
|---|---|---|
| order_item_id | INT (PK) | 商品项标识 |
| order_id | INT(FK) | 订单 ID |
| product_id | VARCHAR(20) | 商品 ID |
| quantity | INT | 购买数量 |
| price | DECIMAL(10, 2) | 单价 |
两个表通过 order_id 关联。
由于商品信息会根据类型动态变化,比如电子产品有品牌、型号和规格,而服装则包括品牌、尺寸和颜色,因此使用 MongoDB 来存储商品信息,其中 attributes 字段为动态属性。
| 字段 | 说明 |
|---|---|
| product_id | 商品 ID(与 MySQL 关联) |
| name | 名称 |
| brand | 品牌 |
| category | 分类 |
| attributes | 动态属性 |
商品集合通过 product_id 与 MySQL 关联。
这是 MySQL 和 MongoDB 的示例数据。
Orders:
| order_id | user_id | order_date | total_amount |
|---|---|---|---|
| 1 | 101 | 2024-09-01 | 1999.99 |
| 2 | 102 | 2024-09-02 | 1599.99 |
| … |
Order_items:
| order_item_id | order_id | product_id | quantity | price |
|---|---|---|---|---|
| 1 | 1 | prod_1001 | 1 | 999.99 |
| 2 | 1 | prod_1002 | 1 | 1000.00 |
| 3 | 2 | prod_1003 | 1 | 1599.99 |
| … |
MongoDB:
{
"product_id": "prod_1001",
"name": "Smartphone X",
"brand": "BrandA",
"category": "Electronics",
"attributes": {
"color": "Black",
"storage": "128GB"
}
},
{
"product_id": "prod_1002",
"name": "Laptop Y",
"brand": "BrandB",
"category": "Computers",
"attributes": {
"processor": "Intel i7",
"ram": "16GB"
}
…
}
我们要查询最近一个月,‘Tablets’, ‘Wearables’, ‘Audio’ 这三类商品的销售总额,会涉及跨 MySQL 和 MongoDB 混合查询。
SPL 实现脚本:
| A | |
|---|---|
| 1 | =connect(“mysql”) |
| 2 | =A1.query@x (“SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date >= CURDATE()- INTERVAL 1 MONTH”) |
| 3 | =mongo_open(“mongodb://127.0.0.1:27017/raqdb”) |
| 4 | =mongo_shell@d (A3, "{ ‘find’: ‘products’, ‘filter’: { ‘category’: {‘$in’: [‘Tablets’, ‘Wearables’, ‘Audio’] } }}” ) |
| 5 | =A2.join@i(product_id,A4:product_id,name,brand,category,attributes) |
| 6 | =A5.groups(category;sum(price*quantity):amount) |
A1 连接 MySQL,并在 A2 通过 SQL 查询一个月内的订单数据,选项 @x 表示查询后关闭数据库连接。查询结果是这样的。
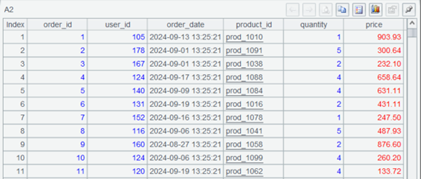
A3 连接 MongoDB。
A4 使用 mongo_shell 函数查询并过滤数据,@d 选项表示返回序表。函数参数是 MongoDB Command 标准的 JSON 字符串,也就是 MongoDB 的原生语法。可以看到符合条件的数据查出来了。
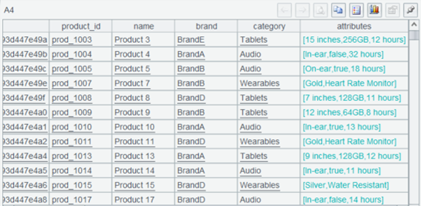
A5 将两部分通过 product_id 进行关联,这是关联结果。
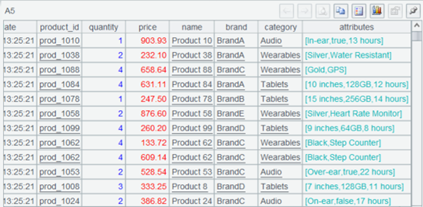
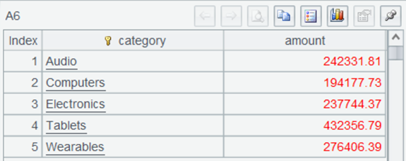
A6 按产品种类汇总订单金额,算出最终结果,完成整个多源混合计算过程非常简单。
Kafka 与 MongoDB 混合查询
我们再使用 kafka 来参与计算。
基于前面的场景,使用 kafka 进行订单信息和商品信息发布,用户下单时,订单数据将被 producer 发送到 order 主题。
先看一下生产者脚本:
| A | |
|---|---|
| 1 | =kafka_open(“/mafia/my.properties”,“topic-order”) |
| 2 | [ { “order_id”: “1”, “user_id”: “101”, “product_id”: “prod_1001”, “quantity”: 1 }, … ] |
| 3 | =kafka_send(A1, “A101”, A2) |
| 4 | =kafka_close(A1) |
A1 连接 kafka 服务器,用到的属性文件 my.properties 内容是这样的:
bootstrap.servers=localhost:9092
client.id=SPLKafkaClient
session.timeout.ms=30000
request.timeout.ms=30000
enable.auto.commit=true
auto.commit.interval.ms=1000
group.id=spl-consumer-group
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
A2 是要发送的订单数据,正常需要接收来自程序传递,这里我们直接写好。
A3 发送订单数据,A4 关闭连接。
接下来看消费数据的脚本:
| A | |
|---|---|
| 1 | =kafka_open(“/mafia/my.properties”,“topic-order”) |
| 2 | =kafka_poll(A1) |
| 3 | =json(A2.value) |
| 4 | =mongo_open(“mongodb://127.0.0.1:27017/raqdb”) |
| 5 | =mongo_shell@d(A4,“{‘find’:‘products’}”) |
| 6 | =A3.join(product_id,A5:product_id,product_id,name,brand,category,attributes) |
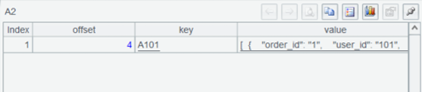
A2 获取 consumer 消息记录,返回序表,结果是这样:
A3 将订单数据 JSON 串转换成序表。
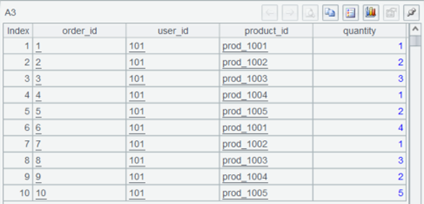
A5 查询所有商品数据。
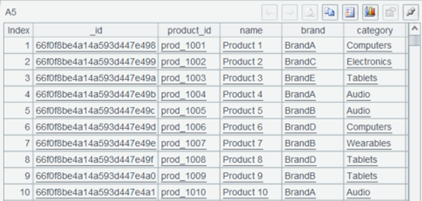
A6 根据 product_id 关联,得到订单及商品所有信息。
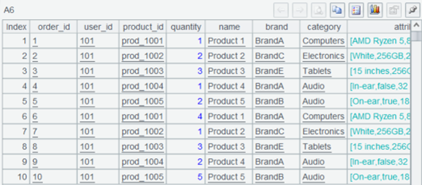
至此,kafka 与 MongoDB 的关联计算也完成了。
大数据支持
还有一种情况,当数据量较大时全量读取会很慢,甚至可能导致内存溢出。这时候要采用游标机制将数据以流的形式逐步读出。
我们改一下前面 MySQL 和 MongoDB 混算的例子:
| A | |
|---|---|
| 1 | =connect(“mysql”) |
| 2 | =A1.cursor@x (“SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date >= CURDATE() - INTERVAL 1 MONTH ORDER BY oi.product_id ASC”) |
| 3 | =mongo_open(“mongodb://127.0.0.1:27017/raqdb”) |
| 4 | =mongo_shell@dc(A3,“{ ‘find’: ‘products’, ‘filter’: {}, ‘sort’: {‘product_id’: 1}}”) |
| 5 | =joinx(A2:o,product_id;A4:p,product_id) |
| 6 | =A5.groups(p.category;sum(o.price*o.quantity):amount) |
A2 将原来的 query 改成 cursor,即返回游标,结果是一个游标对象,此时数据还并未真正读取。

A4 使用 @c 选项,意味着查询的 MongoDB 数据也返回游标,结果同样是游标对象。
A5 使用 joinx 函数将两个游标进行关联,使用该函数要求两个游标对关联字段有序,所以我们在 A2 的 SQL 和 A4 的 MongoDB 命令中都进行了排序。
A5 的关联结果仍然是游标,如果使用 fetch 取数可以看到真实结果是一个多层序表。
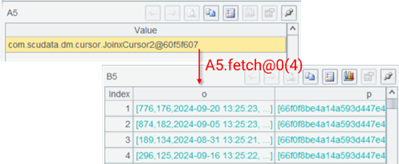
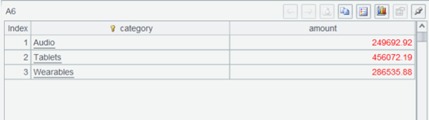
A6 按照分类进行汇总,得到计算结果。直到此时所有游标才真正开始取数计算。
几乎所有数据源都可以使用 SPL 游标来应对大数据计算。
在应用内使用
下面我们看一下如何在应用中使用 SPL。
应用集成
SPL 与应用集成非常简单,只需要将 [安装目录]\esProc\lib 下的:esproc-bin-xxxx.jar 和 icu4j-60.3.jar 两个 jar 包引入到应用中,然后复制 [安装目录]\esProc\config 下的 raqsoftConfig.xml 到应用的类路径下即可。
raqsoftConfig.xml 是 SPL 的核心配置文件,名称不可更改。
在 raqsoftConfig.xml 中,需要配置外部库,使用到哪个配置哪个即可。比如我们用到的 MongoDB 和 Kafka:
<importLibs>
<lib>KafkaCli</lib>
<lib>MongoCli</lib>
</importLibs>
同时 MySQL 数据源也需要配置在这里,在 DB 节点下配置连接信息:
<DB name="mysql">
<property name="url" value="jdbc:mysql://127.0.0.1:3306/raqdb?useCursorFetch=true"/>
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="type" value="10"/>
<property name="user" value="root"/>
<property name="password" value="root"/>
<property name="batchSize" value="0"/>
<property name="autoConnect" value="false"/>
<property name="useSchema" value="false"/>
<property name="addTilde" value="false"/>
<property name="caseSentence" value="false"/>
</DB>
Java 调用
SPL 封装了标准 JDBC 接口,通过加载 SPL 驱动,再使用 call SPL 脚本 的方式即可调用。
public static void main(String[] args) {
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
PreparedStatement st =conn.prepareCall("call mongo_join_mysql()");
st.execute();
ResultSet rs = st.getResultSet();
while (rs.next()) {
String category = rs.getString("category");
System.out.print(category+",");
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
这部分与普通数据库 JDBC 调用存储过程一致,我们不赘述。
以上就是 SPL 多源混算的内容。
我们在这里仅演示了部分数据源间的混合计算,SPL 支持的数据源很多,而且还能扩展。
由于提供了统一数据对象,只要 SPL 能访问到,就都能混合计算,非常简单。
SPL 是开源软件,可以从 github 获取源码:https://github.com/SPLWare/esProc


英文版