


开发量化策略模型的神器 SPL
早期还有些人使用C++,Java开发量化交易的策略模型,但目前这个领域几乎被Python垄断了,原因大概有以下两点:
Python的语法便捷,操作界面也简单易学,毕竟量化分析师还不是职业的程序员,去掌握架构复杂的企业应用开发技术(Java/C++)有点太麻烦了;
Python的类库全面。数据分析处理有Numpy、Pandas;可视化工具Matplotlib、Seaborn;金融技术分析工具有TA-Lib;机器学习有scikit-learn;深度学习有TensorFlow 、Pytorch等等。这些类库,特别是数据算法相关的类库,对量化交易策略的实现提供了强有力的支持。
不过,Python也不是尽善尽美。
有些代码还是比较复杂。比如循环函数不足,经常要for循环硬编码;再比如相邻引用、定位计算、有序分组等,无论是Python本身还是第三方库,都没有提供这些常见运算的方法,遇到了只能硬编码或者“迂回”绕路解决。
调试也不是很方便。Python的IDE很多,也都具备debug功能,但用的最多的还是“print大法”,总是很麻烦。
Python的大数据方法也缺失。当数据量大到单机内存放不下时,只能自己硬编码分段处理,代码本身难写,运行效率也不尽如人意。而且,Python没有真正的并行,多线程实际上还是单线程,想要真并行只能多进程并行,量化分析师几乎不可能独自完成。
那么,除了Python,还有别的什么程序语言能用来做量化交易策略吗?
esProc SPL可以克服Python的这些缺点。
esProc SPL是一款专门用于结构化数据计算的程序语言,它的语法比Python更便捷,初学者学习两三天就可以写代码了,真正做到了代码写着简单;SPL的运算完善,尤其是关于序的运算是经过精心设计的,比如相邻引用、有序分组、定位计算等,SPL的语法一致且书写简单;SPL是网格式编程语言,每个格子的计算结果可以实时查看,不需要print,调试代码方便快捷。而且,SPL对大数据和并行的支持也非常完善。美中不足的是SPL目前对机器学习算法的支持力度还不够。
更敏捷的代码
SPL的敏捷语法体现在书写代码的各个方面,比如集合运算、lambda语法等,这里不全面介绍,仅以Lambda语法为例来说明。
我们来看一些量化分析中常见的计算。
例1:假设下面的序列是某支股票一个月的股价,现在要计算这个月股价每天的涨跌幅,并规定第一天的涨幅为0。
先看Python代码
close=[12.99,12.72,12.7883,12.5931,13.2081,13.1105,12.8371,13.0421,13.3741,12.7981,12.925,12.9152,12.7883,13.0226,12.7298,12.4564,12.5833,12.6419,12.6712,12.4662,12.7981,12.8274]
s = pd.Series(close)
ss = s.shift()
ma = (s-ss).fillna(0).max()
再看SPL代码
A |
|
1 |
[12.99,12.72,12.7883,12.5931,13.2081,13.1105,12.8371,13.0421,13.3741,12.7981,12.925,12.9152,12.7883,13.0226,12.7298,12.4564,12.5833,12.6419,12.6712,12.4662,12.7981,12.8274] |
2 |
=A1.(if(#==1,0,~-~[-1])).max() |
SPL用#表示当前成员序号,~表示当前成员,[]获取相邻成员,代码非常简单。Python的Lambda语法无法同时获取当前成员、当前成员序号和相邻成员,所以只能偏移索引再把空值填为0,书写起来略显繁琐。
例2:计算股价最高的三天的涨幅
Python代码
stock_prices = [12.99, 12.72, 12.7883, 12.5931, 13.2081, 13.1105, 12.8371, 13.0421, 13.3741, 12.7981, 12.925, 12.9152, 12.7883, 13.0226, 12.7298, 12.4564, 12.5833, 12.6419, 12.6712, 12.4662, 12.7981, 12.8274]
top_three_days = sorted(range(len(stock_prices)), key=lambda i: stock_prices[i],reverse=True)[:3]
increases = [stock_prices[i] / stock_prices[i-1] -1 if i!=0 else None for i in top_three_days]
SPL代码
A |
|
1 |
[12.99,12.72,12.7883,12.5931,13.2081,13.1105,12.8371,13.0421,13.3741,12.7981,12.925,12.9152,12.7883,13.0226,12.7298,12.4564,12.5833,12.6419,12.6712,12.4662,12.7981,12.8274] |
2 |
=A1.ptop(-3,~) |
3 |
=A1.calc(A2,if(#==1,null,~/~[-1]-1)) |
Python需要按股价排序后,找到股价最高的3个索引,然后再写for循环完成股价涨幅的计算。
SPL的ptop()方法可以直接找到股价最高的3天的索引,底层也没有大排序。然后直接用calc函数定位到股价最高3天的索引,借用[]获取相邻成员,完成涨幅计算,写起来简单明了。
例3:计算股价连续上涨的最大天数
Python代码
stock_prices = [12.99, 12.72, 12.7883, 12.5931, 13.2081, 13.1105, 12.8371, 13.0421, 13.3741, 12.7981, 12.925, 12.9152, 12.7883, 13.0226, 12.7298, 12.4564, 12.5833, 12.6419, 12.6712, 12.4662, 12.7981, 12.8274]
max_days = 0
current_days = 1
for i in range(1, len(stock_prices)):
if stock_prices[i] > stock_prices[i - 1]:
current_days += 1
else:
max_days = max(max_days, current_days)
current_days = 1
max_days = max(max_days, current_days)
SPL代码
A |
|
1 |
[12.99,12.72,12.7883,12.5931,13.2081,13.1105,12.8371,13.0421,13.3741,12.7981,12.925,12.9152,12.7883,13.0226,12.7298,12.4564,12.5833,12.6419,12.6712,12.4662,12.7981,12.8274] |
2 |
=A1.group@i(~<~[-1]).max(~.len()) |
因为Python缺少关于序运算的基础方法,所以只能硬编码来实现。而SPL提供了group@i()方法,当条件发生变化时(股价下跌)就重新分组,所以组内的成员数就是上涨的天数,两者相比,谁更敏捷,一看便知。
更简易的安装与更方便的调试
先说安装,Python的安装还是有一些门槛的。安装基础部分比较简单,按照网上的步骤,一步一步走下来,对于大多数人来说也没什么问题,只是花点时间。但是第三方库的安装就不是很简单了,Python本身和第三方库的版本并不统一管理,所以经常会遇到Python版本和库版本或者A库版本和C库版本不兼容的情况,如果不幸遇到了,单是解决这个问题都要挠挠头,出出汗。
SPL的安装几乎是傻瓜式的,官网下载安装包后,全程下一步就安装完成了。
再说调试,Python有很多IDE,常用的有Pycharm、Eclipse、Jupyter Notebook等等,它们之间本身也各有优劣,但Python最常用的调试还是print大法(把想看的变量值打印出来),这非常麻烦,调试完以后还要删掉。断点的设置、执行等都是正常设置,对调试bug很有用,值得一提的是Python的多数IDE都提供了变量和函数补全功能,写代码时可以节省一些时间。
这是Pycharm的IDE:
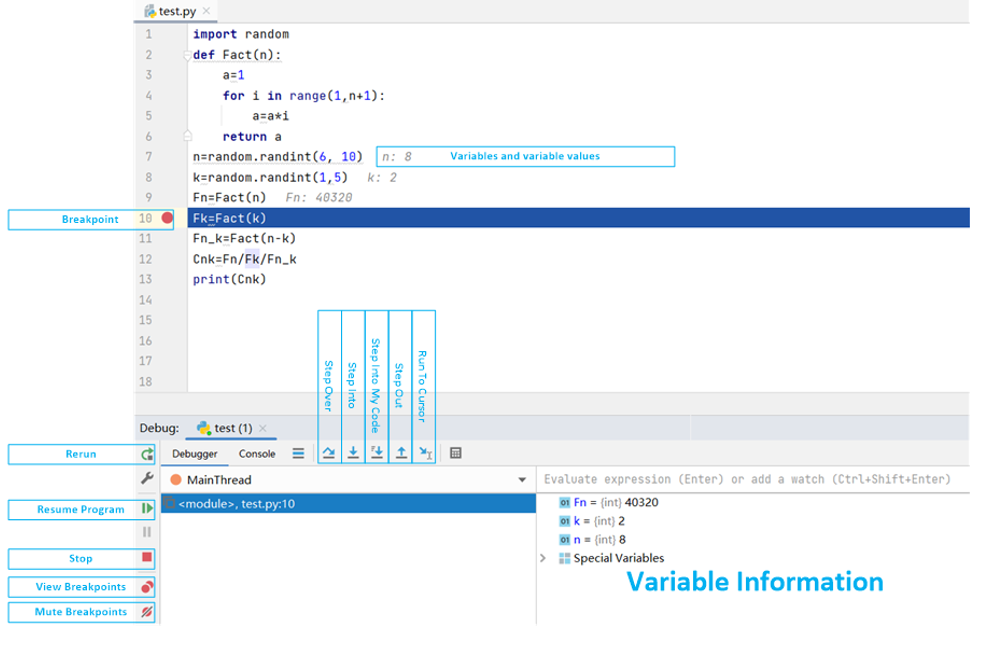
SPL是网格式编程,可以随时查看网格值和变量值,可以看着上一步的结果编写代码,相较于 print 大法要方便太多太多了,断点的设置、使用和Python的IDE区别不大,需要优化的是函数名、变量名的补齐功能。
这是SPL的IDE:
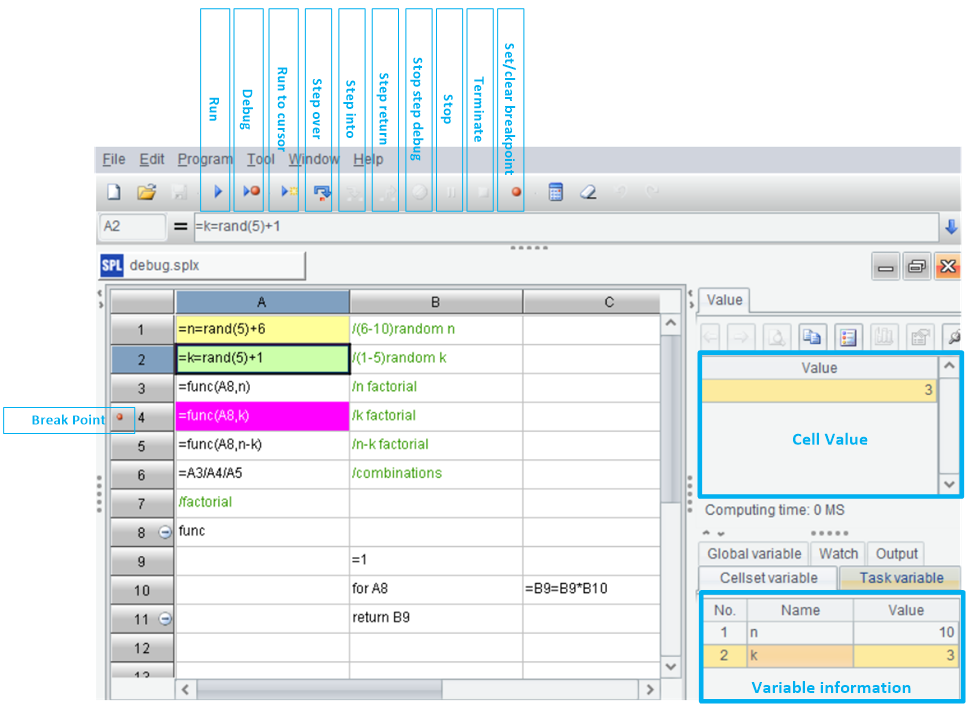
更完善的大数据和并行能力
Python对于大数据的运算支持不足,并行也是伪并行。而SPL拥有完善的游标机制,可以轻松处理大数据,多数游标函数的用法和内存函数没有什么区别,对用户很友好。
比如想要查看各行业的总净资产。
SPL代码
A |
|
1 |
=file("all_stock_info.csv").cursor@tc() |
2 |
=A1.groups(industry;sum(total_assets):assets) |
单纯看A2的代码并不能区分是内存计算还是游标计算,因为它和内存计算时的代码一模一样,SPL把大数据上的运算封装成和内存运算基本一样的形式,减少用户的记忆复杂度。
SPL的并行书写也非常简单,比如想要并行完成上例的计算,只要在A1中增加@m选项即可(cursor@tcm()),A2的代码不变。
SPL的不足和Ymodel补充
相较于Python,SPL的机器学习能力还很薄弱,虽然也支持一些常用的机器学习算法,比如有监督学习算法:线性回归、岭回归、支持向量机;无监督学习算法:k-means聚类等,但一些复杂的模型,比如GBDT、XGB等都还不支持,这可能会给量化交易策略的实现带来一些困难。
不过,就量化分析来说,特别复杂的机器学习算法甚至深度学习通常只有少数大型机构在使用,对于大多数量化分析师来说,交易策略没有那么复杂,一般的策略都可以用SPL来实现。如果真需要特别复杂的机器学习模型,SPL也可以调用YModel的接口来完成复杂模型建立和预测。
YModel是一款自动建模软件,只需一键式的操作就能够自动进行预处理和模型搭建。什么缺失值,异常值,高基数变量,时间特征、算法选择,参数寻优等统统不用担心,YModel都会自动搞定,其中包含了机器学习和深度学习的常用模型,建出的模型能够媲美专业算法工程师,这在很大程度上降低了算法学习的成本,能够帮助精通交易策略而不熟悉算法的金融交易师节省大量的时间,把更多的时间放在交易策略的研究上,而不是那些复杂的数学算法。SPL调用YModel的自动建模接口,两者相互配合,便捷高效的实现交易策略的编写和测试。
举一个用SPL和YModel建模配合完成机器学习交易策略的简单例子:
利用营运资本、净债务、市净率、总资产净利率、换手率这五个指标来预测公司市值大小,如果预测市值远大于真实市值,则认为市值被低估了,反之则认为市值被高估了。
假设我们已经用 SPL 将这些数据整理完了,特征变量是净资产、资产负债率、净利润、净利润率、利润增长率,目标变量是公司市值。
配置YModel建模参数,去掉股票代码(ts_code):
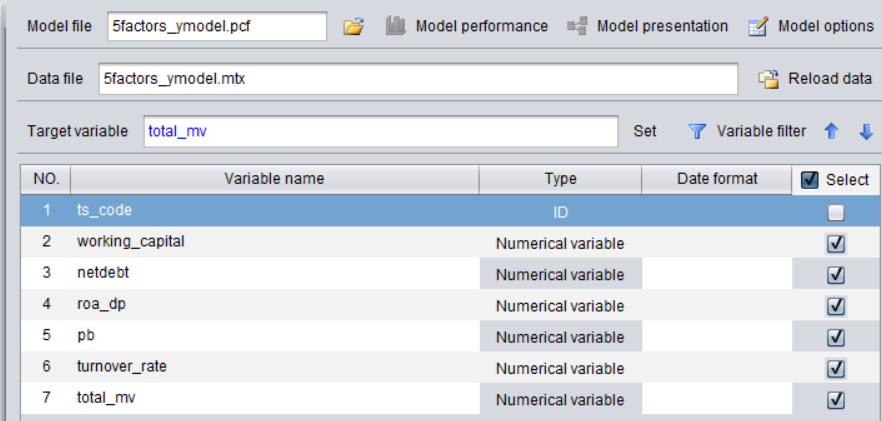
选择模型(多数情况下默认即可)
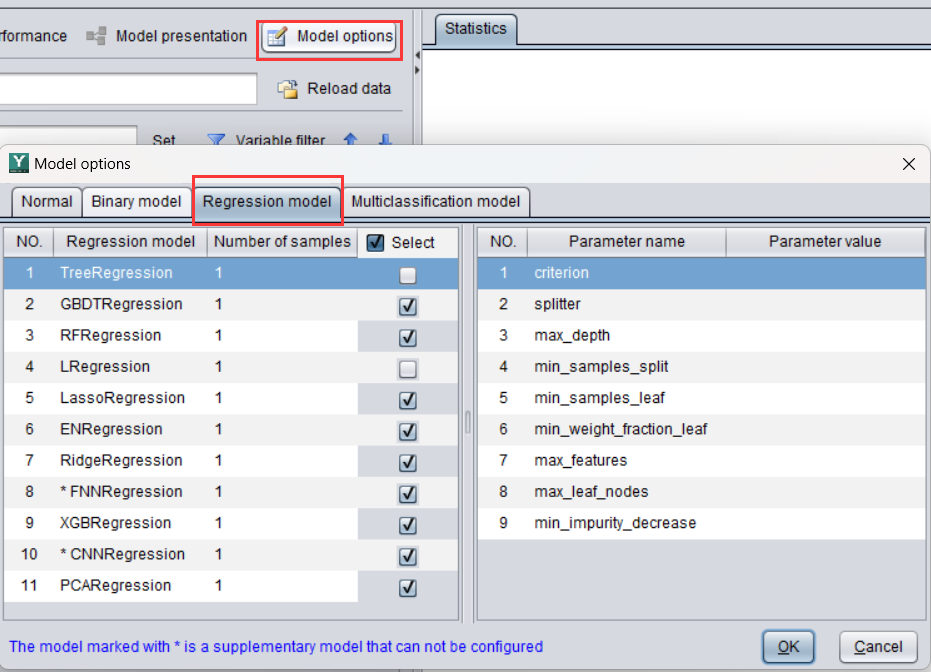
用这些信息生成信息模型参数文件(.mcf)
SPL建模和预测
A |
|
1 |
=ym2_env("D:/Ymodel/ymodel") |
2 |
=ym2_mcfload("D:/Ymodel/ymodel/data/5factors_ymodel.mcf") |
3 |
=ym2_model(A2) |
4 |
=ym2_pcfsave(A3,"D:/Ymodel/ymodel/data/5factors_ymodel.pcf") |
5 |
=ym2_pcfload("D:/Ymodel/ymodel/data/5factors_ymodel.pcf") |
6 |
=ym2_predict(A5,"D:/Ymodel/ymodel/data/5factors_ymodel.csv") |
7 |
=ym2_result(A6) |
8 |
>ym2_close() |
9 |
=A7.derive(1-total_mv_predictvalue/total_mv:diff_rate) |
10 |
=A9.sort(diff_rate) |
A1:初始化环境
A2:加载模型参数(mcf文件)
A3:自动建模
A4:保存模型文件(pcf文件)
A5:加载模型文件
A6:利用模型对csv文件中的新数据进行预测
A7:预测结果
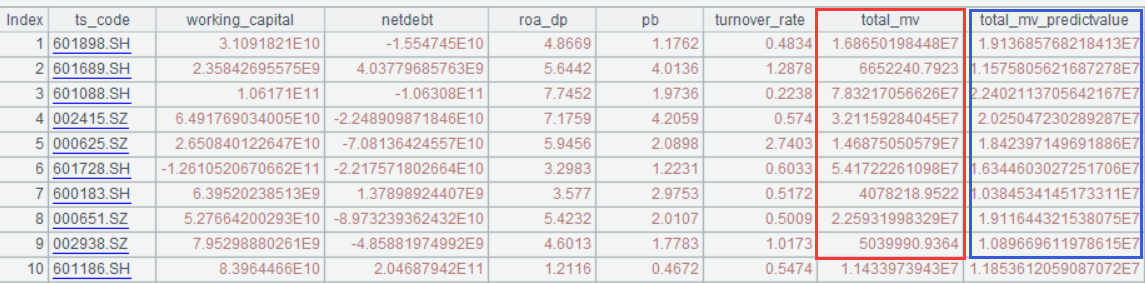
图中红框是目标变量(市值),蓝框是YModel建模预测结果(预测市值)。
SPL准备好数据文件后,由YModel按照上面的建模和预测过程,最后再由SPL来分析模型结果即可,整个流程一气呵成。SPL加YModel来做量化,要比Python独立完成数据处理(缺失值、异常值、高基数等)、模型选择、参数调整快的多,对于普通的量化分析师来说,YModel建立的模型也足够准确了。


英文版