


基于父 / 子层级结构的汇总
层级结构经常出现在数据模型中,这种结构让 DataMonkey 使用预设的路径对数据进行汇总计算,而一旦涉及到这种深度遍历 (DFS) 的计算往往避免不了递归,因此基于层级结构的计算往往具有一定的挑战性,小白很容易懵圈。比如以下例子,要求根据表 1 中的层级关系和表 2 中的明细数据,得到结果表:

这是一个很典型的父 / 子层级结构,比较麻烦的地方是不仅要基于层级关系得到正确的汇总结果,还要根据当前层级的深度布局出一定数量的向右缩进,还有一个是有些中间节点,不仅包含子节点的值,还有其本身的值,比如 Brad 这个节点,包含子节点 Chris 的 400 和 Vincent 的 500,还有其自身的 400,所以 Brad 这个节点的汇总结果是 1300,类似的还有 Annabel 这个节点。
实际上,这是微软 DAX 权威指南里的一个例子,但 DAX 没有提供支持层级结构计算的内置函数,需要编写较为复杂的甚至比递归更让人懵圈的 DAX 代码来实现,简单举例如下,首先要基于表 1 计算出以下截图中的后 6 列,这里最多是 3 层的深度,如果是好几层,那 Level1,Level2…就得编写好几遍,而且一旦层级结构扩大或改变,需要重新编写,维护起来不方便。
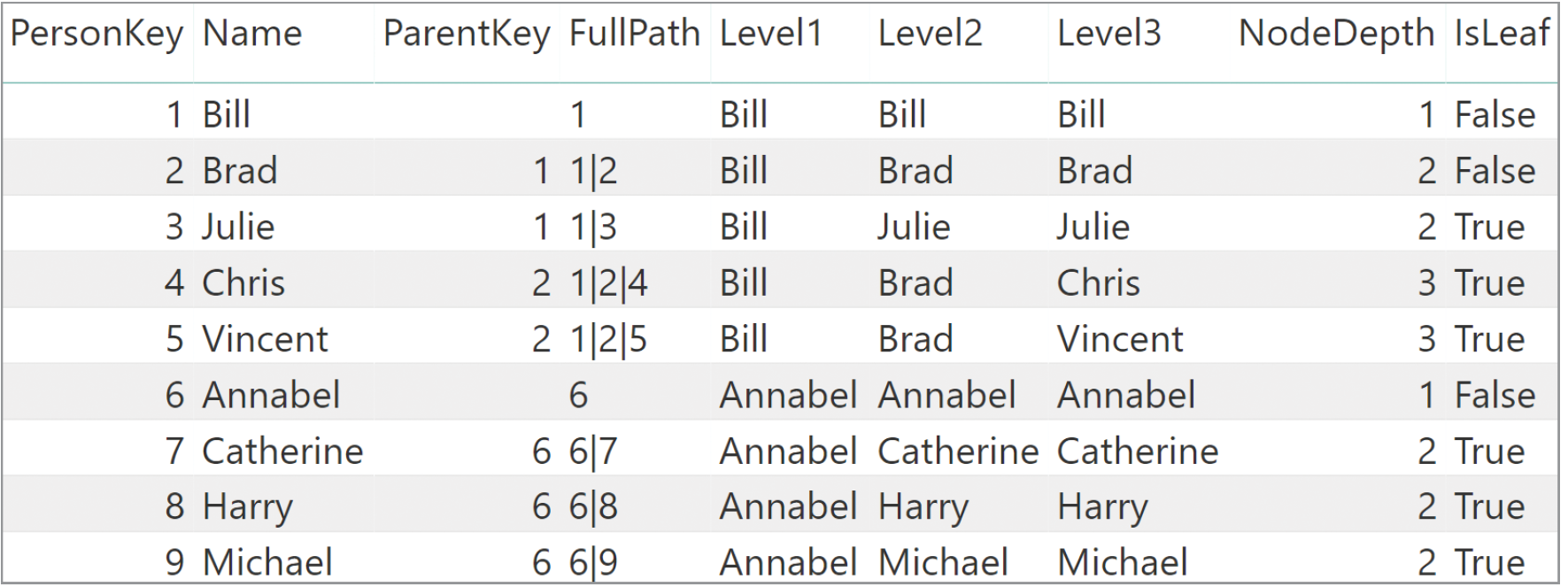
然后基于上表编写好 DAX 代码后,再把所需的行列布局成数据透视表或者矩阵。
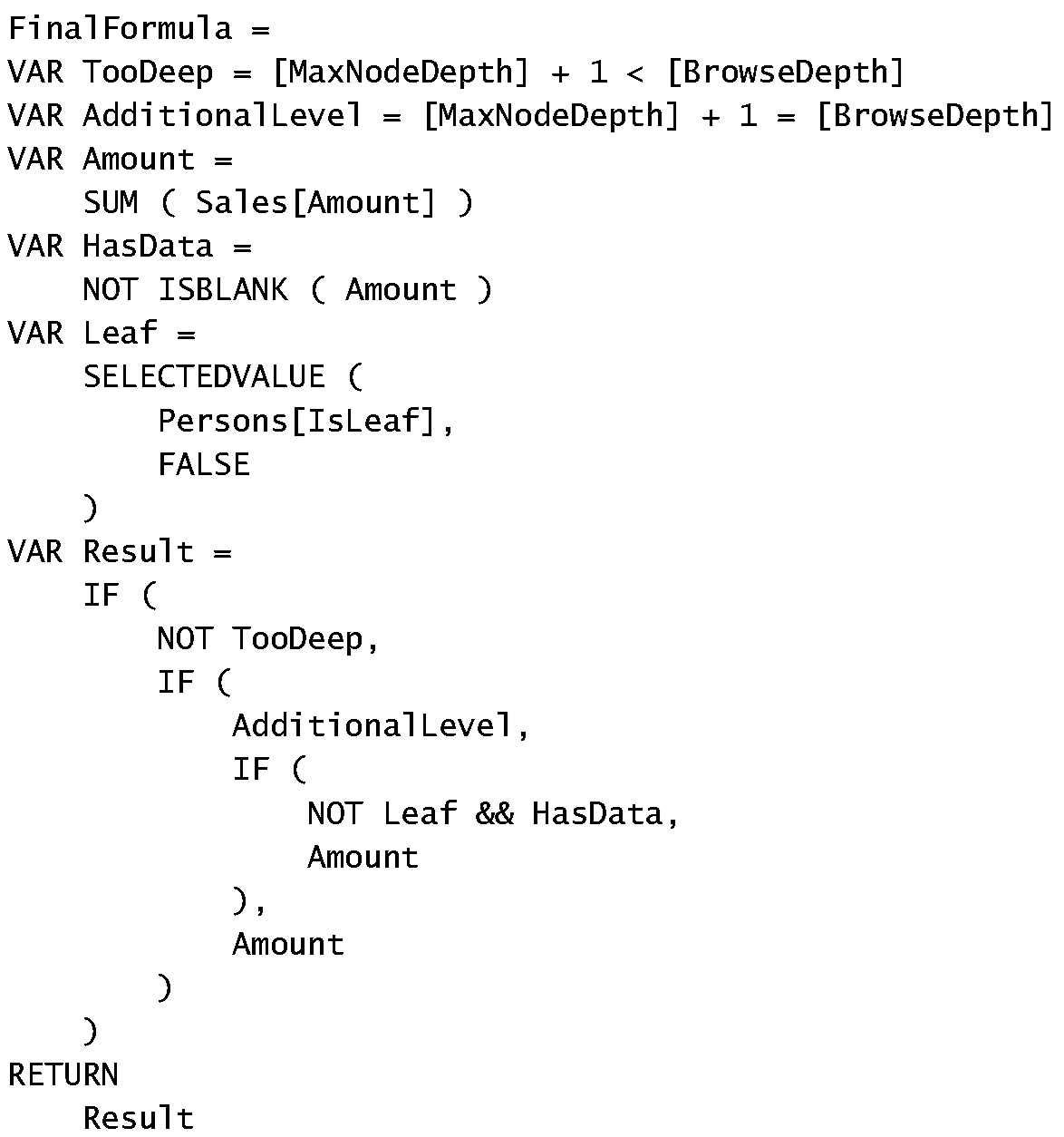
DAX 指南用了将近 11 页来说明这个结构的处理过程,对我来说,这是一个极其烧脑的过程。
相比较而言,SPL 中的 prior 和 nodes 函数可以轻松地处理这种标准父 / 子层级结构。为了方便使用,我把数据和代码复制如下,有兴趣的朋友可以试试。复制代码的时候,最后一句中 fill 函数处双引号之间要敲多一个空格。
| A | B | C | D | E | F | G | |
| 1 | EID | Name | PID | EID | Name | Amount | |
| 2 | 1 | Bill | 2 | Brad | 200 | ||
| 3 | 2 | Brad | 1 | 2 | Brad | 200 | |
| 4 | 3 | Julie | 1 | 3 | Julie | 300 | |
| 5 | 4 | Chris | 2 | 4 | Chris | 400 | |
| 6 | 5 | Vincent | 2 | 5 | Vincent | 500 | |
| 7 | 6 | Annabel | 6 | Annabel | 600 | ||
| 8 | 7 | Catherine | 6 | 7 | Catherine | 600 | |
| 9 | 8 | Harry | 6 | 7 | Catherine | 600 | |
| 10 | 9 | Michael | 6 | 8 | Harry | 400 | |
| 11 | 8 | Harry | 400 | ||||
| 12 | 9 | Michael | 300 | ||||
| 13 | 9 | Michael | 300 | ||||
| 14 | =[A1:C10].record(3) | =[D1:F13].record(3) | |||||
| 15 | =a=A14.pjoin(#1;B14:null,#1,sum(#3):Amt).keys(EID),a.switch(PID,a) | ||||||
| 16 | =a.news((L=~.prior(PID).(EID).rvs(),X=#4+a.nodes(#3,~).sum(#4))|if(#4&&X>#4,#4); fill("",(L.len()+#-2)*5)/Name:Name,L.concat("|"):Level,~:Amt).sort(#2) |
代码很简单,因为 SPL 已经在 prior 和 nodes 函数中封装好了,使用者只要根据函数说明编写代码即可。简单说一下解题的过程:
首先,因为要基于表 1 层级结构布局出结果,所以把表 2 中的数据汇总合并到表 1,此时表 1 跟表 2 是一对多的关系,关联计算时用了 pjoin 函数,看中了 pjoin 可以在一对多时进行聚合处理的功能,这是比较方便的地方。当然,还有其他方法实现,比如先把表 2 分组汇总,然后再和表 1 进行一对一主键关联。殊途同归,至于性能,没有更大量级的数据测试,我也没有那个水平琢磨出来。
然后,把第一列也就是子级所在的列设置为主键,用 switch 函数实现自引用关联。这样后续就可以用 prior 和 nodes 轻松实现层级关系的计算。
唯一麻烦的就是那个缩进以及把本身有值的中间节点也要布局出来,因为有些中间节点有他自己的 Amount,计算的时候要把他本身的一起算上,比如像 Brad 和 Annabel,还得把其自身的值也作为一行布局出来,所以去制造一个两个值的序列,用 news 展开成笛卡尔积。那什么时候需要两个值?代码中的 #4&&X>#4,意思就是有 Amount 值并且累计值大于其本身值,因为叶级的累计值等于其本身值,所以当满足这个条件时的值就是这些中间节点。再一个就是左边部分的缩进量,用了 L.len()+#-2,实际上是 L.len()-1+if(#>1,1),因为最多只有两个值,所以不是 1 就是 2,正好是#-1。
发这个帖子的用意,不是说要分享什么,因为函数都是现成的,递归早就被 SPL 大佬封装好了,我倒是希望大佬们有闲情逸致的时候指点一下,看 SPL 有没有更简洁优雅的实现方式,或者说类似这种场景润乾报表有没有更出彩的解决方案?
就写这么多吧…顺祝大佬们周末愉快😄 🙏


这已经写的非常好了,挺难再简洁了👍
谢谢大佬😄 这得归功于 SPL 函数设计的精妙👍
prior 和 nodes 在这种应用场景中确实够简洁。
大佬啊,excel 有没有办法搞快一些啊,上了行数读取真的好慢😳
市面上貌似没有读 xlsx,xlsb,xls 读的快的,闹心的很。
5 万行 30 列的 excel 能搞进 5 秒我就不纠结了😄
这个得问微软,俺们没有办法。没太多格式问题就用 csv 了,或者干脆用 btx
😄 老贼啊,大神啊,您说的我都知道啊,这不是心有不甘嘛😂
类似的问题我也问过好几回了,不管是魔怔也好、不懂事也罢,因为自己水平不够,只能多问问了…万一问着了呢,念念不忘,总有回响。
SPL 和 btx、ctx 的威力早就见识过了,好用的很。但人心总归是贪的😄 ,只求更快,一样快还不够,想着都要快。
EXCEL 的存量用户太多了,办公几乎是普遍,平时接触到的基本都是 xlsx 格式,甚至还有 xls 格式,没办法,就是这么个现象。
所以一直在找好用一点的方法,转存,总归是多了转这一步。微软系的东西怎么说呢…不说了…没办法。
我找到了一个读 xlsx 相对较快的方法 (DuckDB,一个列存文件数据库),还没测试完,等测试完了,合适的话我看情况发个帖,麻烦您给帮忙看看。🙏
严格地说,我们是用 Java 的开源包 poi 在读写 xls,这个包似乎比 SPL 的包还大,虽然也开源,但也不太可能仔细研究它了,读写 xls 对于 SPL 来讲是个必要但不是非常关键的功能。
如果用 C++ 写,也许能快一点,但 SPL 也没办法利用了。这个问题,除了等待 poi 进化外,也没什么别的办法。自己折腾的成本都太高了。