


查询计算移出数据库用 Java 太慢咋办
很多现代应用会把数据计算和处理任务从数据库移出来采用 Java 实现,这样能获得架构上的好处,而且 Java 有完善过程处理能力,应对日益复杂的业务逻辑比 SQL 更得心应手(虽然代码不短)。不过,我们常常会发现,这些 Java 代码计算和处理数据的性能不如人意,赶不上数据库里的 SQL。
按说,作为编译型语言的 Java,性能虽然赶不 C++,但总该比解释型的 SQL 更有优势才对,但事实却并不是。
这是为什么呢?
主要有两方面的原因。
一个直接的原因是 IO 方面。Java 本身没有通行的存储机制,通常还要继续借助数据库来存储数据,那么在计算时要先从数据库中读出数据,而数据库的访问接口(JDBC)都不是很快,数据量如果较大,读取方面就会吃很大的亏。
那么,能不能不用数据库存储以获得更高的读取性能呢,毕竟大部分数据都是不再改变的历史数据,还在改变的数据量通常比较小,如果换一种高效访问方案来存储冷数据,就只有小量热数据需要临时读取,Java 的运算性能是不是就能大幅提升?
理论上是这样的,但还是上述原因,Java 本身没有通行的存储机制,如果不用数据库,那一般只能用 CSV/TXT 之类的公共格式,这种格式的性能和数据库区别并不大,还存在丢失数据类型信息的风险。如果自己设计一套二进制存储格式,那确实能比数据库快得多,但要把它考虑周全并实现出来,并不是一件容易的事,这超出了许多应用程序员的能力。
于是,Java 程序员仍然是在用数据库或文本文件,忍受低性能的 IO。
另一方面是算法实现。要想跑得快,要想办法让计算量变小,这时候就需要一些采用一些低复杂度的算法。然而,这些算法计算的复杂度是低了,但实现的复杂度却更高了。
比如常见的分组和连接运算,数据库一般都会采用 HASH 算法,而不是直接排序或硬遍历。但这个算法实现难度比较大,又超出了许多应用程序员的能力,结果大家常常还是用比较简单的排序或硬遍历的方法实现,这样计算量会大出数量级,编译型的 Java 比解释型 SQL 跑得慢也就不奇怪了。
内存运算还略好一点,现在也有一些开源类库(但平心而论,方便程度和 SQL 差得很远)。但对于涉及大数据的外存计算,Java 业界几乎没有什么有效支持,这时候连基本的排序都变得很难做了。
还有,要利用多 CPU 的并行能力,就要写出多线程代码。Java 写多线程没问题,但却异常麻烦,程序员要考虑资源共享冲突等各种问题,又会加大实现难度和出错的可能性,结果常常会基于成本权衡后写成单线程,白白浪费 CPU 资源。
那该怎么办?
esProc SPL 来帮你。
esProc SPL 是纯 Java 的开源计算引擎,提供不依赖于数据库但比 SQL 更强大的计算能力。esProc SPL 可以完全无缝地集成进 Java 应用中,就和应用程序员自己写的代码一样,一起享受成熟 Java 框架的优势。
esProc SPL 支持对数据库以及 CSV/TXT 等常见公共文件的访问,这方面的性能和直接 Java 开发差距不大。特别的是,esProc 设计了高性能的二进制文件格式,支持压缩、列存、索引,以及大数据的游标及分段并行机制。将历史大数据存储成二进制文件,不仅能获得远比数据库更高的访问性能,而且还更便于利用文件系统的树形结构进行组织管理。
esProc SPL 的计算能力并不依赖于数据库或其它第三方服务,这样就能轻松实现多种数据源的混合计算。特别地,同时从文件读取冷数据和从数据库读取热数据,可以实现针对全量数据的实时计算,参考 怎样做多数据源的混合计算
esProc SPL 内置了丰富的结构化数据计算类库
Filter:T.select(Amount>1000 && Amount<=3000 && like(Client,"*s*"))
Sort:T.sort(Client,-Amount)
Distinct:T.id(Client)
Group:T.groups(year(OrderDate);sum(Amount))
Join:join(T1:O,SellerId; T2:E,EId)
...
类似数据库,这些类库中一样采用了业界的成熟算法,可以高效运算.
SPL 还支持大数据游标及并行运算,同样采用了成熟算法,而且语法和内存数据表几乎一样:
file("T.btx").cursor@b().select(Amount>1000 && Amount<=3000 && like(Client,"*s*"))
file("T.ctx").open().cursor().groups@m(year(OrderDate);sum(Amount))
...
这样 Java 程序员不必再自己实现这些复杂算法,就能享受到类似于数据库的高性能。
事实上,SPL 提供的结构化数据运算及高性能算法要比 SQL 更多更深入。在许多复杂场景,SPL 实际跑出来的性能会远高于数据库的 SQL,经常能做到单机跑过集群的效果 单机顶集群的大数据技术来了

举个实际的案例:某国际大银行的一个数据处理任务,涉及数据量不大,只有 100 多万行。但业务规则非常复杂,主数据表有 100 多列,每列都有几十种不同的计算规则,用 SQL/ 存储过程写实在过于繁琐混乱,Java 写出来虽然代码不短,但结构要清晰得多,更易于维护。Java 代码总计算时长约 20 分钟,其中读数约 1 分钟。改用 SPL 编写后,读数的 1 分钟不能缩减,但计算时间降到 1.5 分钟,总时长 2.5 分钟,比原先的 20 分钟提高了 8 倍!
这个案例中利用了 SPL 的有序游标技术。因硬件限制,100 万多行数据不能全部加载,只能用游标方式读入,然后要分组后做关联运算,即使使用简单低效的多次遍历关联算法,Java 代码仍然很繁琐。SPL 的有序游标技术,可以在读入时同时把分组处理好,避免了反复遍历关联,代码不足 300 行,性能还有大幅提升。
SPL 也有完善的流程控制语句,像 for 循环,if 分支都不在话下,还支持子程序调用,这和 Java 的过程处理能力是相当的。只用 SPL 就能实现非常复杂的业务逻辑,直接构成完整的业务单元,不再需要上层 Java 程序的代码来配合,主 Java 程序只是简单调用 SPL 脚本就可以了。
SPL 脚本存储成文件,置于主应用程序之外,代码修改可以独立进行且立即生效,不像 Stream/Kotlin 等 Java 类库在修改代码后还要和主程序一起重新编译,整个应用都要停机重启。这样可以做到业务逻辑的热切换,特别适合支持变化频繁的业务。
esProc SPL 还有简洁易用的开发环境,提供单步执行、设置断点、所见即所得的结果预览,开发效率也要好于用 Java 编程: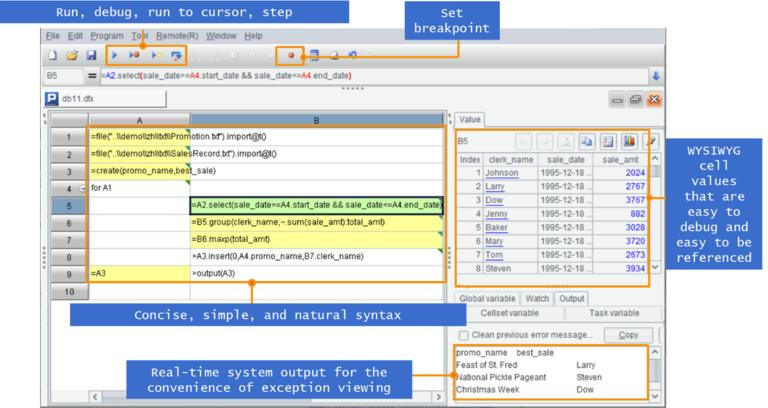
(这里 写在格子里的程序语言 有对 SPL 有更详细的介绍。)
….
SPL 相当于结合了 SQL 和 Java 的优势,即有了 Java 的灵活性和过程控制能力,享受 Java 架构的优势,同时还封装并扩展了 SQL 的算法和存储机制,让程序员在 Java 应用中得到并超越 SQL 的简洁性和高性能。
最后,esProc SPL 在这里 https://github.com/SPLWare/esProc。


英文版