




润乾报表实践:跨数据库的报表
需求描述
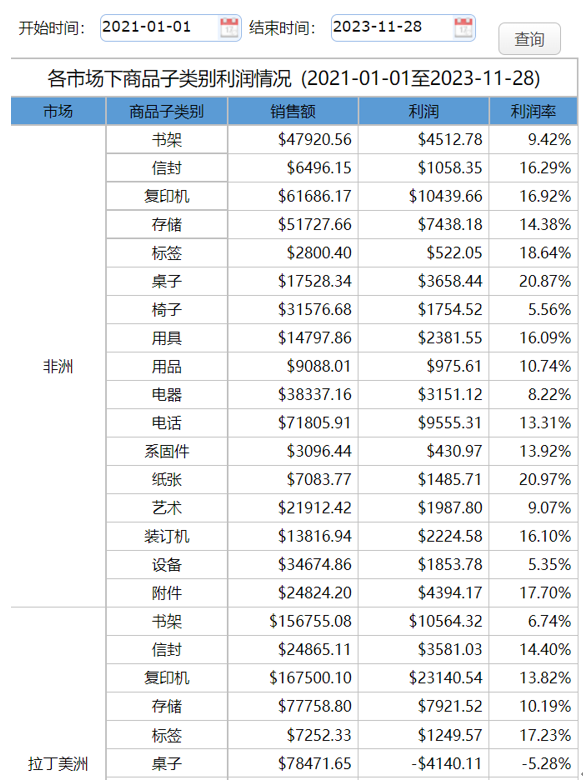
要统计某国际连锁超市,全球各大市场某段时间内各产品子类别的销售额和利润
表样如下,有两个输入参数(开始日期、结束日期)
由于数据量大,数据采用冷热库方式存储,历史数据(当年之前的)放在冷库 HIVE 中,当年数据放在生产库 ORACLE 热库中
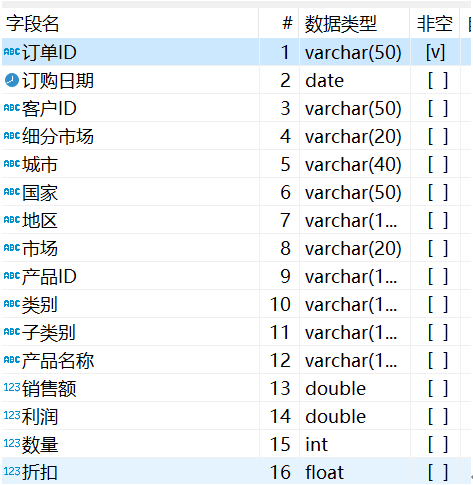
报表数据来源既有生产库 ORACLE 的,也有历史库 HIVE 的,需要制作跨数据库的报表,两库数据结构相同,如下:
问题分析
这个报表格式并不难,难点在于跨库取数,跨库运算一直是个麻烦事,尤其是异构数据库
像上面报表中的数据,分库存储有明显的时间分界线,还需要能控制取数逻辑,(日期统计区间在当年,就只从生产库取数,统计区间在去年及以前的,就只从历史库取数,其他则从两个库一起取)这样才能不浪费数据库的计算资源
报表工具的多数据集,是支持跨库取数的,但控制取数路径以及从两个库中取数后 UNION 都做不好,很多时候都得用 JAVA 数据集来做,就会费时费力
润乾报表基于 SPL 提供了脚本数据集,脚本数据集可以直接针对进行各类异构数据库取数和混合计算,也可以进行取数逻辑判断(数据路由),能很好解决这些问题
实践过程
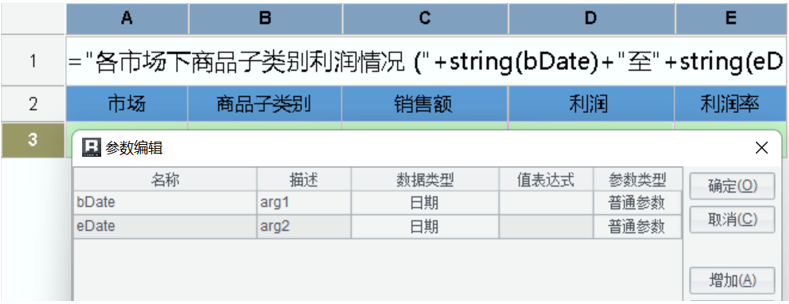
(1)新建报表模板制作基本格式、设置参数(日期类型)
(2)新增、定义脚本数据集,并设置报表取数表达式
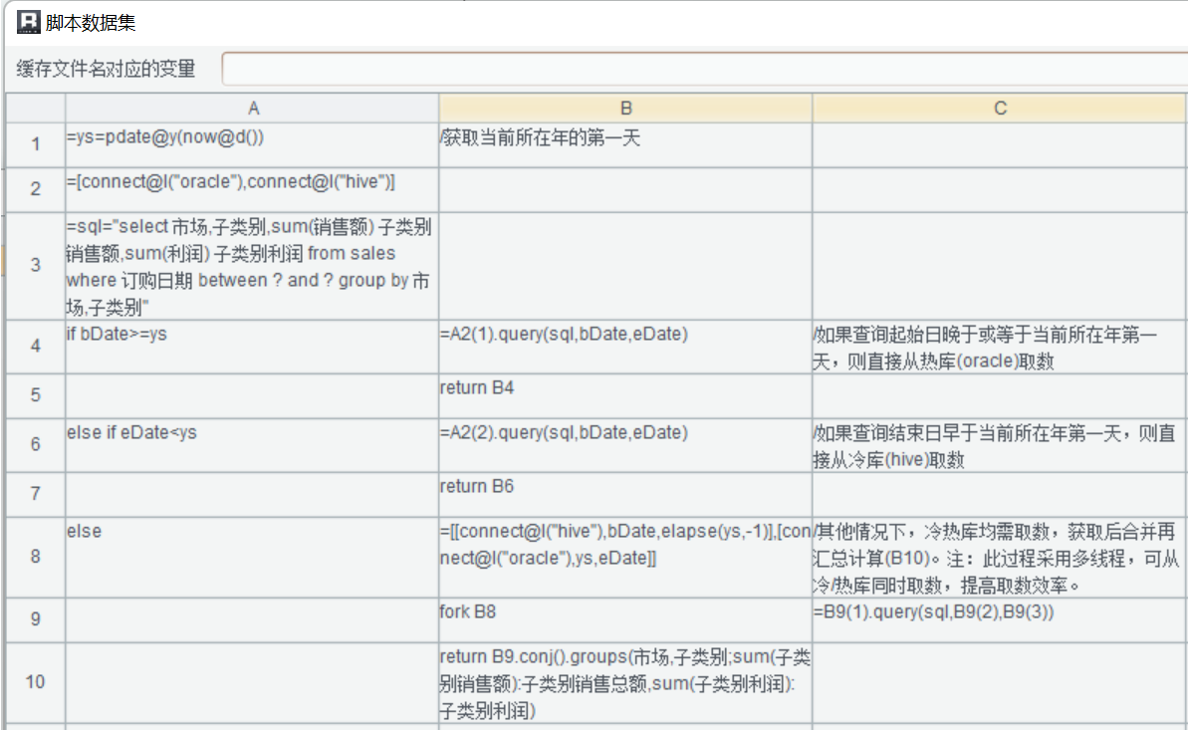
脚本完整文本信息如下:
| A | B | C | |
|---|---|---|---|
| 1 | =ys=pdate@y(now@d()) | / 获取当前所在年的第一天 | |
| 2 | =[connect@l(“oracle”),connect@l(“hive”)] | ||
| 3 | =sql=“select 市场, 子类别,sum(销售额) 子类别销售额,sum(利润) 子类别利润 from sales where 订购日期 between ? and ? group by 市场, 子类别” | ||
| 4 | if bDate>=ys | =A2(1).query(sql,bDate,eDate) | / 如果查询起始日晚于或等于当前所在年第一天,则直接从热库 (oracle) 取数 |
| 5 | return B4 | ||
| 6 | else if eDate<ys | =A2(2).query(sql,bDate,eDate) | / 如果查询结束日早于当前所在年第一天,则直接从冷库 (hive) 取数 |
| 7 | return B6 | ||
| 8 | else | =[[connect@l(“hive”),bDate,elapse(ys,-1)],[connect@l(“oracle”),ys,eDate]] | / 其他情况下,冷热库均需取数,获取后合并再汇总计算 (B10)。注:此过程采用多线程,可从冷 / 热库同时取数,提高取数效率 |
| 9 | fork B8 | =B9(1).query(sql,B9(2),B9(3)) | |
| 10 | return B9.conj().groups( 市场, 子类别;sum( 子类别销售额): 子类别销售总额,sum(子类别利润): 子类别利润 ) |
上面脚本设置步骤为重点步骤!!!
A2 定义了连接两个异构库
A3 定义了一个通用 SQL,因为该报表中的取数逻辑简单,所以这个 SQL 直接在两个库中都可以运行,如果取数复杂并伴有计算,那 SQL 很有可能就不通用了,此时可以用润乾脚本数据集里的“简单 SQL”+sqltranslate 方法,做到一个 SQL 可以适配多个异构数据库的效果,节省更多的工作量,具体实践过程可以参考: 润乾报表实践:可在数据库间移植的报表
B4 B6 B8 为数据路由功能,根据查询日期的区间,判断从单个库还是 2 个库取数
定义报表取数表达式,如下

设计参数模板

查看报表结果:
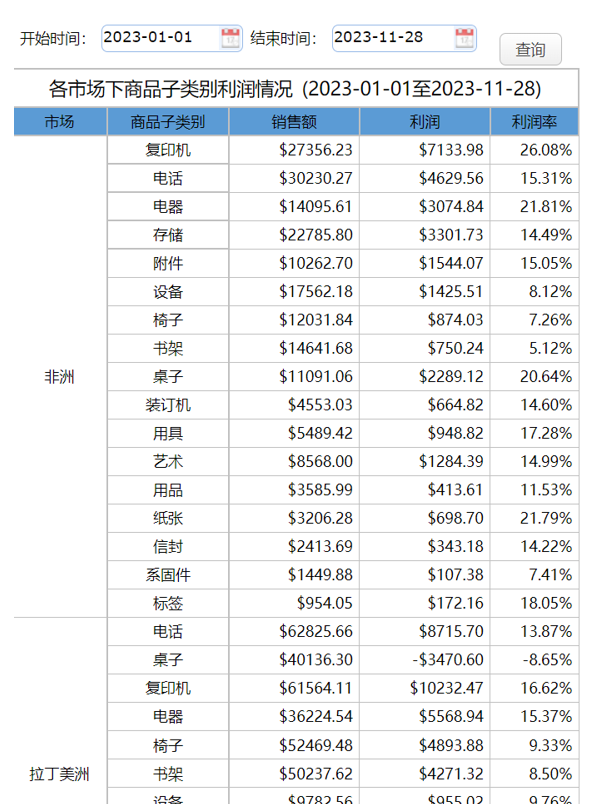
查询开始日期晚于或等于当年首日时(只从 ORACLE 取数)
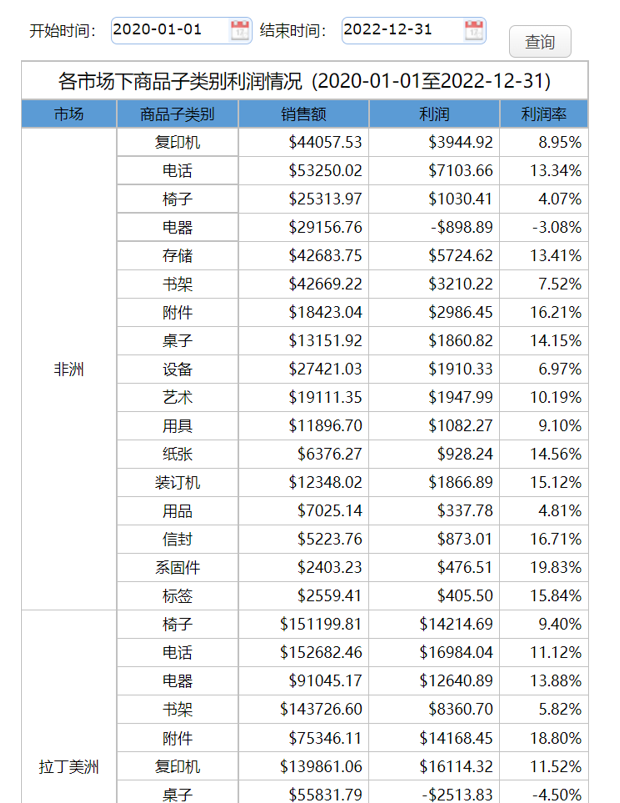
查询结束日期早于当年首日时(只从 HIVE 取数)
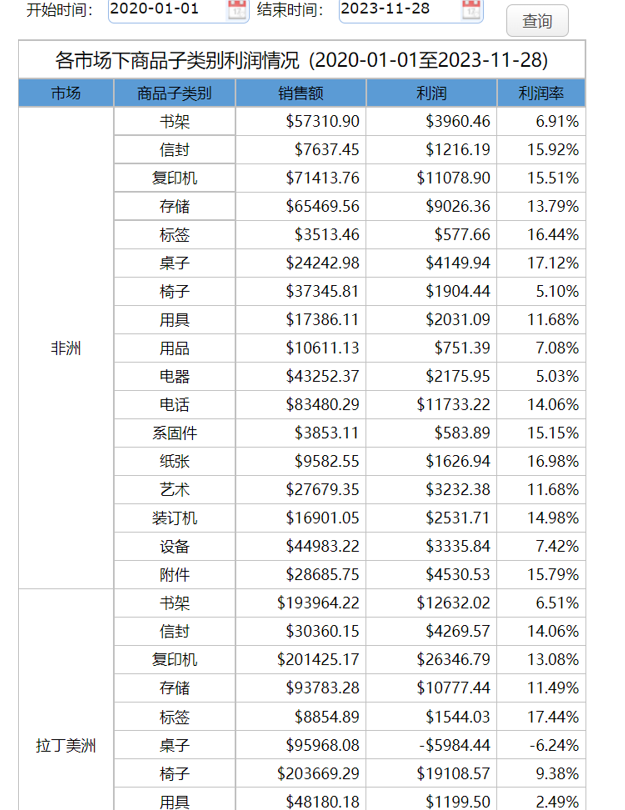
开始日期早于当年首日、结束日期晚于或等于当年首日时(两个库都取)
总结
这类跨库的查询统计报表,或者一些实时的 T+0 报表,很多时候都得用 JAVA 自定义数据集来做,开发复杂度大,润乾报表的脚本数据集可以轻松应对这些跨库的问题,大大降低了开发复杂度,省时省力,润乾报表也很便宜,三万一年随便用,接近于开源软件了,可以很低成本下载实践
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

