


关于实表 T.cursor/T.import 的一点小问题
如题,我在试验实表读取时碰到点小问题,麻烦大佬们看一下是哪里不对。以下涉及到的表均指实表 ctx 格式。
按照函数文档,T.cursor(x:C,…;wi…;k:n) 有三部分参数,最后一部分参数的意思是根据过滤条件 wi,把游标分为 n 段,得到第 k 段游标。T.import(x:C,…;wi,…) 根据实表 T 返回序表,相当于 T.cursor(…).fetch()。同时,文档也有相关的案例说明,就拿 import 函数中倒数第二部分为例子,截图如下:

红色框中描述的很清晰。我按照文档中的意思,自己模拟一个文件测试,其中 SID 字段是自然数序列,用上述两种方法,取出 SID 在 101-120 之间的记录,分成 4 段读取第一段,代码如下:
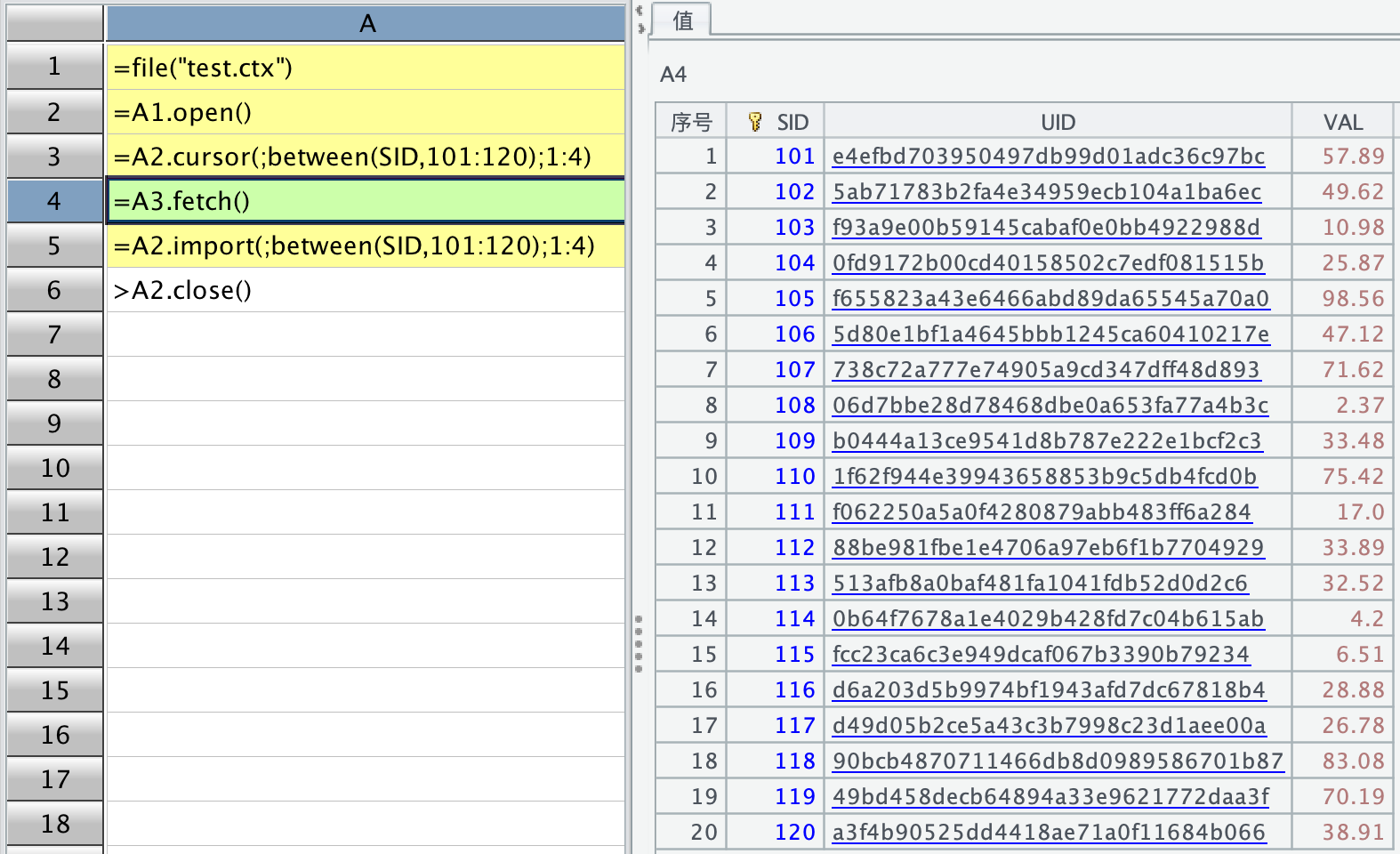
发现一点小问题:
1、按照我的理解,A4、A5 格子中应该只取出 5 条记录,因为总共 20 条记录分成 4 段读取第一段,但结果是取出了 20 条记录,分段并没有起作用;
2、如果把最后的分段写成 2:4 或者 3:4 或者 4:4,代码格从 A4 开始就不会继续往下执行,也没有抛出错误;import 单独写时,亦是如此。只能获取 1:n,且是全部读取;
3、实表.import()函数按照文档来看只有两段参数,( 选取字段; 过滤条件),似乎并没有第三段的分段参数,这个第三参是有还是没有?
以上问题,可能是我哪里的写法不对,也有可能是其它的原因,恳请大佬们得闲时给予指导帮助!
谢谢!!


学习这些东西,要拿实际问题来。面对实际的问题,你才知道要解决啥。
分段是为了解决并行而提高性能。而你现在自己设计的这个问题,是否并行对性能毫无意义,纯粹是理论上的探讨。但程序在实践上,不可能全按你想像的理论来(严格分段…),那样反而可能搞得更慢。
对于这个问题,20 条毫无分段的意义,不可能这么分的,起码弄几百万条甚至几亿条来分。20 条也要被分,只会更慢。分段要以物理块为单位,一个块估计能放下几十万行,小于这个数不会再分了,块内继续分只会更慢,这不能按你想像的理论情况来做。
如果你面临的是实际问题(几亿行),那就不会出现你这种现象了。
它只要达到对于大数据能并行提速的效果就是合理的,分段不可能也没必要做到完全精确(总数 /k),import 这种情况(已经数据量小到能读入内存了),也没多大必要再分段(除非调试,而这时候不在乎性能)。
不要为了学而学,要知道为解决什么问题而学。面对实际的痛点,才能知其所以然。
昨天那个索引也是类似的,你要先想清楚为什么要用索引,碰到什么痛点了不用索引就很难处理了?
早上好,老贼,感谢您的指导🙏 您每天都起那么早,佩服👍
ctx 是 SPL 独有的,从没接触过,我也是对着教程刚开始学 ctx,因为充满好奇,教程上的代码对我来说就像绝招武功,我都照着抄一遍执行一遍,自己再练一遍。照理这些小问题是不应该来麻烦您,但我问东问西问不到结果,上周搞到现在,自己搞不明白,只能发帖求助。
ctx 也是必学的,所以我只能为了学而学,笃信好学,我深信 SPL 是值得花时间学习的。我得先弄清楚基本路数,那实战运用时也会有个比较清晰的方向,不至于临阵抓瞎。
我资质天赋一般,只能多学多问,这些例子我再多看几遍教程,再捋捋。浪费大佬们的时间,深表歉意!🙏
这个问题确实是我草率了,一个是过于想当然,二个是模拟的数据确实需要一定的量级,就像您说的起码得几百万行。我试了从 9 百万行数据中获取 300 万行数据分段,均测试成功。
再次感谢您的指导🙏 Have a nice day!Peace!