


求助:ctx 创建索引文件 icursor 时参数无效
官网文档中有一篇标题是 "组表的访问与复组表" 的文章,其中有部分内容是关于索引的,文章链接和部分截图如下:
http://d.raqsoft.com.cn:6999/esproc/tutorial/zbdfw.html
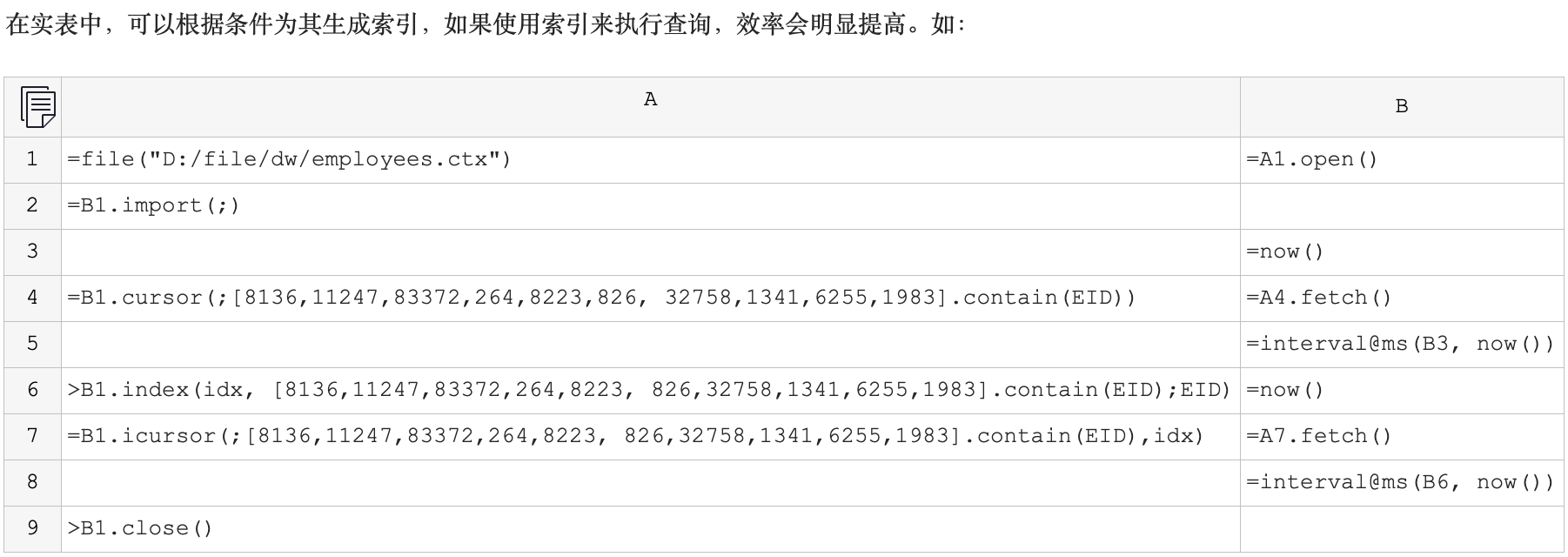
截图中的语句我照抄了一遍,能正常跑出来结果,且 A6 中创建索引的方法在对应的 index 函数文档中好像没有提及。这个先不管,我想求助的是在创建索引时,contain(EID) 这部分里边可不可以是对 EID 字段的表达式,比如变成 contain(处理 EID 字段)。
我创建了另外一个 90 万行 3 列的 test.ctx 文件做实验,代码如下:
| A | |
| 1 | =9e6.new(~:SID,uuid():UID,round(rand()*100,2):VAL).cursor() |
| 2 | =file("test.ctx").create@y(#SID,UID,VAL) |
| 3 | =A2.append@i(A1) |
| 4 | >A2.close() |
我想使用文档中提及的创建索引的方法,查询得到 SID 末尾两位在序列 [36,47,72,64,23,26, 58,41,55,83] 中的记录,代码如下:
| A | |
| 1 | =file("test.ctx").open() |
| 2 | =now() |
| 3 | =A1.cursor(;[36,47,72,64,23,26, 58,41,55,83].contain(SID%100)) |
| 4 | =A3.fetch() |
| 5 | =now() |
| 6 | >A1.index(idx_mod, [36,47,72,64,23,26, 58,41,55,83].contain(SID%100);SID) |
| 7 | =now() |
| 8 | =A1.icursor(;[36,47,72,64,23,26, 58,41,55,83].contain(SID%100),idx_mod) |
| 9 | =A8.fetch() |
| 10 | =now() |
| 11 | =interval@ms(A2,A5) |
| 12 | =interval@ms(A5,A7) |
| 13 | =interval@ms(A7,A10) |
| 14 | >A1.close() |
A3 格子写的是一般的用法,没有创建索引,能得到预期的结果。
A6 格子创建了索引,在主目录下生成了一个名为 "test.ctx__idx_mod" 的索引文件,但 A8 格子执行报错如下:
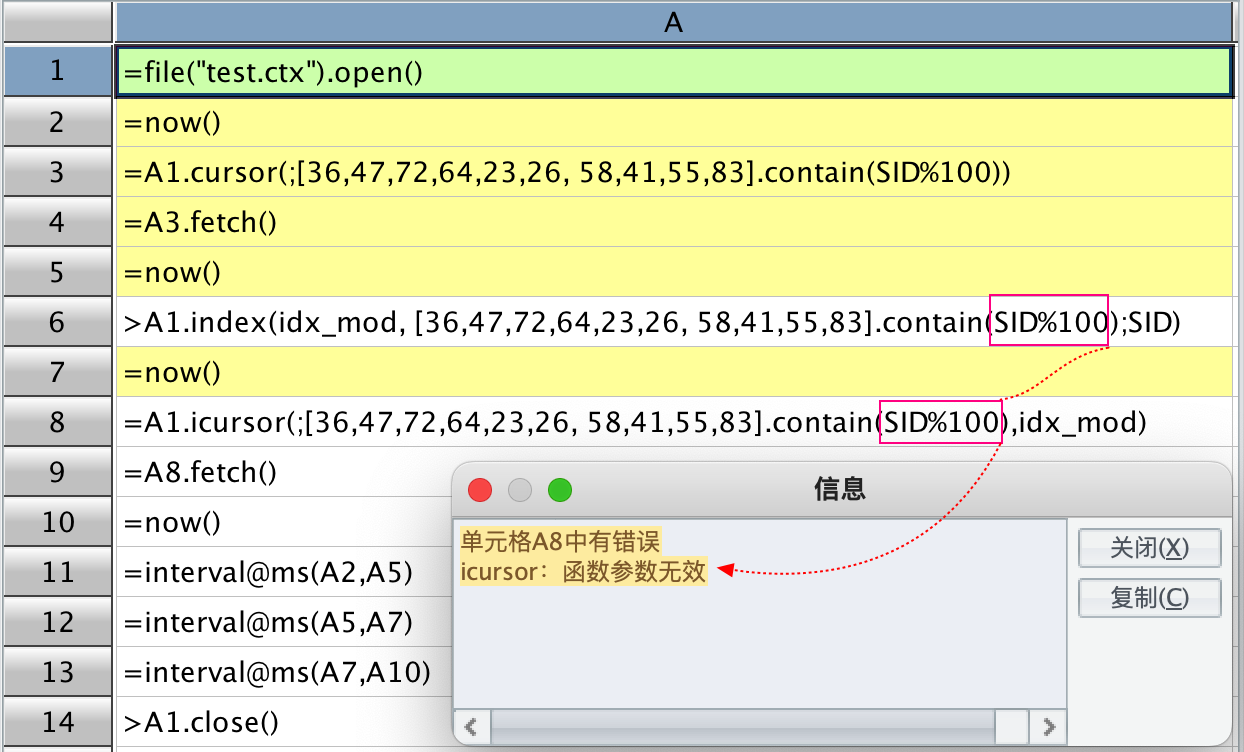
恳请大佬指导解惑:
1、A6 中创建的索引文件对不对?是不是 contain 里不能再对字段进行表达式处理?
2、如果非要用索引文件实现这个写法,该如何写代码?
谢谢!


索引时,contain 里只能是索引字段名。
你可以试试加一列,把 SID%100 做成一个新的列。
感谢回复!
所以:
1、A6 格子中创建索引文件的方法是属于非法用法,或者说,即使生成了索引文件也是无效的?那这样的情况,是不是直接抛出错误还干脆一些?
2、CTX 文件增加一列作为辅助列,相当于还得 update 一遍,这样的用法合适吗?
3、个人愚见,对字段创建表达式索引应该是挺常用的,有时候查询某个字段,并不是实打实的匹配整个字段,也有可能是匹配部分内容,或者进行某些运算后再去匹配,所以 "索引时,contain 里只能是索引的字段名" 有点想不通。PostgreSQL 里好像有通过表达式来创建索引。
4、新增辅助列,还不如用 SID%100==V1||SID%100==V2||…,但匹配值一多这样写就会很繁复了,没有序列.contain(处理字段) 优雅。 当然,也可以用宏的方式写:
1 % 之后是无序的,那个索引就不能用。
2 20 万行基本上只有一块,做了索引读出量也是一样的,没有效果。
3 针对表达式建索引,理论上当然行得通,但实际实现是一回事,还要多造个列出来,而且基本上见不到这种需求,没多大必要。
你先想清为什么要用索引?再说你要解决的问题是不是解决不了。
我也是在尝试按自己的想法写代码,各种写法都尝试一下,才知道是什么样的情况,要不然固守着教程,看着全会,自己一写全废。
其实,试错或者犯错是个好现象,至少说明在学习,在尝试,在做一些新东西 that never done before…
如果一直不犯错,说明什么,要么是固守舒适区不思进取,要么是心态有问题了…. 握艹,整叉劈了,偏离主题了
谢谢老贼指点迷津!
继续学习 SPL!