


没有数据库也能用 SQL
手头有些 csv/xls 文件,比如这样的:


这种数据很适合用 SQL 做查询,但可惜 SQL 只能用在数据库,要安装个数据库并把这些文件导入,为这么个目标搞的整个应用系统都臃肿很多,实在是划不来。要是有什么技术能直接把这些文件当成数据表用 SQL 查询就好了。
没问题,esProc SPL 来帮你。
esProc SPL 是个开源软件,到这里 https://github.com/SPLWare/esProc 找。
esProc 提供了标准的 JDBC 驱动,被 Java 程序引入后,就可以文件使用 SQL 查询了。
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
PrepareStatement st = conn.prepareStatement("$select * from employee.txt where SALARY >=? and SALARY<?");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
在命令行中也可以用 SQL 来查询文件:
esprocx.exe -R select Client,sum(Amount) from d:/Orders.csv group by Client
esProc 提供了相当于 SQL92 标准的 SQL 语法:
select * from orders.xls where Amount>100 and Area='West' order by OrderDate desc
select Area, sum(Amount) from orders.xls having sum(Amount)>1000
select distinct Company from orders.xls where OrderDate>date('2012-7-1')
还有 join:
select o.OrderId,o.Client,e.Name e.Dept from d:/Orders.csv o ,d:/Employees.csv e where o.SellerId=e.Eid
select o.OrderId,o.Client,e.Name e.Dept,e.EId from Orders.txt o left join Employees.txt e on o.SellerId=e.Eid
子查询和 with 都支持:
select t.Client, t.s, ct.Name, ct.address from
(select Client ,sum(amount) s from Orders.csv group by Client)
left join ClientTable ct on t.Client=ct.Client
select * from d:/Orders.txt o where o.sellerid in (select eid from Employees.txt)
with t as (select Client ,sum(amount) s from Orders.csv group by Client)
select t.Client, t.s, ct.Name, ct.address from t left join ClientTable ct on t.Client=ct.Client
其实,esProc 并不是一个专门提供 SQL 语法的产品,它本身有 SPL 语法,SQL 只是在 SPL 的基础上顺便提供的,所以 esProc 可以做到不依赖于数据库执行 SQL。
在 SPL 的支持下,可以进一步拓展这些 SQL 的应用范围,比如支持格式不太规范的文件:
用 | 分隔的文本
select * from {file("Orders.txt").import@t(;"|")} where Amount>=100 and Client like 'bro' or OrderDate is null
没有标题行的文本,用序号表示字段
select * from {file("Orders.txt").import()} where _4>=100 and _2 like 'bro' or _5 is null
读取 Excel 的某个 sheet
select * from {file("Orders.xlsx").xlsimport@t(;"sheet3")} where Amount>=100 and Client like 'bro' or OrderDate is null
还可以查询 json 文件
select * from {json(file("data.json").read())} where Amount>=100 and Client like 'bro' or OrderDate is null
以及从 web 下载来的 json
select * from {json(httpfile("http://127.0.0.1:6868/api/getData").read())} where Amount>=100 and Client like 'bro' or OrderDate is null
SPL 还能访问来自 mongodb,kafka,…的数据,当然普通关系数据库更不在话下。这就可以形成多样数据源上的混合计算能力。
SPL 的能力也远不止于此,esProc 初衷也是提供比 SQL 更强大且方便的运算能力,而 SQL 语法一定程度地限制了查询的描述,只能适应于相对简单的场景。
比如这个任务,计算一支股票最长连续上涨的天数,SQL 要写成多层嵌套,冗长且难懂:
select max(ContinuousDays) from (
select count(*) ContinuousDays from (
select sum(UpDownTag) over (order by TradeDate) NoRisingDays from (
select TradeDate,case when Price>lag(price) over ( order by TradeDate) then 0 else 1 end UpDownTag from Stock ))
group by NoRisingDays )
同样的计算逻辑,用 SPL 写起来要简单得多:
Stock.sort(TradeDate).group@i(Price<Price[-1]).max(~.len())
esProc 还有所见即所得的 IDE,调试代码也远比 SQL 方便:
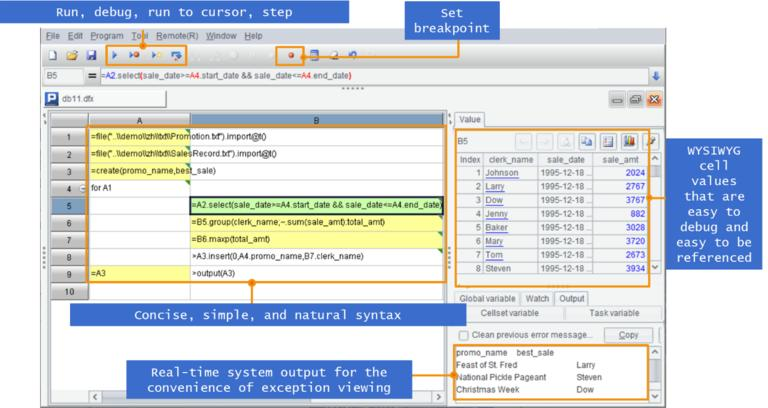
阅读这里 写在格子里的程序语言 ,可以对 SPL 有更多的理解,它可以取代几乎所有的数据库计算能力,还要更强大得多。


英文版