


比 ORACLE 快 N 倍不稀奇,这么轻才是王道
Oracle 是普遍使用的数据库,它不是专业的分析型数据库,在数据量较大时常常会计算性能不佳,影响用户体验。现在有不少新的分析型数据库在性能上比 Oracle 更快,甚至可以说远超。那么在 Oracle 性能不足时,替换成这些数据库看起来就能解决问题了。
事情却没这么简单。
首先,这些新数据库通常并不能完全替代 Oracle。Oracle 并不只是用于 OLAP,还会用于 OLTP,而这些跑得更快的分析数据库并没有 OLTP 的能力(支持 OLTP 的新数据库,包括 HTAP 鼓吹者,如果不借助更大的集群,却未必能比 Oracle 跑得快了),于是就要和 Oracle 共存,摆上两个数据库。
退一步讲,即便当前的 Oracle 只用于 OLAP,也不见得能被完全替代。Oracle 对复杂 SQL 的支持相当好,优化也做得很好,之所以慢,主要是因为同时要支持 OLTP,无法采用列存。这些新数据库如果占不到列存便宜时(全表大部分列都要被引用到),面对很多复杂 SQL 时,因为优化经验不足,在同样硬件资源下还不见得跑得过 Oracle,经常也要借助集群才行。另外,Oracle 还有超强的存储过程功能,这也是很多新数据库欠缺的能力,如果应用中有这类运算,也仍然要继续用 Oracle 了。
不能全部替代,就意味着需要有两套数据库,各自做各自擅长的运算,总体看起来用户体验能变得更好。
再退一步讲,即便新数据库在功能性能上都能完全替代 Oracle,那还有一个迁移风险的问题。对于,实际正在跑的业务,也不敢贸然全部迁到新数据库上,一般也要采用两库并存逐步迁移的方案。
所以,采用更好性能的新数据库,几乎一定会出现两个数据库的现象。
然而,两个数据库无论怎么看都是个非常沉重的事情,架构变得复杂,部署运维也麻烦很多,这都意味着成本剧增。如果采用的新数据库还需要分布式部署,那就更会沉重,甚至比原来的 Oracle 还沉重(大多数 Oracle 是单机运行的)。
还有商务问题,使用 Oracle 的通常是高端商用用户,一般也会采购商用数据库,这是一笔不菲的成本。这类用户对引入新数据库这类架构调整的事务也非常谨慎,很难做到随时扩容,经常会一次性买够数年的容量,这在前期又会造成浪费。
总之就是,贵贵贵!
还能有什么办法呢?
用轻量级的 esProc SPL!
esProc SPL 也可以轻松跑出 N 倍于 Oracle 的计算性能,以下是一份 TPCH 100G 的测试结果(时间单位是秒):
esProc SPL |
StarRocks |
ClickHouse |
Oracle |
|
q1 |
9.7 |
14.0 |
15.4 |
114.3 |
q2 |
1.3 |
0.6 |
17.3 |
1.9 |
q3 |
8.8 |
9.8 |
内存溢出 |
165.8 |
q4 |
4.9 |
5.7 |
内存溢出 |
158.4 |
q5 |
8.9 |
13.1 |
内存溢出 |
174.5 |
q6 |
4.5 |
3.9 |
4.8 |
126.7 |
q7 |
10.5 |
12.4 |
内存溢出 |
181.5 |
q8 |
6.9 |
8.3 |
内存溢出 |
209.7 |
q9 |
16.8 |
21.3 |
内存溢出 |
256.0 |
q10 |
8.3 |
11.1 |
58.3 |
195.6 |
q11 |
0.9 |
1.3 |
6.7 |
8.7 |
q12 |
4.9 |
4.8 |
10.7 |
186.0 |
q13 |
12.1 |
21.3 |
134.1 |
33.3 |
q14 |
3.3 |
4.6 |
10.2 |
170.0 |
q15 |
4.7 |
7.1 |
11.2 |
161.8 |
q16 |
2.7 |
2.9 |
4.0 |
10.8 |
q17 |
5.3 |
4.2 |
44.6 |
156.5 |
q18 |
6.4 |
20.8 |
内存溢出 |
416.8 |
q19 |
5.8 |
6.0 |
>600 |
144.1 |
q20 |
5.2 |
5.2 |
31.2 |
171.0 |
q21 |
11.9 |
14.5 |
语法错误 |
360.7 |
q22 |
2.5 |
1.9 |
8.4 |
37.7 |
总计 |
146.3 |
194.8 |
- |
3441.8 |
可以看出,因为不是专业的分析型数据库,Oracle 的计算性能确实不占优,但功能全面,所有题都能跑出来。详细测试报告可参考 SPL 计算性能系列测试:TPCH 。
esProc SPL 严格地说并不是一个数据库,而是个专业的计算引擎。它直接使用文件存储数据,支持自有的列存格式文件,并提供有现代数据仓库中常用的高性能算法,这样,只要把数据转换成这些格式的文件就可以高性能计算。esProc 没有“库”的概念,也就没有入库出库和库内库外的说法。数据文件可以按目录存放,随意搬动以及冗余,甚至可以放到云上,管理非常自由方便,运维复杂度远远低于数据库。
这是轻量的存储。
esProc 提供了类似数据库的 JDBC 驱动供上层应用调用:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = conn.createStatement();
ResultSet result = statement.executeQuery("=T(\"Orders.btx\").select(Amount>1000 && like(Client,\"*s*\")
和常规数据库不同之处在于,作为纯 Java 程序,esProc 可以完全无缝地嵌入到 Java 应用中执行。整个计算引擎都被内置于 JDBC 驱动包中,而不像数据库那样还需要有个独立服务器进程,esProc 核心包还不到 15M,加上各种第三方数据源驱动也就数百 M,甚至可以在安卓上流畅运行。esProc 就和程序员自己写的代码一样,打成一个大包,运行在同一进程内,一起享受成熟 Java 框架带来的架构优势。这相当于 esProc 把原本数据仓库才有的计算能力移进了应用程序内部。
这是轻量的部署。
esProc 没有再采用 SQL,而是有一套自己发明的程序语言 SPL。SPL 拥有 SQL 的所有运算能力:
Orders.sort(Amount) // 排序
Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // 过滤
Orders.groups(Client; sum(Amount)) // 分组
Orders.id(Client) // 去重
join(Orders:o,SellerId ; Employees:e,EId) // 连接
...
对于复杂的运算,SPL 会比 SQL 方便得多。比如这个任务,计算一支股票最长连续上涨的天数,SQL 要写成多层嵌套,冗长且难懂:
select max(ContinuousDays) from (
select count(*) ContinuousDays from (
select sum(UpDownTag) over (order by TradeDate) NoRisingDays from (
select TradeDate,case when Price>lag(price) over ( order by TradeDate) then 0 else 1 end UpDownTag from Stock ))
group by NoRisingDays )
同样的计算逻辑,用 SPL 写起来要简单得多:
Stock.sort(TradeDate).group@i(Price<Price[-1]).max(~.len())
这是轻量的代码。
轻量并不意味着功能弱,相反,esProc SPL 的功能比许多新数据库更强大:
SPL 有完善的流程控制语句,像 for 循环,if 分支都不在话下,还支持子程序调用,这就能实现存储过程的能力了;而很多新数据的存储过程能力都很弱甚至没有。
SPL 支持丰富的外部数据源,这样可以方便地实现多数据源计算,比如 Oracle 和 Restful 混合计算,特别地,基于文件中的冷数据和 Oracle 中的热数据混合计算,可以轻松实现 T+0 的统计;而由于数据库的封闭性,混合计算一向是个老大难问题。
SPL 有比 SQL 更丰富的高性能算法,能够更充分地利用硬件资源,经常能用单机跑出分布式数据仓库集群的效果,参考: 单机顶集群的大数据技术来了 。
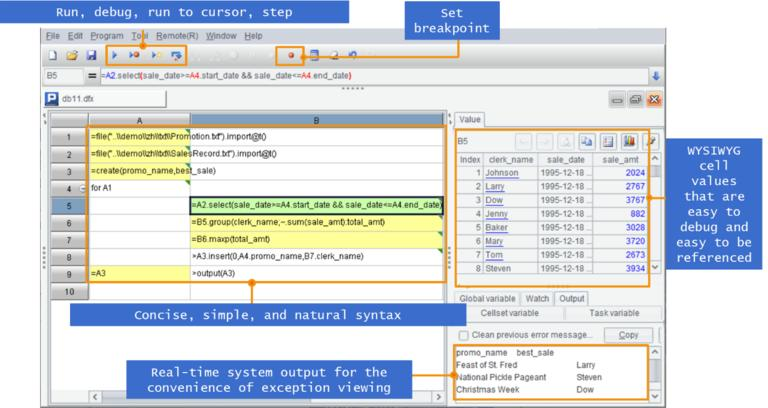
esProc SPL 还有简洁易用的开发环境,提供单步执行、设置断点、所见即所得的结果预览,开发效率要远高于 SQL 和存储过程:
(这里 写在格子里的程序语言 有对 SPL 有更详细的介绍。)
最后,esProc SPL 是开源免费的。在这里 https://github.com/SPLWare/esProc


英文版