


ORM 技术的终结者
Hibernate,Mybatis 以及新兴的 JOOQ 等 ORM 技术能够方便地将数据库表映射成 Java 对象,并提供自动读写能力。ORM 技术使得用 Java 开发数据库应用变得更为高效。
不过,映射数据表仅仅是最基础的一环,业务逻辑的开发还会涉及很多流程控制和数据计算的工作。流程控制是 Java 的强项,没什么压力;但批量结构化数据计算却一直是 Java 的弱项,直接用 Java 编程会非常繁琐。
遗憾的是,这些 ORM 技术提供的计算能力也不如人意。Hibernate 几乎完全依赖于从 HQL 转换出 SQL,而 HQL 只能对应 SQL 的一个很小子集,计算能力严重不如;JOOQ 要强很多,以 Java 风格提供了不少基础运算,比如过滤、分组等,这也是近年来它能超越 Hibernate 的原因之一,但代码的简洁程度仍然比不上 SQL。
在 Java 下开发数据库应用,esProc SPL 是个更好的选择。
esProc SPL 是个 Java 编写的开源软件,因为是纯 Java 软件,esProc 可以和 ORM 一样被完全无缝地集成进 Java 应用中,一起享受成熟 Java 框架的优势。
与 ORM 技术不同,esProc 基于 JVM 提供了一种新的程序语言 SPL 用于编程,而不是直接使用 Java。SPL 脚本通过 esProc 提供的 JDBC 接口被 Java 程序调用,就像调用数据库 SQL 或存储过程一样。
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = conn.createStatement();
ResultSet result = statement.executeQuery("=T(\"Orders.csv\").select(Amount>1000 &&
like(Client,\"*s*\")
为什么要设计一种新的程序语言而不直接封装成 Java API 呢?
Java 是编译型的静态语言,在这个基础上很难实现动态数据结构和便捷的 Lambda 语法,而这又是结构化数据运算中特别常见的,也是 SQL 的优势所在。
SQL 中任何一个 SELECT 语句都会产生一个新的数据结构,可以随意添加删除字段,而不必事先定义结构(类),这在结构化数据运算中家常便饭。但 Java 这类语言却不行,在代码编译阶段就要把用到的结构(类)都定义好,可以认为不能在执行过程中动态产生新的类(Java 理论上支持动态编译,但复杂度太大)。如果用一个专门的类来表示所有数据表,把字段名也作为类的数据成员,这又不能直接使用类的属性语法来引用字段,代码非常麻烦。
Lambda 语法是在 SQL 中大量使用,比如 WHERE 中的条件,本质上就是个 Lambda 表达式。Java 这种静态语言虽然现在也支持 Lambda 语法,但方便程度远远不如 SQL。每次书写时还是要有个函数头定义来告诉编译器现在要写 Lambda 函数了,代码看着很乱。在 Lambda 函数中也不能直接引用数据表的字段名,比如用单价和数量计算金额时,如果用于表示当前成员的参数名为 x,则需要写成 "x. 单价 *x. 数量" 这种啰嗦的形式。而在 SQL 中可以更为直观地写成 "单价 * 数量"。
解释型的动态语言才能实现 SQL 的这些特征,可以随时生成新的数据结构,也可以根据宿主函数本身决定当前参数是不是 Lambda 函数,从而没必要写个定义头,更可以根据上下文正确引用未写表名的字段。
SQL 是解释型动态语言,SPL 也是。Java 不是,所以用 Java 很难写出简洁的代码,无论怎样提供 API 都不行。
在解释型动态语言基础上,SPL 提供了比 SQL 更完善的结构化数据对象(表、记录、游标)和更丰富的计算函数,包括 SQL 中有的过滤、分组、连接等基本运算,还有 SQL 中缺失的有序、集合等运算。所以,SPL 代码通常会比 SQL 更简洁易维护,比 ORM 基础上的 Java 代码就更强得多。下面是一些简单对比(这里只用计算能力最强的 JOOQ 举例):
过滤
SQL: select * from Orders where ((SellerID=2 and Amount<3000) or (SellerID=3 and Amount>=2000 and Amount<5000)) and year(OrderDate)>2010
SPL: Orders.select( ((SellerID==2 && Amount<3000) || (SellerID==3 && Amount>=2000 && Amount<5000)) && year(OrderDate)>2010)
JOOQ: context.select().from(ORDERS)
.where(((ORDERS.SELLERID.equal(2).and(ORDERS.AMOUNT.lessThan(3000.0)))
.or((ORDERS.SELLERID.equal(3).and(ORDERS.AMOUNT.greaterOrEqual(2000.0)
.and(ORDERS.AMOUNT.lessThan(5000.0)))))).and(year(ORDERS.ORDERDATE).greaterThan(2012)))
.fetch();
分组
SQL: select Client, extract(year from OrderDate) y,count(1) cnt from Orders group by Client, extract(year from OrderDate) having amt<20000
SPL: Orders.groups(Client,year(OrderDate):y;sum(Amount):amt,count(1):cnt).select(amt<20000)
JOOQ: context.select(ORDERS.CLIENT,year(ORDERS.ORDERDATE).as("y"),sum(ORDERS.AMOUNT).as("amt"),count(one()).as("cnt"))
.from(ORDERS)
.groupBy(ORDERS.CLIENT,year(ORDERS.ORDERDATE))
.having(field("amt").lessThan(20000)).fetch();
更复杂一些的任务,比如这个任务,计算一支股票最长连续上涨的天数。这时候用 SQL 写就繁琐很多,而且很难难懂:
select max(ContinuousDays) from (
select count(*) ContinuousDays from (
select sum(UpDownTag) over (order by TradeDate) NoRisingDays from (
select TradeDate,case when Price>lag(price) over ( order by TradeDate) then 0 else 1 end UpDownTag from Stock ))
group by NoRisingDays )
JOOQ 也要运用窗口函数,写出来比 SQL 更复杂:
WindowDefinition woDay1 = name("woDay").as(orderBy(Stock.TradeDate));
Table<?>T0 = table(select(Stock.TradeDate.as("TradeDate"),when(Stock.Price.greaterThan(lag(Stock.Price).over(woDay1)),0).otherwise(1).as("risingflag")).from(Stock).window(woDay1)).as("T0");
WindowDefinition woDay2 = name("woDay1").as(orderBy(T0.field("TradeDate")));
Table<?>T1=table(select(sum(T0.field("UpDownTag").cast(java.math.BigDecimal.class)).over(woDay2).as("NoRisingdDys")).from(T0).window(woDay2)).as("T1");
Table<?>T2=table(select(count(one()).as("ContinuousDays")).from(T1).groupBy(T1.field("NoRisingDays"))).as("T2");
Result<?> result=context.select(max(T2.field("ContinuousDays"))).from(T2).fetch();
同样的计算逻辑,而用 SPL 就非常简单:
Stock.sort(TradeDate).group@i(Price<Price\[-1\]).max(~.len())
方便地读写数据库是 ORM 技术的基本功能,这方面 SPL 当然也没有问题:
Hibernate:
String hql ="from OrdersEntity where sellerId=10";
Query query = session.createQuery(hql);
List<OrdersEntity> orders = query.list();
Transaction tx = session.beginTransaction();
for ( int i=0; i<orders.size(); i++ ) {
session.save(orders.get(i));
}
tx.commit();
JOOQ:
java.sql.Connection conn = DriverManager.getConnection(url, userName, password);
DSLContext context = DSL.using(conn, SQLDialect.MYSQL);
Result<OrdersRecord> R1=context.select().from(ORDERS).fetchInto(ORDERS);
R1.forEach(r->{r.setValue(ORDERS.AMOUNT,r.getValue(ORDERS.AMOUNT).doubleValue()+100);});
R1.forEach(r->{r.update();});
SPL:
T=db.query("select * from test.Orders where sellerId=?",10)
db.update(T,orders)
db.commit()
这些功能区别不大,SPL 因为有前述的语言方面优势,仍然更简单一点。
SPL 本身有完善的流程控制语句,像 for 循环,if 分支都不在话下,还支持子程序调用。只用 SPL 就能实现非常复杂的业务逻辑,直接构成完整的业务单元,不需要上层 Java 代码来配合,主程序只要简单地调用 SPL 脚本就可以了。这相当于把存储过程从数据库中移到了 Java 中。
SPL 是纯 Java 程序,它可以被 Java 调用,也可以调用 Java。这样即便有个别用 SPL 不易实现而要使用 Java 实现的代码(比如某些对外的接口)或者已经有的现成 Java 代码,也都可以再集成进 SPL 中。SPL 脚本和主 Java 应用程序可以融为一体。
作为解释型语言,SPL 脚本可以存储成文件,置于主应用程序之外,代码修改可以独立进行且立即生效,不像基于 ORM 技术写的代码在修改后还要和主程序一起重新编译,整个应用都要停机重启。这样可以做到业务逻辑的热切换,特别适合支持变化频繁的业务。

SPL 支持的数据源也很丰富,无论关系数据库还是 NoSQL 或者 Kafak、Restful,无论是常规二维表还是多层次的 json,SPL 都可以计算直接读取后处理。而 ORM 技术一般只能针对关系数据库,无法直接支持其它数据源了。

非常特别地,SPL 代码写在格子里,这和通常写成文本的代码很不一样。独立的开发环境简洁易用,提供单步执行、设置断点、所见即所得的结果预览,调试开发也比 Java 更方便。
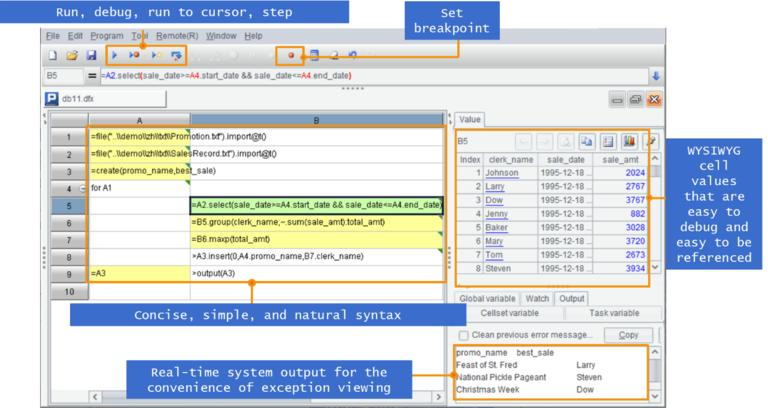
这里 写在格子里的程序语言 有对 SPL 有更详细的介绍。
最后,esProc SPL 在这里 https://github.com/SPLWare/esProc 。


英文版