


存储过程何去何从
存储过程是个让人爱恨交加的东西。
它的意义自不必提,各大老牌数据库都支持,而且经常以此来挤兑一些还不支持存储过程的新数据库。反过来,它的缺点也很明显,能见到很多开发团队在努力拆除存储过程,在应用程序中实现所有的业务逻辑。
那么存储过程到底该何去何从?
存储过程的优点主要在于为 SQL 增加过程化能力。SQL 只能写成单句,但有些逻辑需要多步才能完成,复杂时还会出现分支循环,用单句的 SQL 就很难写甚至写不出来,存储过程也就应运而生了。
存储过程的缺点主要在架构层面。业务逻辑分拆到应用和数据库两处,要两边维护,不仅麻烦,还可能不一致。数据库中的存储过程也无法跟随现代应用架构实现扩展。各种数据库的存储过程语法大相径庭,经常还要维护多个版本。编译存储过程还需要较高的数据库权限,这又产生安全隐患和高效开发之间的矛盾。
开发应用的高级程序语言天然支持过程化,如果把业务逻辑都实现在其中,只是用 SQL 做基本的数据读写,就会同时获得存储过程的好处且避免掉它的缺点了。这不是两全其美吗?
话是这么说,拆除存储过程的同学们也是这么想的,但事情并没这么简单。
实现业务逻辑时,应用层并不是只要控制流程就可以了,它一样要参与数据处理,因为很多业务流程和数据强相关。而 Java 等高级程序语言没有完善的结构化数据类型和基础运算,用来做很多数据处理远没有 SQL 方便,结果写出来的代码非常繁琐冗长,尽管有了架构上的好处,但开发效率以及可维护性降低了很多。
Python 比 Java 略好一点,但仍然不如 SQL 顺手。而且,除非整个应用是 Python 写的,否则它糟糕的集成性又会导致新的架构问题。
esProc SPL 是个更好的选择。
esProc SPL 是纯 Java 的开源软件,它可以完全无缝地集成进 Java 应用中,就和应用程序员自己写的代码一样,一起享受成熟 Java 架构的优势。
esProc SPL 提供完善的结构化数据类型和丰富的计算函数,包括过滤、分组、连接等基本运算,完全覆盖 SQL 的内容,通常会比 SQL 写起来更简单。这些基本类库全是在 esProc 内自行实现,不像 ORM 技术那样还依赖于数据库。用 SPL 写出来的业务逻辑不依赖于数据库,天然具有可移植性。而且,SPL 还有用于转换 SQL 语句的方法 怎样写出可在各种数据库间移植的 SQL 语句 ,代码中必要的基本 SQL 语句也很容易被移植。
SPL 也有完善的流程控制语句,像 for 循环,if 分支都不在话下,还支持子程序调用,这就能实现存储过程的过程化能力了。只用 SPL 就能实现非常复杂的业务逻辑,直接构成完整的业务单元,不再需要上层主应用程序的代码来配合,主程序只是简单调用 SPL 脚本就可以了,方法也确实和调用数据库存储过程一样。
SPL 脚本可以存储成文件,和应用程序放在一起维护,这样就解决了业务逻辑两边维护可能导致的不一致问题。SPL 代码置于数据库之外,这相当于实现了 “库外”的存储过程 ,修改时完全不涉及数据库的任何权限,不存在安全隐患,
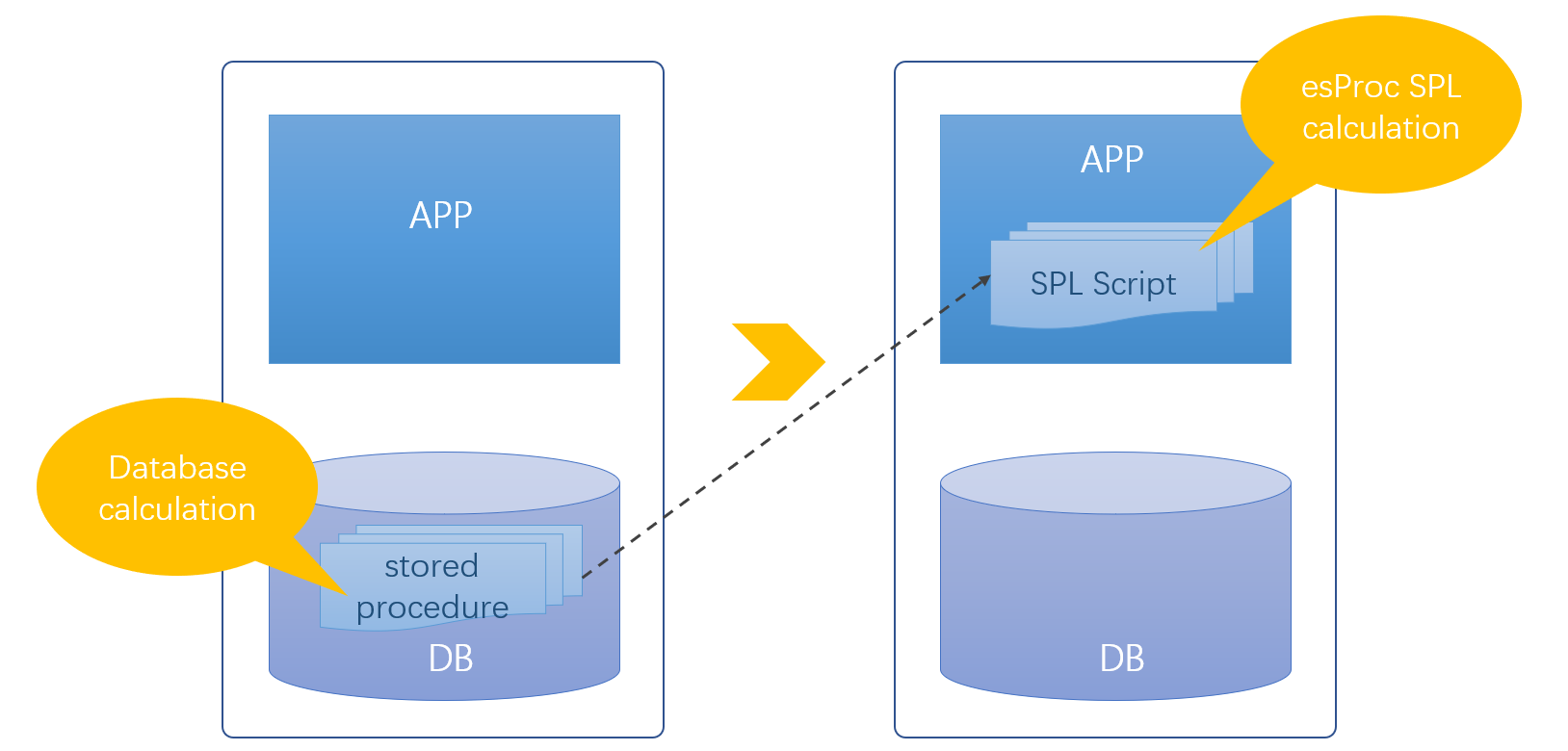
特别是,SPL 是解释执行语言,代码修改后立即生效,不像 Stream/Kotlin 等 Java 类库在修改代码后还要和主程序一起重新编译,整个应用都要停机重启。这样可以做到业务逻辑的热切换,特别适合支持变化频繁的业务。

我们再来看看 SPL 还有什么其它特点:
SPL 代码写在格子里,这和通常写成文本的代码很不一样。独立的开发环境简洁易用,提供单步执行、设置断点、所见即所得的结果预览,开发效率更高。而存储过程的调试就太麻烦了。
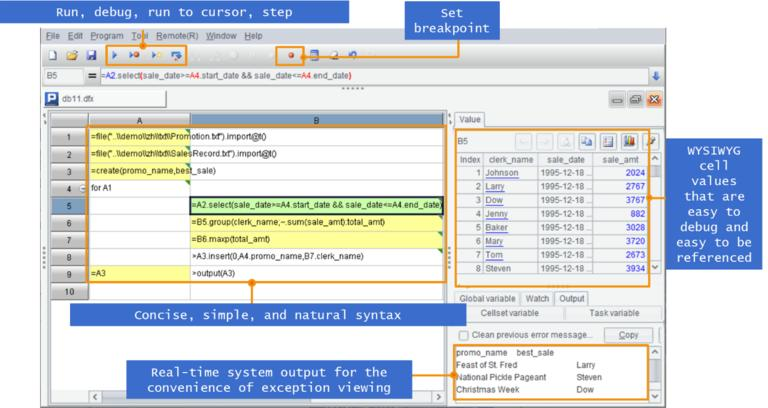
这里 写在格子里的程序语言 有对 SPL 有更详细的介绍。
SPL 提供了比 SQL 更丰富的数据对象和计算库,代码通常会比存储过程中的 SQL 还要简洁很多,进一步提升开发效率和降低维护成本。
比如:找出销售额占到一半的前 n 个客户,并按销售额从大到小排序。SQL 写出来是这样的:
with A as (select client,amount,row_number() over (order by amount) ranknumber from sales)
select client,amount
from (select client,amount,sum(amount) over (order by ranknumber) acc from A
where acc>(select sum(amount)/2 from sales)
order by amount desc
SQL 很难处理恰好要过线的那条记录,只能变相实现,用了两层三个子查询,过程步骤不清晰,不易调试。
而 SPL 代码则有清晰明了的的过程步骤。
A |
B |
|
1 |
=sales.sort(amount:-1) |
/ 销售额逆序排序 |
2 |
=A1.cumulate(amount) |
/ 计算累计序列 |
3 |
=A2.m(-1)/2 |
/ 最后的累计即总额 |
4 |
=A2.pselect(~>=A3) |
/ 超过一半的位置 |
5 |
=A1(to(A4)) |
/ 按位置取值 |
SPL 支持的数据源也很多,现代应用早就不只是关系数据库这一种数据源了,但却只有关系数据库能提供复杂的存储过程机制。

在 SPL 的支持下,可以让各种数据源都拥有存储过程的能力。
复杂的存储过程中常常会写出中间表以进行后续的计算,SPL 提供了高效的二进制格式文件格式,可以把中间数据落地到文件以便进一步做更细致的处理。而原生的 Java 以及 Python 都没这个便利,通常要使用文本文件或数据库来作为中间存储方案,性能很低且占用更多资源。
最后,esProc SPL 在这里 https://github.com/SPLWare/esProc。


英文版
文章接近末尾处,SPL 代码格 A2 里的 cumulate 函数,这个函数没有吧?是不是 cum?
A.cumulate 是计算序列成员累积的函数,很久之前这个函数废弃掉了,有些例子没有做修改。
为了一致性我刚把 A.cumulate 和 A.proportion 函数恢复了,A.proportion 是计算序列成员占比的。
大佬,这个 cumulate 实现的结果跟 A.(cum(~)) 和 A.iterate@a(~~+~) 一样吧?cumulate 有什么优势吗?
结果一样,就是写起来方便些,因为不太常用占了函数名就取消了
谢谢!代码格中都错位引用了,还请改一下。英文文档里也是一模一样的。😄
已改🙏