


关于 xlsimport@c 使用游标读取 excel 文件的问题
大佬们,我在使用 xlsimport@c 以游标方式读取 excel 文件时碰到一些现象,不知道是我使用方法欠妥,还是说有其它什么问题,恳请大佬得闲时给予帮助。
正常的 excel 表格是四方的,或者说矩阵式的,所见即所得。但实务中总有一些意想不到的操作,导致 excel 单元格看上去是空的,而实际上是有使用痕迹的。比如说,单元格不输入任何东西,设置居中对齐或者左右对齐,这在 excel 里就视同使用了,再比如行距变宽,也是使用了,这种是肉眼观察不到单元格里有东西的。还有一种是能看得到使用痕迹的,比如设置单元格的边框和底色。
由此,引申出游标读取的问题,我在使用中发现,用游标读取 excel 文件时,游标是根据 excel 的 usedrange 来取数的,当然这只是猜测。我还是用举例来说明这个问题(以下结果在集算器 IDE 和 EXCEL 插件里得到的结果是一样的)比如,在主目录下有一个 testcursor.xlsx 文件,看上去中规中矩的 4×3 表格,实际上在 D3 单元格设置了居中格式,如下所示:
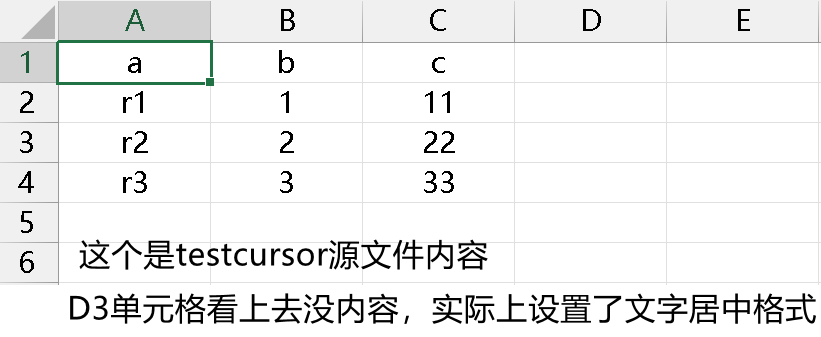
读取方式 1:字段名参数不写,从第一行开始读,所见即所得,跟源表一样,结果如下:
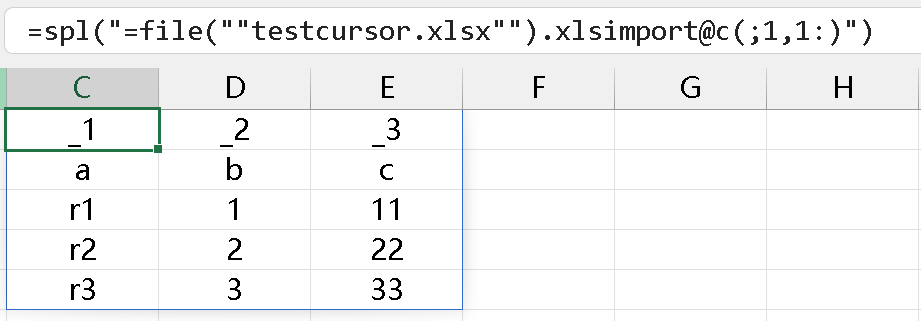
读取方式 2:字段名参数不写,从第三行开始读,因为 D3 设置了格式,结果得到 4 列,如下所示:

读取方式 3:显式指定所有字段名,从第一行开始读,结果在 D3 设置了格式处被截断,如下:
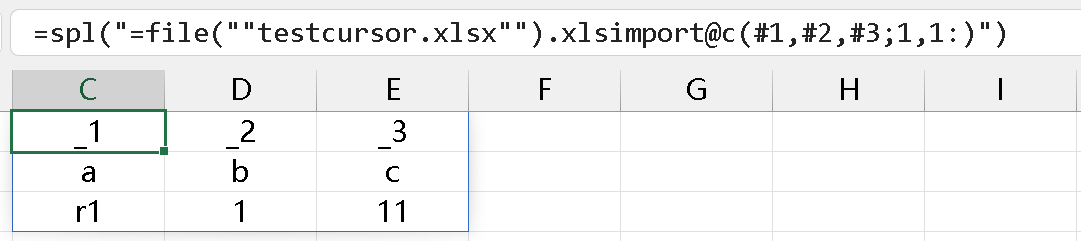
读取方式 4:如果指定 4 列 (因为 D3 有使用痕迹),从第一行开始读,结果为空,猜测是因为列数不符,第一行才 3 列:

此时,如果指定 4 列,从第三行开始读,结果跟上述第 2 种读取方式的一样,得到 4 列:

以上情况大概的意思是,在游标从上往下读取的过程中,在显式指定读取字段时,如果检测到之前的列数比当前的列数要小时,就会给截断。在字段名缺省时,会以表格中第一行的列数为基准读取。
还有一个情况是,源表格中的末尾如果有空行,且这个空行的行距或者格式有重新设置过,就会被游标视为数据读取出来。
目前碰到的就是这些,先不管文件格式是否中规中矩,游标使用方法是否合法,在缺省字段名和显式指定字段名时,得到的结果是不是应该是一样的?
以上游标处理 excel 的问题,恳请大佬们得闲时帮忙看看,谢谢!


感谢反馈!
读取方式 2,现在的规则是列数以标题行为准,有空白格也占一列。不管是否 @c 都是一样的处理规则,txt 的导入 file().import() 也是类似的规则。
读取方式 3,是程序有 bug,正确的结果应该是导入所有行的 1-3 列。
读取方式 4,从第 1 行开始读应该报错 #4 字段不存在(之前没报错)。从第 3 行开始读的结果是正常的,参考方式 2。
关于读取方式 3 和 4 的修改已经提交了。可以从论坛下载贴更新最新的 esproc-bin.jar。
如果源表末尾有编辑格式的空白格。
使用非游标式时,可以用 @b 选项进行过滤,自动去掉空白行。
使用游标式 @c 时,可以通过 SPL 的脚本再进行筛选。
谢谢大佬,大佬辛苦🙏
我就指望游标来给 xlsx 格式提速😄
xlsopen+xlscell 太慢了,500 个 xlsx 处理起来很费劲。
有些东西我也不希望去掉,获取后再去筛选想要的,这样妥一些。
游标中断的问题解决了就好。
我先试着,发现问题时或者有疑惑时再请大佬帮忙。感谢🙏
excel 游标式和内存式的读写速度确实差别很大。
筛选空记录可以用 cs.select(~.array().count()>0),或者有不能为空的字段可以用 cs.select(fieldname!=null)
感谢大佬指点解惑,我有不懂的再向大佬请教🙏
SPL…Yaoyao ahead!!!