


EXCEL 如何自动提取符合条件的行
用 Excel 数据处理时,有一项很重要的需求,就是筛选并提取符合自己要求的数据。当然我们可以利用 Excel 的筛选功能,将满足条件的数据筛选后复制出来。但是 Excel 筛选功能筛选出来只是一个静态的值,当筛选条件或者源数据有新增或修改时,我们就要不断重复筛选复制的操作。尤其是当源数据发生变化时,不能自动更新就容易出现引用错误数据的问题。解决这个问题,excel 也还有 VLOOKUP 可以用,但是 VLOOLUP 写起来又太复杂,公式的可读性也很差,提取多列时还要重复写多遍历公式,多行提取就干脆没办法了。
这里给大家介绍一款相当好用的 Excel 插件 SPL,它能够处理各种复杂 Excel 操作。用它来筛选和提取数据,操作简单,提取出来的数据可以自动更新,并且公式写法符合自然逻辑,一气呵成。用 SPL 来辅助 Excel 计算,工作效率秒翻倍。
例如,有几种产品的日销售数据如下:
我们就以此数据为基础,来实现几种不同的方式的数据筛选,并复制提取出来
例 1:简单条件数据筛选后提取
在上述数据中,找出日销售额大于 9 万的数据
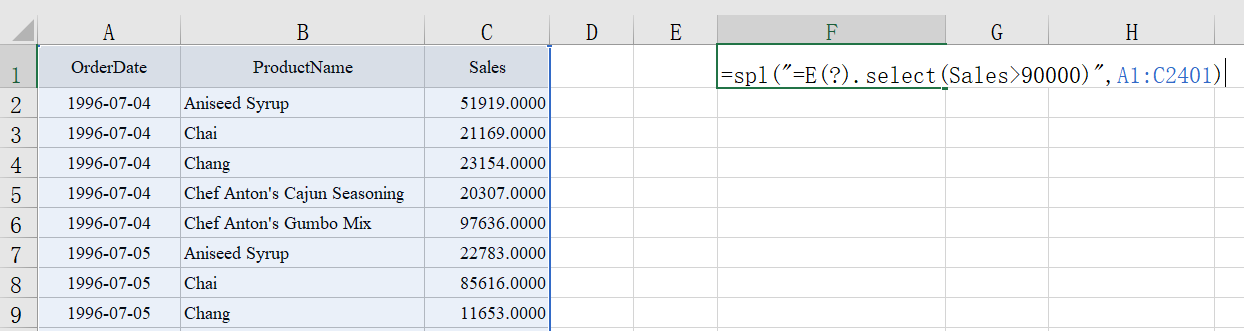
操作方法很简单,在 excel 空白单元格 F1 里输入代码:
=spl("=E(?).select(Sales>90000)",A1:C2401)
如图
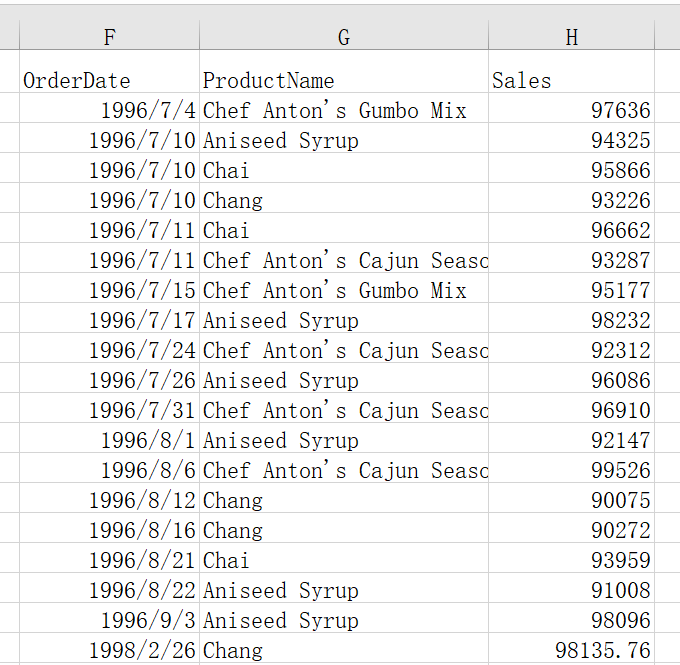
然后按 ctrl-Enter 键,返回查找结果
解释下代码:
spl() 表示调用 spl 插件函数
?表示函数的参数,如本代码中参数值为 A1:C2401
E()表示需要操作的表格,select() 是选择符合条件的数据
因此这句代码就表示,在表格 A1:C2401 中筛选出销售额 Sales 大于 90000 的数据。
当源数据发生修改时,直接 ctrl-Enter 执行一下单元格 F1 的代码,就可自动更新,无需重新操作。
比如源数据里的第 1 条数据 Sales 值为 51919,它是一个小于 90000 的数据,因此筛选结果没有,我们把它改为 90001,然后再 ctrl-Enter 执行一下,下图中可以看到该数据就出现在了筛选结果中。
数据修改前:
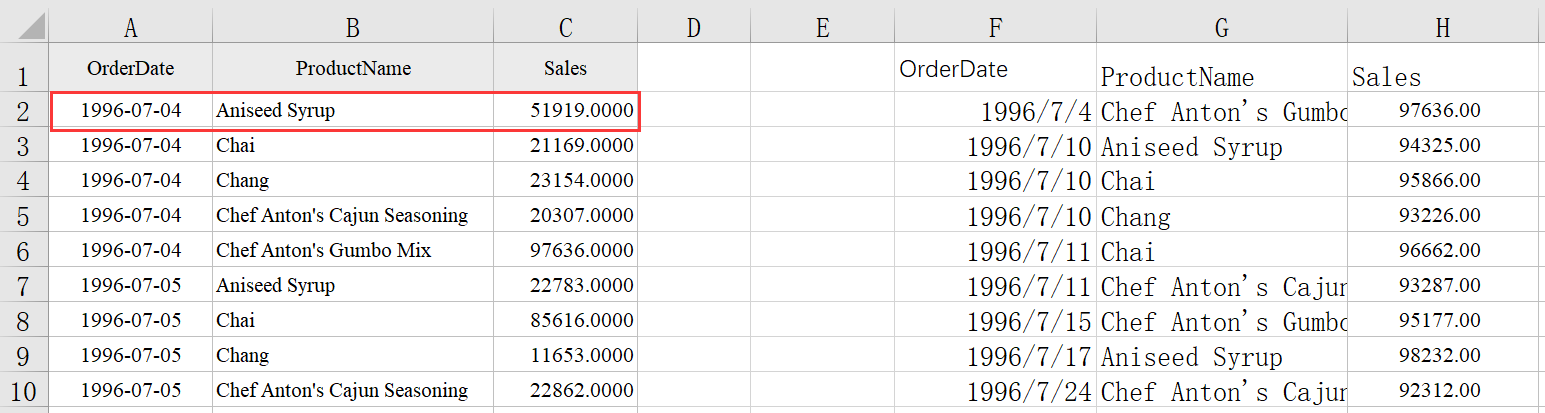
数据修改后:
例 2:复杂条件数据筛选后提取
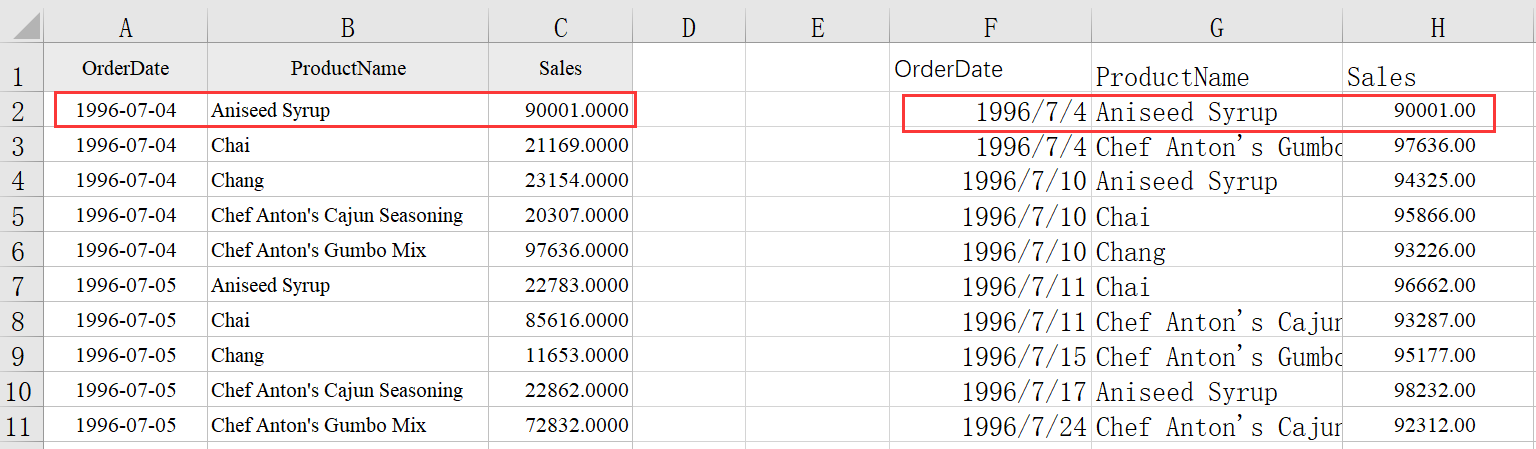
找出产品名为“Chang”,并且日销售额大于 9 万的数据
只需要在 select() 函数里添加条件即可:
=spl("=E(?).select(ProductName==""Chang""&& Sales>90000)",A1:C2401)
返回结果:
如果遇到下次提取数据的条件发生调整变化,直接在 select() 里修改条件即可,也无需重复操作
例 3:用分类汇总值筛选后提取
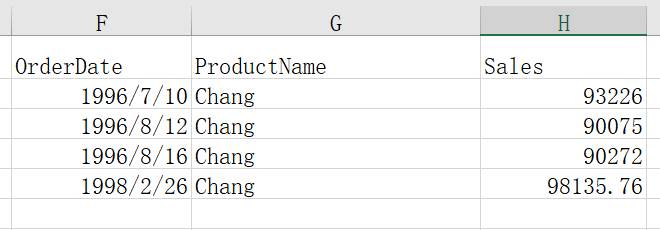
找出当日销售总额超过 30 万的日销售数据,并提取
与例 1,例 2 不同的是日销售总额原始数据里没有,需要先计算出来再筛选
日销售总额为各种产品当日销售额相加的和,可以按照日期分组,相同日期分为一组,然后组内求和,根据求和值筛选。
=spl("=E(?1).group(OrderDate).select(~.sum(Sales)>300000).conj()",A1:C2401)
返回结果:
group() 为分组函数,表示按照日期分组。然后计算每组的日销售总额并选出大于 300000 的组。
例 4:查找最大值后提取
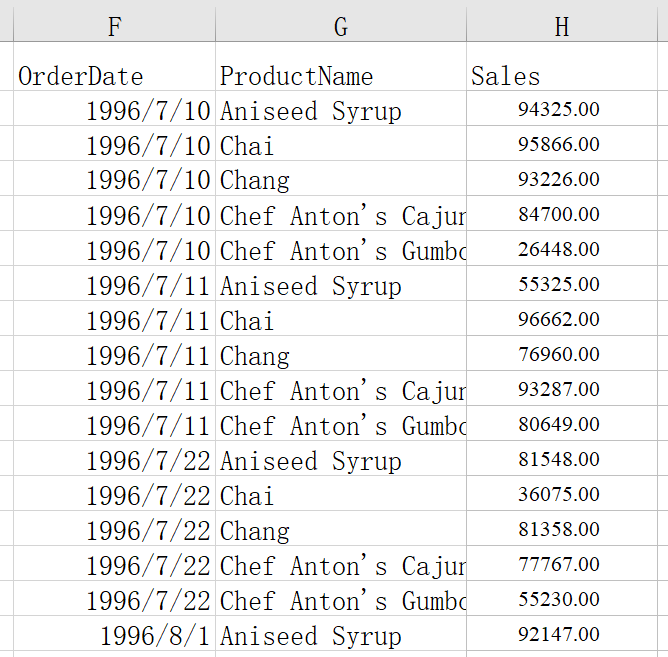
查找日销售额最大的数据
=spl("=E(?).maxp@a(Sales)", A1:C2401)
返回:

maxp@a() 表示返回所有最大值
例 5:查找排名前 N 的数据后提取
查找日销售额排名前 5 的日期
=spl("=E(?).sort(Sales:-1).to(5)", A1:C2401)
返回结果:
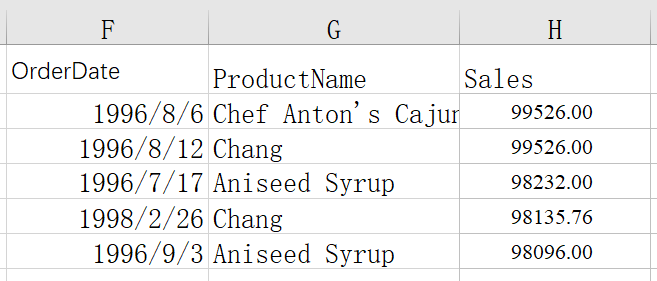
sort()是排序函数,-1 表示按降序排列,to(5) 表示取前 5 条数据
使用 spl 插件筛选和提取数据简单方便,而且效率高,并且还有配套丰富的 Excel 操作案例可以参考:esProc 桌面版与 Excel 处理,帮你轻松搞定职场中的各种 Excel 难题。
SPL 下载地址:» esProc Desktop Download
插件安装方法:SPL XLL 安装与配置


演示数据:ProductDailySaleszip
最后一个例子的写法跟 =E(?).top(-5;Sales) 相同。
如果要按中式排名 (有并列的排名不跳过,比如 1123345) 取出前五名的记录,要怎么写才会高效?
=E(?).group(Sales).top(-5; Sales).conj()
谢谢大佬!
这个写法也可以,我模拟了两百万条数据的 btx 文件,表 =2e6.new(uuid():name,rand(2e6):amt) 测试总结了一下,不知道对不对:
1、如果要聚合的数据重复度很高,比如本例中的数据扩大 1 万倍,Sales 的值有很多重复的,那 group().top() 效率很高。
如果数据重复度很低,或者几乎没有重复值出现,那 group 方法效率不怎么理想,不知道这个结论是否有点武断?
2、我的写法是先算出排名和位置,> 位置 = 表.ranks@zi(amt).pselect@a(’~<=50000), 然后再用位置去深化出记录,表 (位置)。这样子写在数据重复度不高时效率要高于 group。但在数据重复度很高时,效率明显不如 group。不知道 pselect 对这种不等于的查找有没有提速的方法?
英文版