


难倒所有 BI 的“女经理的男员工”问题
关联查询一直是 BI 的老大难,为了解决关联问题,采用宽表(CUBE)是一种常见的手段,即通过事先构建宽表消除多表关联来绕过关联查询的难题。
但这样做会导致 BI 的灵活性变差。
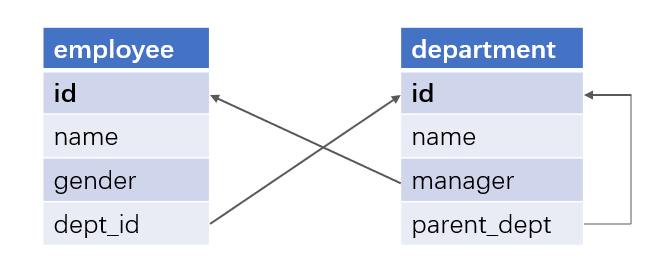
我们来考察 女经理的男员工 问题:根据员工表(employee)和部门表(department),我们想查出所在部门的经理是女性但本人是男性的员工。
两个表的关系如下(员工表和部门表相互关联,部门表自关联):
如果我们手写 SQL 是这样的:
SELECT A.*
FROM employee A
JOIN department B ON A.dept_id=B.id
JOIN employee C ON B.manager=C.id
WHERE A.gender='male' AND C. gender =' female'
用于存储员工和经理(也是员工)的员工表要关联两次才能完成查询目标。
为了避免上面的关联,我们基于这个查询需求构建的宽表(emp_width)是这样的:

经理作为“特殊”的员工,其信息要从员工表中冗余一份才能获得。我们基于这个宽表再查询就没有关联了:
SELECT A.*
FROM emp_width A
WHERE A.GENDER=’’ AND A.mgr_gender=’female’
基于这样的宽表很容易完成 女经理的男员工 的查询,这看起来没有任何问题。不过,如果我们还要查询 本级和上级经理都是女性的男员工 该怎么办呢?这个宽表无法完成这个查询,还要再扩充字段:

把上级经理(也是员工)的信息再冗余一次,得到了更宽的表。基于这个单表就可以完成上面“本级和上级经理都是女性的男员工”的查询:
SELECT A.*
FROM emp_width A
WHERE A.GENDER=’’ AND A.mgr_gender=’female’ AND A.mgr_gender2=’female’
到这里相信大家已经看出问题了:随着查询需求的变化,宽表也要不断调整。这显然与我们建设 BI 的初衷(满足灵活查询需求)出现很大背离。
当然,现代 BI 产品大多还支持用户在界面端自行建立关联,这也是解决关联查询的另一种常用手段。但这要求业务用户(BI 的使用者)对表结构以及表间关系很熟悉,并具备一定的技术能力。
还是这个例子,查询 女经理的男员工 可以这样构建关联:

员工表要选出两次,要起不同的别名以区分,还要理清表间的关联字段,所以对于业务人员来说是有困难的,通常需要技术人员来构建以后供业务人员使用,本质上与创建物理宽表是类似的。
想要查询 本级和上级经理都是女性的男员工 会更复杂一些:

员工表要反复选出三次,部门表要用两次,要构建出关联已经有些复杂了。不仅如此,有些 BI 产品并不支持一个表反复选择使用,也就无法构建这种关联来完成查询了。
貌似简单的 女经理的男员工 问题,就能难倒几乎所有 BI 产品。
显然,这个例子是刻意编造的,现实中看起来不会有人真对这个查询感兴趣,那么上面的讨论是不是没有意义?
当然不是,这个例子本身确实没有太多的业务意义,但实际业务中,类似的关联查询需求比比皆是,随手就可以举出:
-
电信业务中,根据通话记录和电话账户查询:北京号码打给上海号码的通话记录
-
零售业务中,根据销售记录和地区信息查询:不同地区下各个城市的销售情况
-
物流业务中,根据订单信息(收货城市和发货城市)统计:同城的订单情况
-
金融业务中,根据交易信息、客户信表、地区信息查询:在指定时间段内不同地区不同客户类型的交易金额和次数
-
石油业务中,根据油井信息、产量信息以及传感器数据查询:某个油井在指定时间段内每分钟的平均石油和天然气产量,以及平均温度
-
……
这些灵活的关联查询五花八门,不胜枚举。
目前这个例子的数据结构很简单,关联关系也很少,但我们已经能轻松设计出让许多知名 BI 都“现出原形“的难题,实际业务中的数据结构和关联关系远比这个例子复杂几十上百倍。如果没有事先建好宽表,描述这些关联将远远超过业务人员的能力。这个简单例子也表明,根本不可能构建把所有情况都包含进来的宽表,需求稍有变化都要重新调整宽表。面对复杂的现实业务,BI 的灵活性根本无从谈起。
看来,宽表并不能很好满足查询需求。所以想要达到 BI 期待的灵活就不能基于宽表,要正视关联的难题,从根本上解决问题。
那为什么一直都解决不好呢?
原因主要在 SQL 上。SQL 对 JOIN 的定义过于简单,导致数据集之间的关联关系看起来过于繁琐,超出许多业务人员的理解能力。想要从根本上解决问题,就要改变数据库层的数据组织模型。而几乎所有的 BI 产品都不会重新定义数据库的数据模型,其关联查询能力(灵活性)就会受限。
关于 JOIN 的详细分析可以参考: 连接运算
要解决这个问题,我们需要发明适合关联的查询语法。
DQL(Dimensional Query Language)就是基于上述原因发明的专门用于 BI 分析的类 SQL 查询语法。DQL 对 JOIN 进行了区分,通过外键属性化和同维表等同化等手段来消除关联,从而将多表关联查询转化成单表查询。
基于 DQL 语法去描述前面 女经理的男员工 的查询可以表达成这样:
SELECT *
FROM employee
WHERE gender='male' AND dept_id.manager. gender ='female'
DQL 把外键字段直接理解成它关联的维表记录,第二个句子中有部分表示当前员工的“所属部门的经理的性别”。把外键字段理解成维表的记录后,维表的字段被理解为外键的属性,dept_id.manager 即是”所属部门的经理“,而这个字段在 department 中仍然是个外键,那么它对应的维表记录字段可以继续理解为它的属性,也就会有 dept_id.manager.gender,即“所属部门的经理的性别”。
这种外键属性化的方式显然比笛卡尔积过滤的理解方式要自然直观得多,把多表关联运算看成是稍复杂些的单表运算以后,相当于把最常见的 JOIN 运算的关联消除了,甚至在语法中取消了 JOIN 关键字,书写和理解都要简单很多。基于这样的语法开发出来的前端页面用户也很容易理解,外键关系就可以通过“属性化”的方式来表达,有多少层都没关系。
所以,对于 本级和上级经理都是女性的男员工 的查询,用 DQL 表达:
SELECT *
FROM employee
WHERE gender='male' AND dept_id.manager. gender ='female' AND dept_id.manager.dept_id.manager.gender=’female’
仍然通过“外键属性化”方式将多表关联转化成多层级表达的单表查询。
有了这样的能力以后,基于 DQL 语法也能很好实现前端界面,通过树形结构逐层展开就可以查询任意层级的数据。比如前端界面可以做成这样:

员工、本级经理、上级经理的信息以树状结构分层级展示,可以无限展开,这样我们就可以查询任意级别的数据(经理 / 部门信息),理解和使用都很方便,业务人员使用没有任何难度,这样就很好地解决了一直困扰业界的实时关联问题。
关于 DQL 对 JOIN 的简化,在 《连接运算之 JOIN 的简化》 中还有更详细的说明,除了外键属性化,同维表等同化和子表集合化也有详细介绍,这里不再赘述。
有了 DQL 以后就可以直接解决多表实时关联的问题,不会再出现通过宽表绕过关联导致的灵活性差的问题了。
目前 DQL 可以基于 SPL 运行, DQL 作为语义层与应用前端直接交互,这样原来的多维分析应用仍可以继续使用,SPL 作为底层计算引擎提供性能保障。关于 SPL 的内容请参考: 宽表到底是快还是慢? (SPL 相对宽表在性能上更有优势)。
使用 DQL 和 SPL 的 BI 应用架构也会变成下面这样:
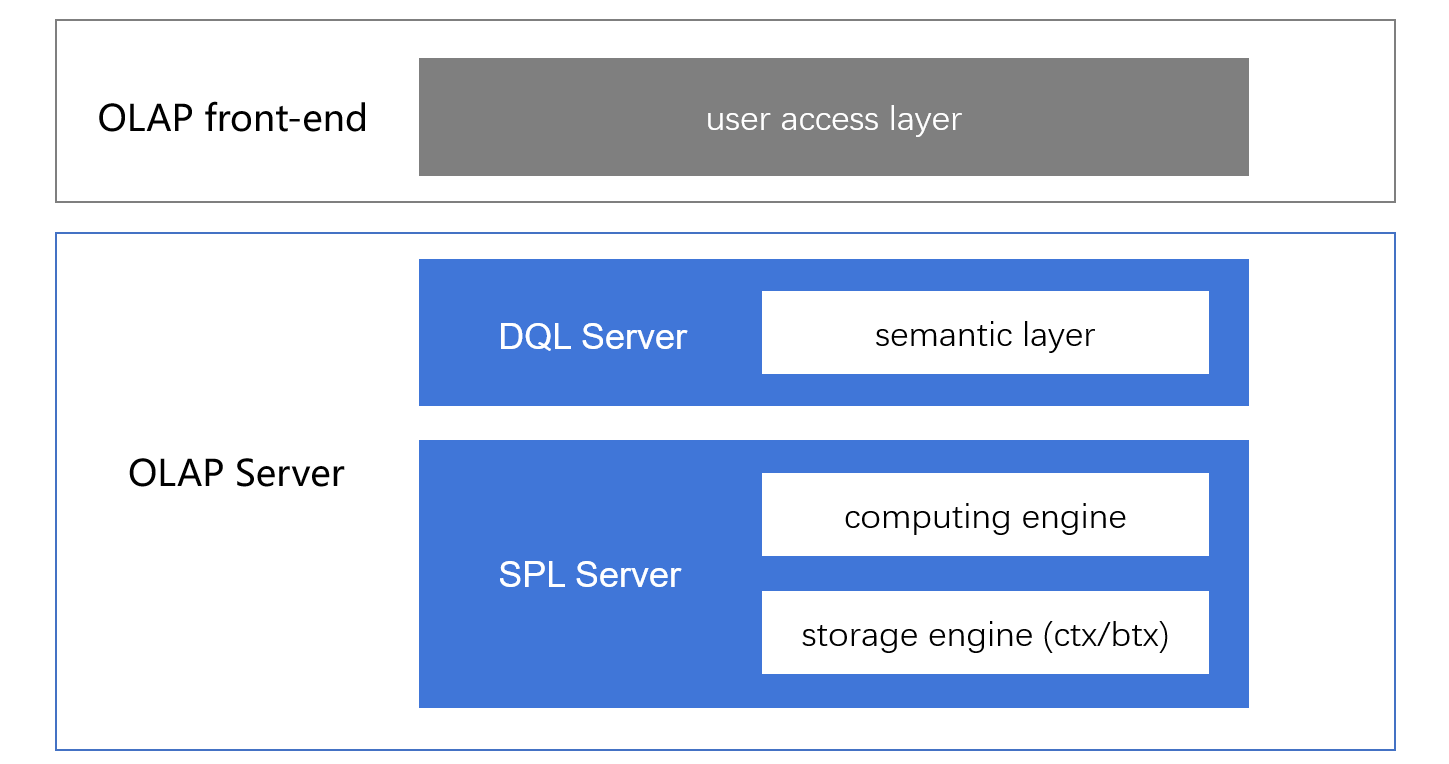
有了 SPL 和 DQL 以后,原来让人头疼的关联查询不仅可以很好满足,实时关联的性能相较于宽表还要更高(详见引文中的测试)。而宽表不仅灵活性差,还存在数据冗余、数据错误(违背范式的结果)等问题,通过实时关联满足了灵活性和性能要求后,还能完全避免宽表的其他问题,这才是 BI 该有的样子。


英文版