


数速 SPL 云 Scudata SPL Cloud
数据计算上云可以帮助企业降本增效,常见的方式是选用云数据仓库。当前几乎所有云数仓都是从传统数据仓库演变而来的,数据仓库诞生之初并没有上云的考虑,云数仓会面临存算分离、弹性扩展、Serverless 以及开放性等诸多方面的问题。虽然可以采用一些工程上的手段来变相实现一些功能,但仍然无法从根本解决问题。
数速 SPL 云(Scudata SPL Cloud,简称 SSC)提供了另外一种选择。SSC 是一款专门面向(半)结构化数据的云计算服务,具备高性能、低代码、全功能、开放性等特点,支持存算分离、弹性扩展、Serverless 等特性。
SSC 可以完全替代云数据仓库的功能,但本身并不是传统意义上的云数据仓库。SSC 的核心是计算,不提供数据管理以及描述数据的元数据内容,SSC 只是将计算云化后为用户提供便捷、灵活、高效的云计算服务。这样的设计可以带来很多好处:
本质上,SSC 的存储是构建在文件系统上的,SSC 只是设计了更高效的文件格式,文件是存放在网络系统还是云上对象存储中没有任何区别,有了这样的特性就可以天然支持存算分离,而不会像数据仓库原来绕过文件系统直接访问硬盘,要实现存算分离需要从底层重构(复杂度极高),十分困难。
没有了像数据仓库那样封闭的存储体系后,SSC 使用时就会更灵活开放,文件可以容纳任意结构的数据,同时 SSC 还可以访问各种云上数据源,数据不需要“入库”就能计算。不管存储(数据不私有),数据在哪都能算,这是 SSC 表现的开放性。
SSC 不管存储,也没有元数据,这样可以避免加载元数据带来的时间开销,计算节点随需要快速启动或关闭,更利于实施弹性计算。同时,没有元数据的束缚,SSC 天然支持多租户和 Serverless,不存在元数据导致的用户隔离和保持与用户有关的状态环境,整体上更加简洁高效。
关于 SSC 的特性和优点下面还会详细介绍。
SSC 中涉及多个部件和概念,这里先了解一下。
QDB:全称 QDBase,是 SSC 的核心,负责数据处理并提供服务。
QVM:全称 QDBase Virtual Machine ,是 SSC 的计算资源,与云虚拟机绑定,根据请求需要动态创建或销毁。每个 QVM 自带 QDB 服务程序用于处理计算任务。
QVA:全称 QDBase Virtual Allocator ,QVM 的分配系统,每个 QVA 管理一批虚拟机,响应任务请求后分配虚拟机并启动 QVM。
QVS:全称 QDBase Virtual Service,用户自行部署的服务程序,用于接受并处理计算请求。QVS 可以嵌入方式或服务器方式运行在用户自己的机器上(可以是云虚拟机),配置有用户云对象存储信息。
SPL:全称 Structured Process Language,是 QDB 的形式化语言,面向结构化和半结构化数据。
SSC 的应用形态有两种,可以直接使用公有云服务,也可以在公有云上进行私有化部署。
应用形态
公有云
SSC 目前支持 AWS、GCP 和 Azure 三种云。
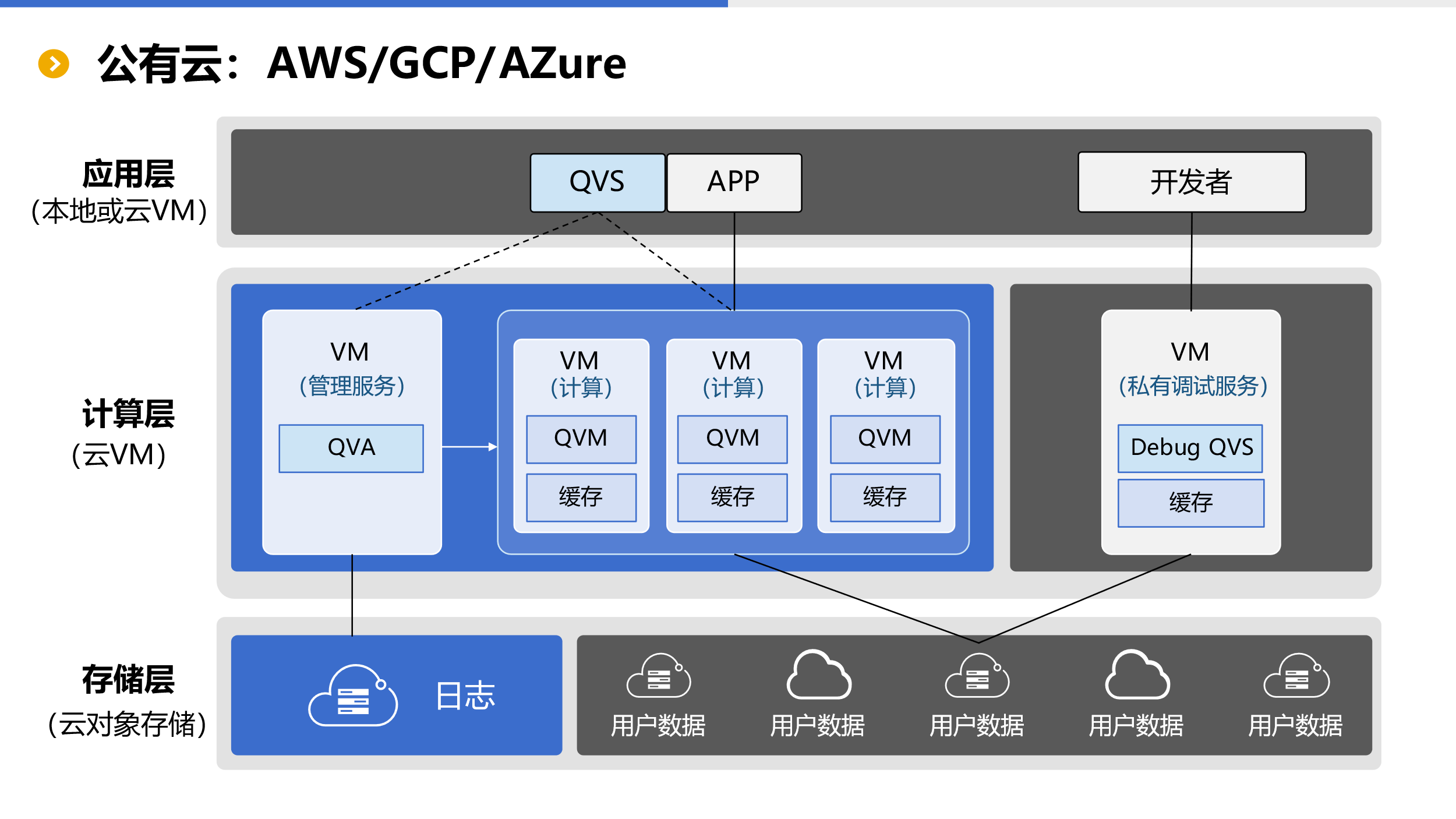
从架构图上可以看到 SSC 的应用结构为存储层、计算层和应用层。
存储层分为两部分,都采用云上对象存储。左边蓝色部分属于 SSC,是公有云的根存储,用于存储用户日志等系统信息,对用户透明,用户使用时不必关心。事实上,属于 SSC 的存储也仅此而已。
我们知道,云数据仓库的存储和计算是一体的,数据要先搬进来才能使用(计算)。但 SSC 不一样,SSC 不提供数据存储,用户数据原来在哪还在哪(原有云对象存储),只需将访问接口开放给 SSC 即可。数据不需要上传到 SSC 中,SSC 也不拥有用户数据,更不负责管理存储。这样做的好处是使用更加灵活、成本更低,天然支持多租户更加安全等。用户自管理数据是 SSC 非常重要的特性,这与云数据仓库的架构完全不同。
计算层整体运行在云上虚拟机上,主要运行 QVA 和 QVM 服务。计算层左边的 QVA 是整个 SSC 的管理服务,永久运行,主要用于系统的运维管理,用户管理和分配 / 回收 QVM 资源。
计算层中间部分是用于实际计算的虚拟机,QVA 根据用户请求动态创建 QVM(启动虚拟机)进行计算,完成后再回收计算资源(销毁虚拟机)。QVM 会将用户使用的热数据在虚拟机本地缓存以进行高性能计算。
计算层右边部分是用于开发调试的 QVS 服务。与用户数据存储在自己的云上类似,用于调试服务的 QVS 也部署在用户自己的虚拟机上,可以是云上,也可以在本地。调试过程不会消耗 SSC 资源(不产生费用),为用户私有,因此被称为私有调试。
应用层包括开发以及用户应用(APP)以及应用内置的 QVS。APP 如有计算需求需要通过其内置 QVS 向 QVA 申请 QVM,直连 QVM 完成计算任务,并不需要通过其他服务中转,QVM 读取存储层用户数据(或缓存)进行计算。内置 QVS 可以是独立服务器也可以与应用嵌入,APP 和其内置的 QVS 可安装在本地或用户自行购买的虚拟机上。
用户直接基于私有调试服务 QVS 进行脚本开发调试,并支持本地脚本上传和远程脚本下载。
从整个架构来看,SSC(蓝色部分)与其他产品最大不同的地方在于用户数据和调试均为用户私有,SSC 并不拥有用户数据,也不会因为调试增加用户成本。除此以外,SSC 更大的优势还在于开发效率和运算性能上,开发效率高可以有效降低开发成本,而高性能则会降低硬件成本。
公有云上的私有部署
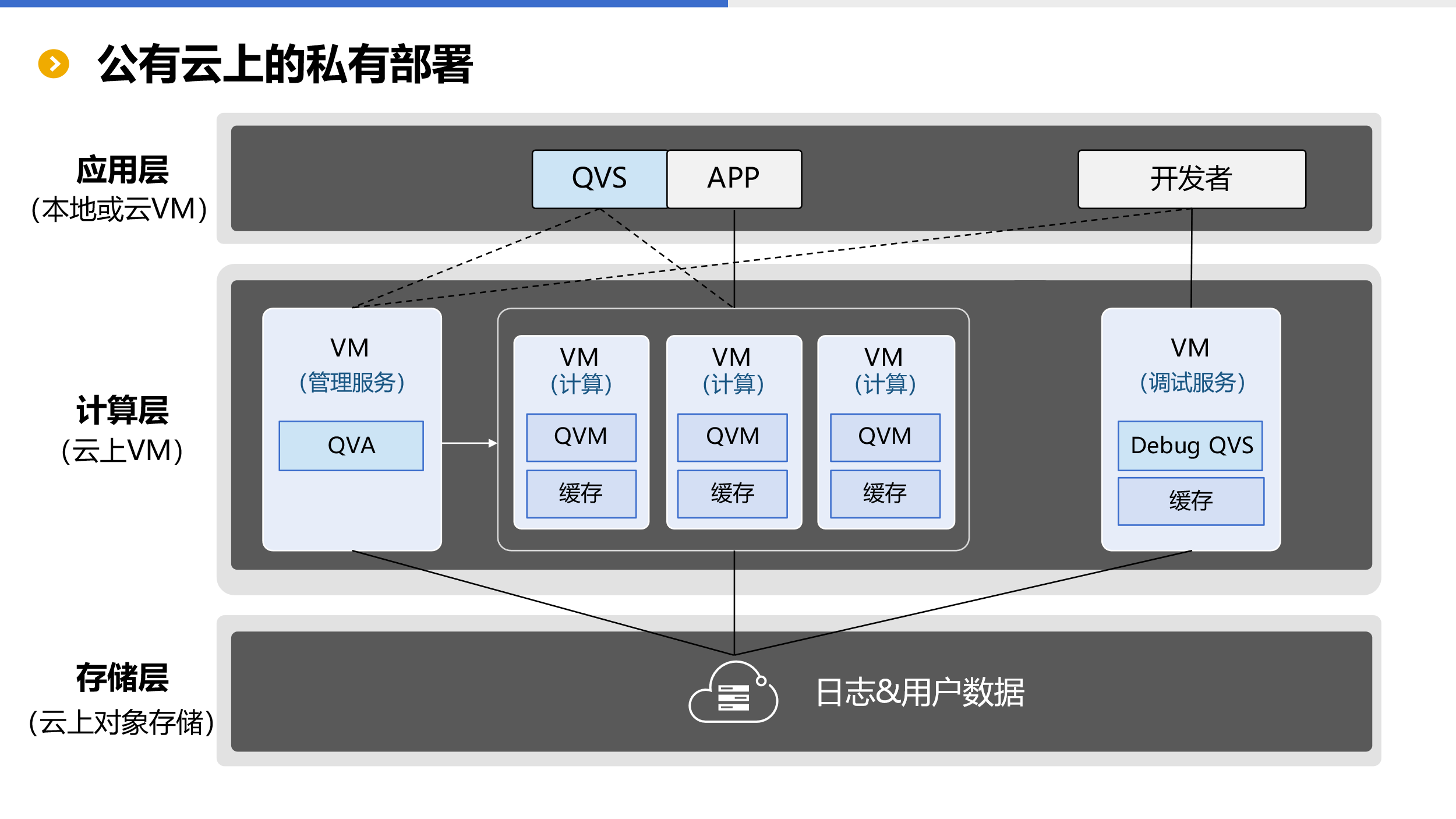
SSC 可以作为云软件由用户自己部署在公有云上。私有部署的结构与公有云类似,唯一不同在于整体全部为用户私有。系统日志与用户数据可以直接存放在公有云对象存储中。
两种使用方式可以根据实际需要进行选择,比较灵活。
SSC 特性
存算分离
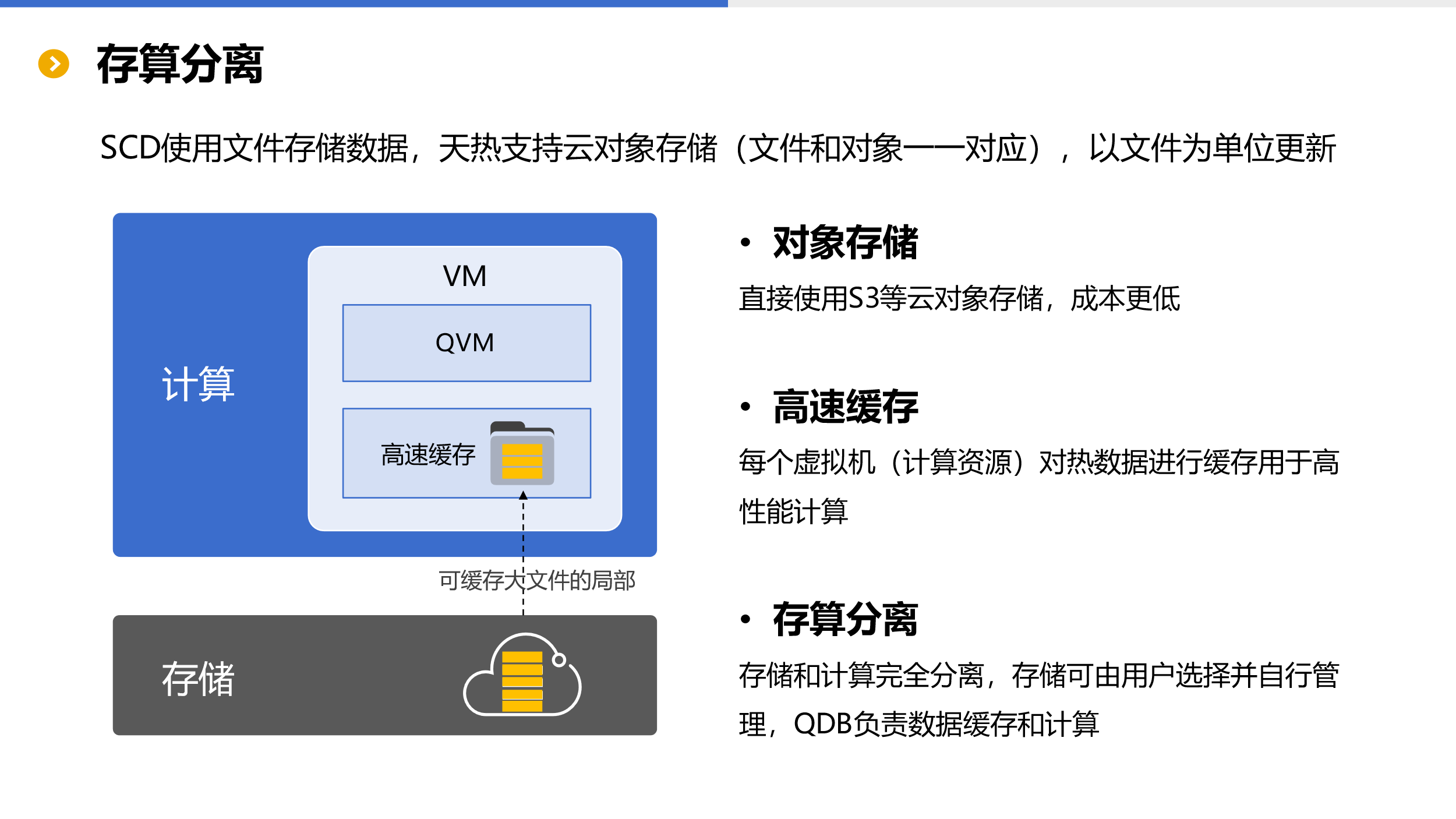
从架构可以明确看到 SSC 支持存储与计算分离。数据存储在云上对象存储中,由用户自行管理,而计算则由云上 SSC 的 QVM 完成。对象存储(如 S3)的成本很低,而 SSC 默认使用文件存储数据,文件与对象存储一一对应,可以完美实现相互转换。
SSC 在计算的 QVM 上还提供了高速缓存用于本地高性能计算。缓存由具体任务使用的数据实时决定,用到哪些缓存哪些(热数据)。数据一旦缓存会存在 QVM 所在虚拟机的硬盘上,直到硬盘写满才会失效(先进先出),这样有利于缓存复用。
弹性扩展
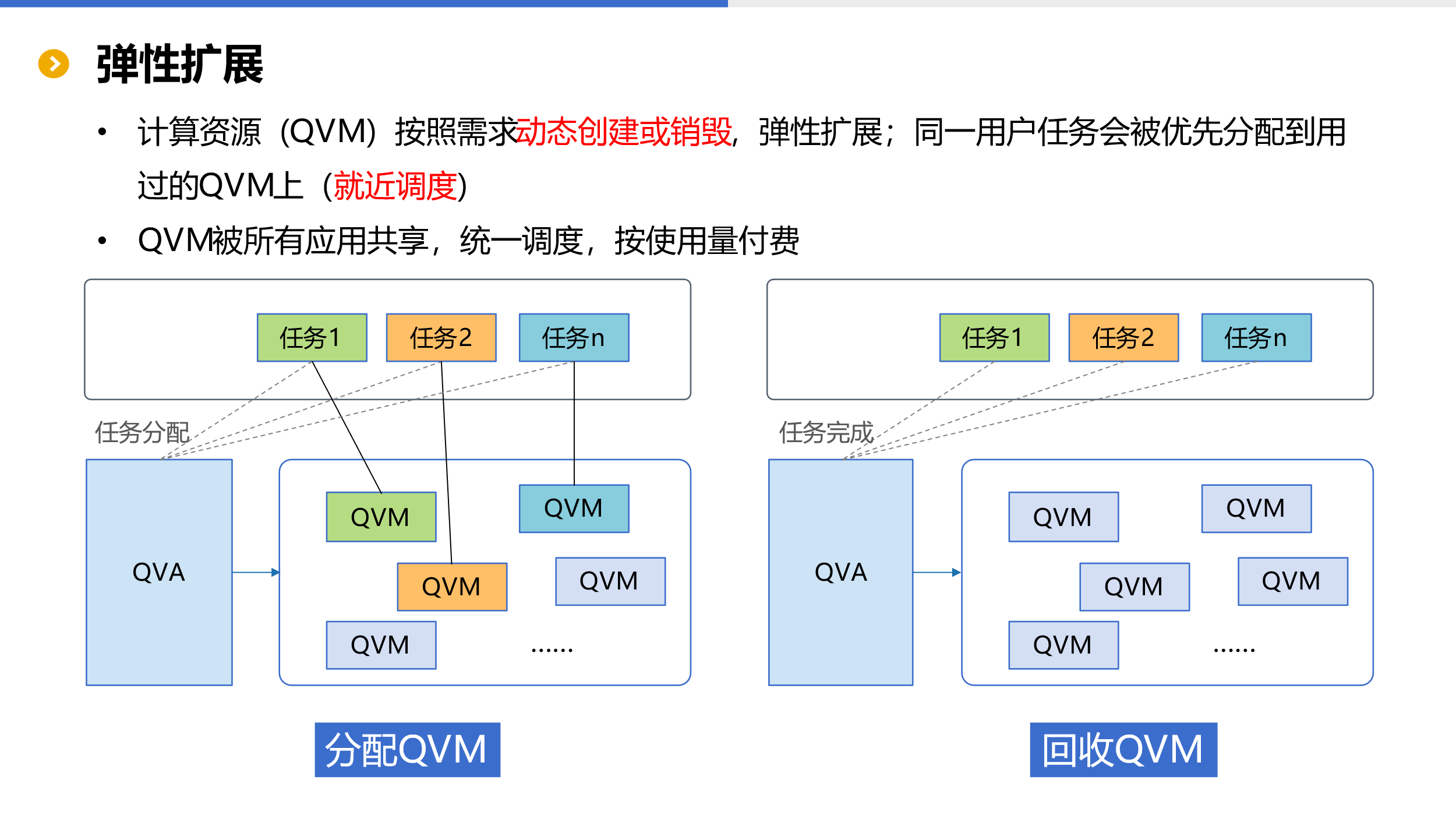
有了存算分离支持后,用户就可以根据需要单独对存储或计算资源进行扩展。云存储由用户自行管理不必多说。计算则由 QVA 根据需求动态创建或销毁计算资源(QVM),自动弹性扩展。
基于前述提到的缓存机制,QVA 在分配任务时会采用就近调度策略,将任务分配给历史用过且空闲的虚拟机上,复用缓存不仅计算效率高,不需要再缓存数据还会降低使用成本。
轻量级 Serverless
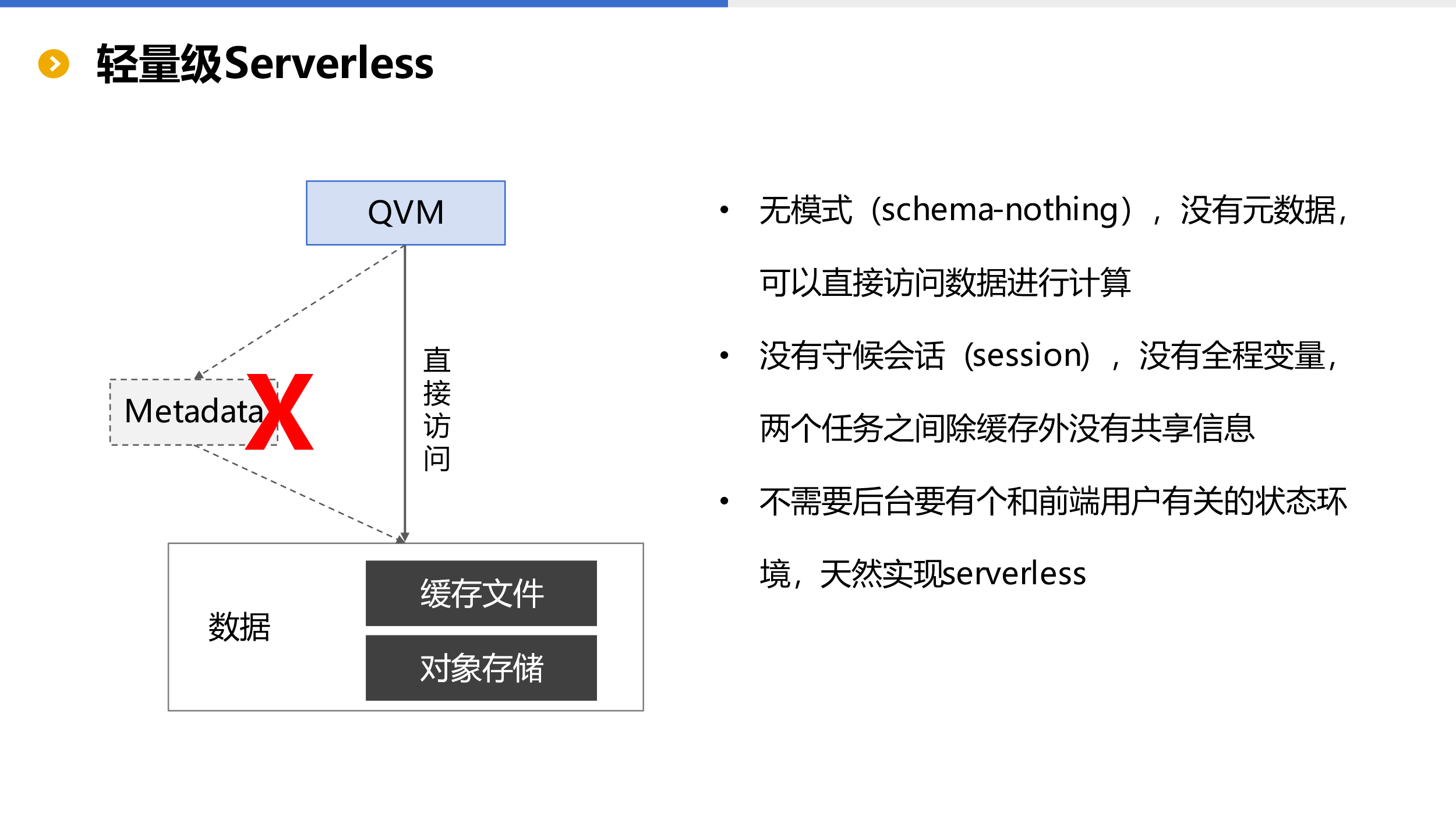
SSC 体系中没有元数据的概念(schema-nothing),不仅应用直接与 QVM 交互进行计算,QVM 读取数据时也无需加载元数据(根本就没有),因此会带来更加高效的计算效率,以及更加开放的计算能力。
我们知道 SQL 体系(云数据仓库)是需要元数据的,只有加载元数据才能进行计算。元数据如果存储在管理服务上(大部分情况是这样),那在多任务并发时管理服务就很容易成为瓶颈,这时又要考虑管理服务的扩展能力,整体架构不仅更加复杂运维成本高,计算效率也差。而元数据分布再计算服务上则又会由于个性化导致弹性扩展受限,而且加载元数据会导致计算虚拟机启动过慢,同样影响效率。
没有元数据的体系会更加轻量,后台也不需要保持与前端用户相关的状态环境,天然实现 serverless。
用户自管数据

SSC 体系中并不包含用户数据,存放用户数据的云存储由用户自行准备和管理,数据不需要上传到 SSC 中,SSC 并不拥有用户数据,只需要开放相应访问接口供 SSC 访问就可以了。
用户自行管理数据会带来如下好处:
数据仍然是用户的私有资产,自己有完全的管理和使用控制权,会更加安全;
数据私有还会带来天然的用户间数据隔离,从而天然实现多租户,因为多租户的实现难点主要在于数据隔离,数据私有天然解决了这个问题。
私有调试
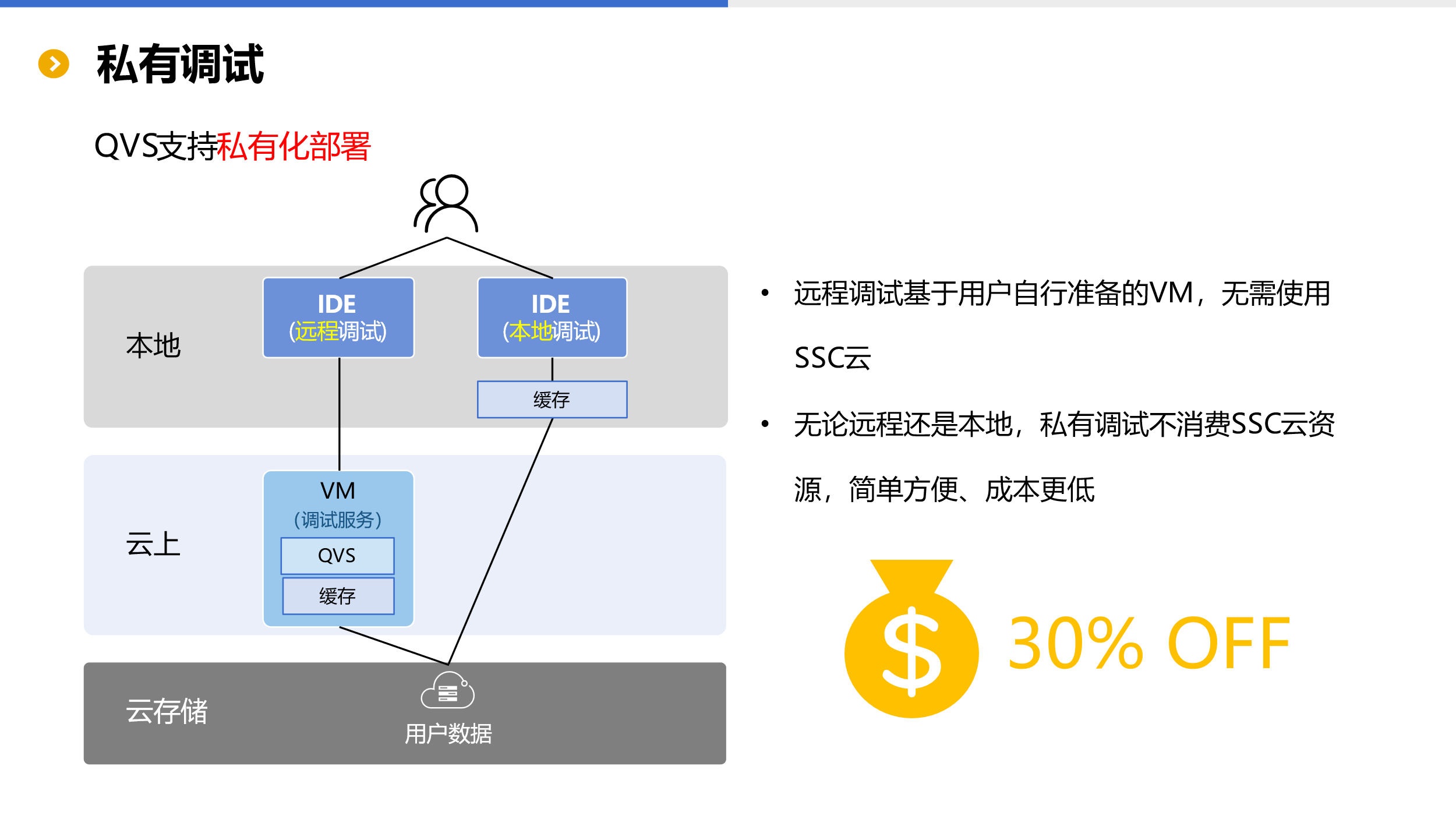
在云计算中,调试程序产生的成本往往会占到总成本的 1/3 以上。因为调试过程中会消耗计算资源并发生相应的数据传输,而像云数据仓库并不能区分这些计算资源的目的是调试还是生产,都会一视同仁地计费。对于复杂且数据量较大的计算,调试成本消耗很大,这种成本构成和之前未上云时的开发模式相差巨大。很显然,由于云数据仓库的封闭、统一管理中心、元数据等带来的沉重性,这个缺点无可避免。
SSC 为解决这个问题采用了私有调试的形式。用户调试时均不消耗 SSC 的存储和计算资源,完全使用用户自有的资源,因此会有效降低使用成本。
私有调试分两种方式。
一种通过本地 IDE 连接部署在云上的 QVS 服务进行远程调试。这样数据在云上流转不会额外产生流量费用,同时具备更好的安全性。
另一种如果考虑开发调试效率,同时一定程度允许数据缓存在本地(本地调试效率相对远程肯定更高),那么可以通过 IDE 直接基于云存储进行开发调试,但可能会有一定的流量费用(视云服务商的规则)。
无论采用何种方式,SSC 在调试方面的应用成本都会更低,仅仅从调试这一方面就可以节约 30% 左右的成本。
开放性

SSC 在应用时不仅可以读取事先准备的对象存储,还可以连接其他云上多样性数据源(如公有云上的 RDB、Kafka、MongoDB、Redis、Elasticsearch、RESTful 等)进行计算,特别地还可以进行多数据源之间的混合计算。
基于多种数据源进行实时计算可以充分利用实时数据,为应用提供实时数据服务。有了这个能力就可以很好支撑微服务实现。
高性能低代码

SSC 除了在架构上的优势外,最大的优点还在于 SPL 的低代码和高计算性能。SPL 采用了与 SQL 完全不同的离散数据集理论模型,改善了关系代数在集合运算中的诸多问题(如有序利用、离散性等),提供了过程计算支持,内置了更加丰富的结构化数据计算类型(序表)和运算(有序计算等),在实现复杂计算时更加简单。
不仅代码实现简单,SPL 的运算效率也更高。在大量实际案例中,SPL 的运算效率往往超过 SQL 数倍到数百倍。高性能意味着硬件成本会更低。
关于低代码和高性能可以参考另外专门介绍 SPL 的材料:
应用成本低出 N 倍的数据分析引擎 esProc SPL
全功能

除了低代码和高性能,SPL 还具备全功能的特点。现在几乎所有云数据仓库仍然是基于 SQL 体系的,而 SQL 在实现一些复杂计算时并不容易。比如计算用户流失率的电商漏斗分析用 SQL 几乎就写不出来,这时就需要编写 UDF 或借助 Java/Python 等其他技术实现。SQL+ 其他技术这样的应用方式在企业内部还行得通,但在云上就不可以了。云环境不会开放这些个性化的编程技术,大家只能硬着头皮使用 SQL。而 SQL 能力又有限,似乎就陷入了死循环。
SPL 的能力更加全面,可以看做是 SQL 与其他技术的结合体。SQL 能实现的自然不在话下,SQL 不容易做的也能实现。像漏斗分析用 SPL 不仅写得更短,代码也更通用,同时执行效率也更高。
功能全面会让技术栈更加简单,随之会带来更低的运维成本。
外部接口
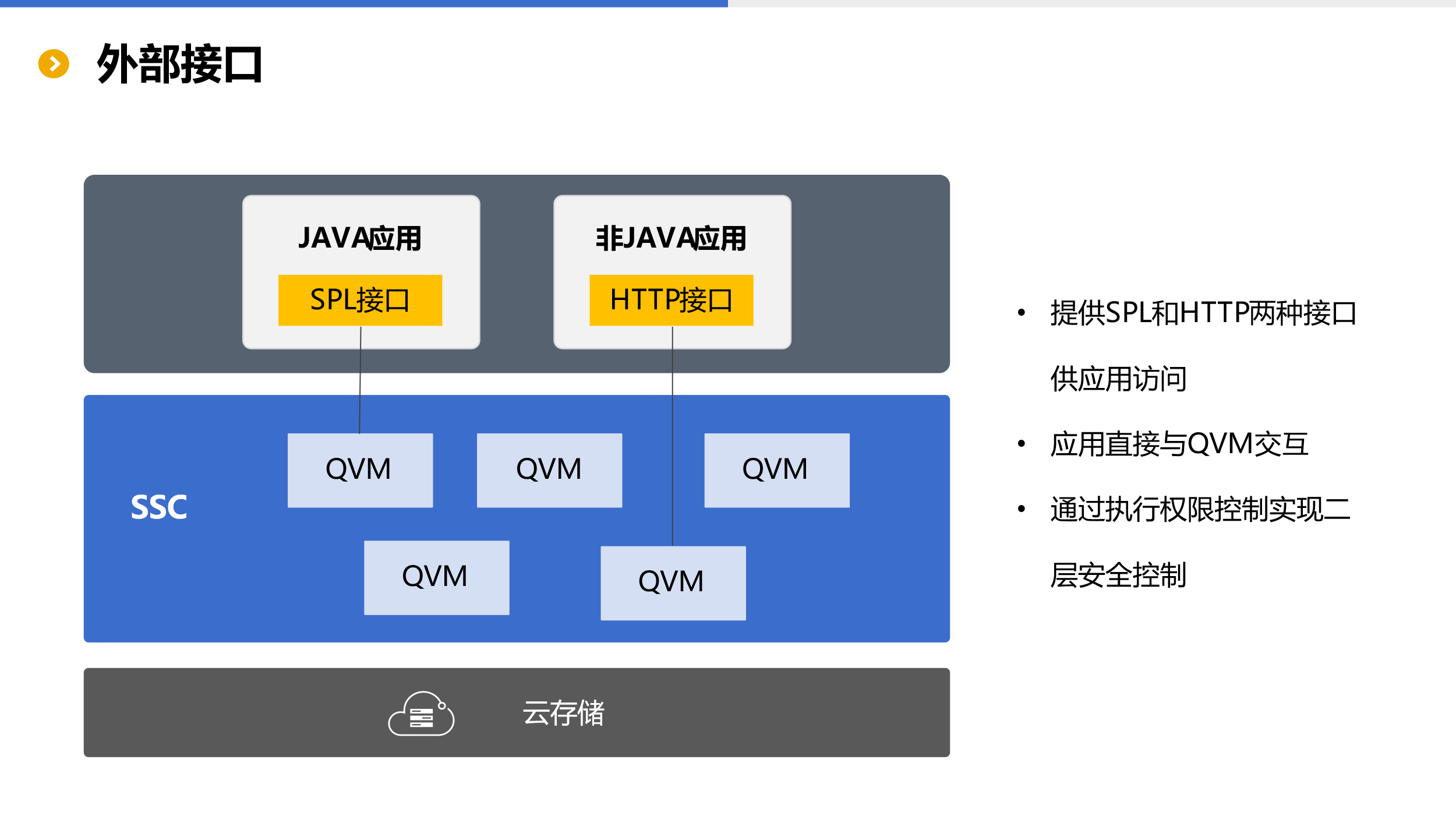
在与应用结合方面,SSC 提供了两种应用接口。对于 Java 应用,可以直接使用 SPL 接口将其集成在应用内与 SSC 交互。对于非 Java 应用,则可以采用 HTTP 接口与 SSC 相连。
无论采用何种接口,应用都与 QVM(计算服务)直接相连。
应用在与 SSC 交互时只会赋予执行权限,而无权修改删除计算脚本,实现二层安全控制。
综合来看,SSC 云计算的目标是给用户带来更多价值,低成本、高性能、开放灵活、功能全面等,这些目标在 SSC 的架构优势和引擎能力都能够很好实现。


英文版