"想利用并行方式添加游标,但是报错,请问是什么问题? [图片]"
想利用并行方式添加游标,但是报错,请问是什么问题?
组表目前还不支持并行写,不过这个错误信息是有点太不友好了,要改一下。
请问有什么其他方案,来提高组表的写的速度吗?
SPL 定位是数据分析(AP)业务,优化点主要是“算”,对数据就是”读“。在写方面优化比较少,单线程时通常还是会比数据库快,但组表经常要保持一定的次序,就不能采用多线程了。
这个要具体看任务目标,写出的目的是什么:1. 事前准备数据,通常对性能要求不会太高,慢点就慢点了。2. 中间落地数据,写成集文件通常会更快一些,组表要考虑的内容要多,数据转换过程复杂。3. 如果用组表,可以并行写成多个分表,后续再计算时使用复组表,但复组表有个别功能会缺失(大部分都有)。4. 或者数据就是某种方式拆分的,每个线程只处理一段数据。
目前我有个场景,需要实时写一个 ctx,后后续读做准备,希望性能快
建议把需求场景再描述详细一些,如果不方便公开,可以找技术支持人员沟通,一起出个方案。单这么一句话,不好给什么建议,只能是参考昨天说的那四条去套
场景就是我有个大的数据集 ctx 大概上亿条数据,业务上有个过滤器,在用户选择自己要过滤的条件后,需要实时生成一个新的 ctx 文件,这个就是过滤后的 ctx 大文件,也就是技术上要求生成一个新的 ctx 文件 append 过滤条件后的游标数据,实时的过程。
然后写出这个 ctx 又做什么?听起来结果应该挺大,应该要继续计算的。如果结果集很小,那可以并行生成到内存里再一把写出去。如果结果集很大,通常是要再计算的,也许有其它的再计算手段,不一定要落地这个东西,如果不再计算只是存着,那一般不会有高速的要求了。还是和技术支持人员仔细沟通一下更深一步的需求。为什么要做这个事,能不能避免掉?如果一定要生成一个较大的 ctx,那确实没办法跑得很快。
过滤器过滤完成后生成新的数据结果集 (ctx 文件),后续所有业务操作必须基于新的结果集来查询。这个就是必须先生成结果集,然后在这个结果集上做 olap 查询操作。
如果前一步过滤就很慢,那无论如何不可能快速生成 ctx(即使写出时间能变少),瓶颈会在过滤本身上,那看看这个过滤有什么可以优化的地方。如果前一步过滤很快(以致于能用“实时”这种词),那为什么一定要生成一个中间结果集?毕竟 OLAP 查询动作的结果集通常很小的,直接从源数据集计算有什么问题?
一定要生成中间结果文件,btx 会快一点,但后续查询慢一点。或者按前几天提过的并行生成复组表的分表,再次查询时建立复组表,大部分动作都能工作,有个别运算不支持复组表。但只要落地总归不会很快,OLAP 查询通常是小结果集,直接在准备好的源集上处理一般效果会好得多。




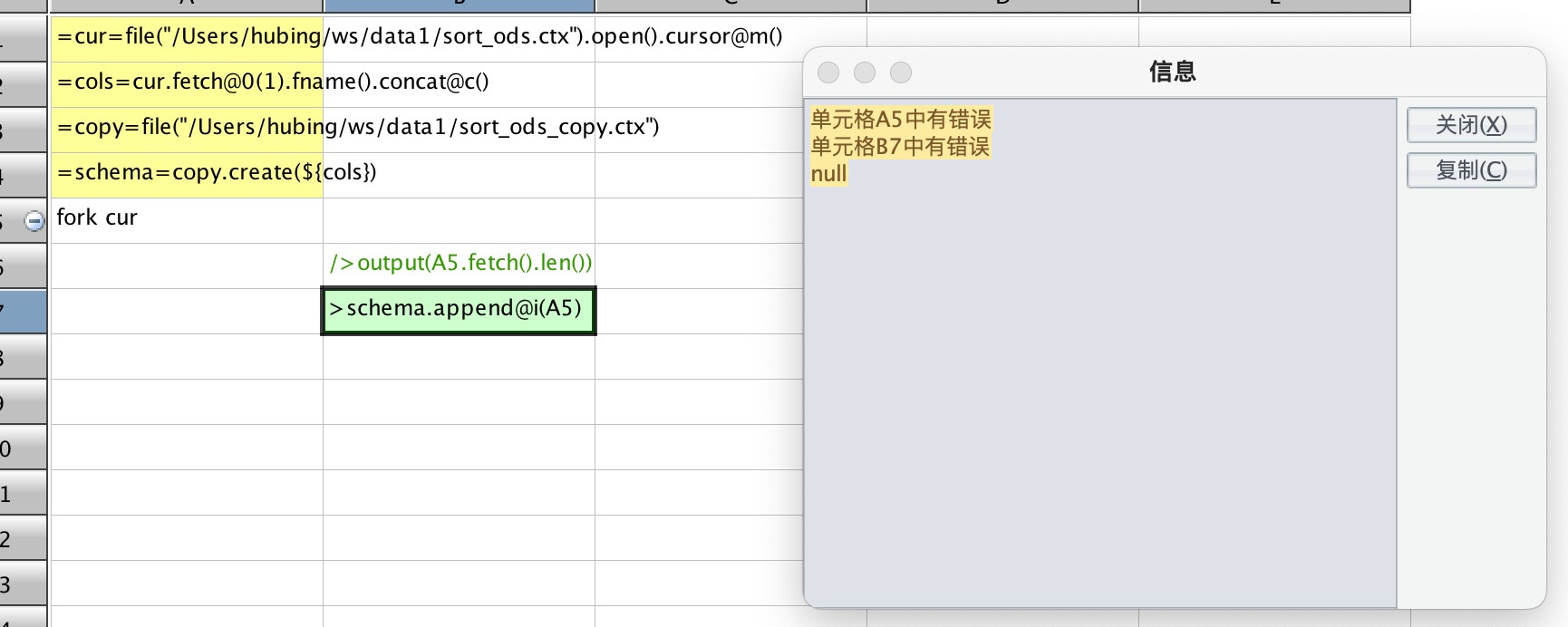

组表目前还不支持并行写,不过这个错误信息是有点太不友好了,要改一下。
请问有什么其他方案,来提高组表的写的速度吗?
SPL 定位是数据分析(AP)业务,优化点主要是“算”,对数据就是”读“。在写方面优化比较少,单线程时通常还是会比数据库快,但组表经常要保持一定的次序,就不能采用多线程了。
这个要具体看任务目标,写出的目的是什么:
1. 事前准备数据,通常对性能要求不会太高,慢点就慢点了。
2. 中间落地数据,写成集文件通常会更快一些,组表要考虑的内容要多,数据转换过程复杂。
3. 如果用组表,可以并行写成多个分表,后续再计算时使用复组表,但复组表有个别功能会缺失(大部分都有)。
4. 或者数据就是某种方式拆分的,每个线程只处理一段数据。
目前我有个场景,需要实时写一个 ctx,后后续读做准备,希望性能快
建议把需求场景再描述详细一些,如果不方便公开,可以找技术支持人员沟通,一起出个方案。单这么一句话,不好给什么建议,只能是参考昨天说的那四条去套
场景就是我有个大的数据集 ctx 大概上亿条数据,业务上有个过滤器,在用户选择自己要过滤的条件后,需要实时生成一个新的 ctx 文件,这个就是过滤后的 ctx 大文件,也就是技术上要求生成一个新的 ctx 文件 append 过滤条件后的游标数据,实时的过程。
然后写出这个 ctx 又做什么?听起来结果应该挺大,应该要继续计算的。
如果结果集很小,那可以并行生成到内存里再一把写出去。如果结果集很大,通常是要再计算的,也许有其它的再计算手段,不一定要落地这个东西,如果不再计算只是存着,那一般不会有高速的要求了。
还是和技术支持人员仔细沟通一下更深一步的需求。为什么要做这个事,能不能避免掉?
如果一定要生成一个较大的 ctx,那确实没办法跑得很快。
过滤器过滤完成后生成新的数据结果集 (ctx 文件),后续所有业务操作必须基于新的结果集来查询。这个就是必须先生成结果集,然后在这个结果集上做 olap 查询操作。
如果前一步过滤就很慢,那无论如何不可能快速生成 ctx(即使写出时间能变少),瓶颈会在过滤本身上,那看看这个过滤有什么可以优化的地方。
如果前一步过滤很快(以致于能用“实时”这种词),那为什么一定要生成一个中间结果集?毕竟 OLAP 查询动作的结果集通常很小的,直接从源数据集计算有什么问题?
一定要生成中间结果文件,btx 会快一点,但后续查询慢一点。
或者按前几天提过的并行生成复组表的分表,再次查询时建立复组表,大部分动作都能工作,有个别运算不支持复组表。
但只要落地总归不会很快,OLAP 查询通常是小结果集,直接在准备好的源集上处理一般效果会好得多。