


SPL 计算性能系列测试:漏斗分析
一、 测试任务
电商业务中漏斗分析是常见的统计需求。用户使用智能设备购物时,系统会建立连接形成会话 session。每个会话又包含很多个操作事件 event,比如:访问网站,浏览产品页,下单购买等等。每个用户的操作事件有一定的先后顺序,事件顺序越靠后,完成该事件的用户数量越少,就像是一个漏斗。漏斗转化分析先要统计各步骤操作事件的去重用户数量,在此基础上再做转化率等进一步的计算。
现将电商系统的数据结构简化如下:
sessions 表
列名 |
数据类型 |
说明 |
id |
long |
session 编号,主键 |
userid |
long |
用户号 |
devicetype |
int |
设备类型 |
events:
列名 |
数据类型 |
说明 |
id |
long |
event 编号,主键 |
sessionid |
long |
session 编号 |
userid |
long |
用户号 |
eventtime |
datetime |
发生时间(精确到毫秒) |
eventtype |
int |
事件类型 |
eventmessage |
string |
事件消息(200 字符) |
eventtype:
列名 |
数据类型 |
说明 |
id |
int |
序号,主键 |
name |
string |
名称 |
devicetype
列名 |
数据类型 |
说明 |
id |
int |
序号,主键 |
name |
string |
名称 |
表间关系说明:
sessions 表(简称 s)和 events 表(简称 e)是一对多关系,通过 s 的 userid、id 和 e 的 userid、sessionid 关联。
不同的 userid 对应 session 的 id 不会重复,不同的 session 对应 event 的 id 不会重复。
events 表和 eventtype 表(简称 et)是多对一关系,通过 e 的 eventtype 和 et 的 id 关联。
sessions 表和 devicetype 表(简称 dt)是多对一关系,通过 s 的 devicetype 和 dt 的 id 关联。
本测试任务的输入参数是指定日期,例如:2022-07-21。测试任务是对指定日期前 30 天内的 events 计算三步和七步漏斗转化率。
以三步漏斗为例,在 2022-06-21 零点到 2022-07-21 零点之间,分别计算出:
做过 visit 类型事件的去重用户数量,记为 step1_count;
在一天内依次做过 visit,view 类型事件的去重用户数量,记为 step2_count;
在一天内依次做过 visit,view,confirm 类型事件的去重用户数量,记为 step3_count。
在此基础上,按照这些事件对应 sessions 的设备类型 devicetype,对这些去重用户数量分组求总数。最后用 step3_count 除以 step1_count,求出三步漏斗的转化率。
三步漏斗计算结果大致是这样的:
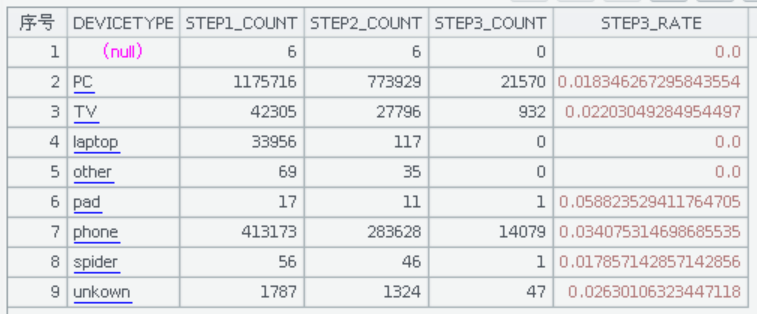
七步漏斗计算过程与三步漏斗大致相同,只是 events 类型有七个,依次是:visit、view、detail、login、cart、confirm、pay。七步漏斗计算结果大致是这样的:
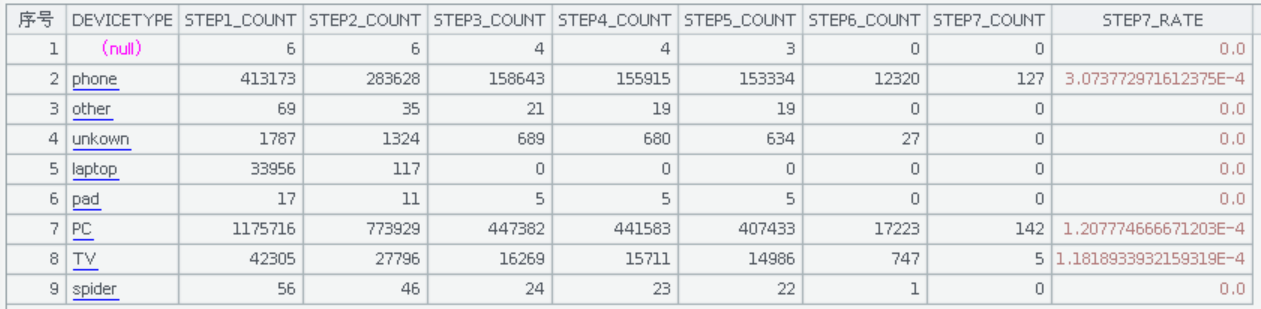
本次测试还按照是否包含字符串过滤条件分为 A 类和 B 类两类测试。B 类测试是在上述 A 类测试的基础上,每一步都加上包含子串的过滤条件。比如第一步漏斗,对 events 还要加上一个条件:eventmessage 包含字符子串“check_point”。每一步漏斗过滤条件中,eventmessage 字段的子串都是不同的。
二、 对标技术
本次测试采用了 SPL 企业版(2023 年 5 月版本),并在同样环境下采用 StarRocks、Oracle 进行漏斗转化率计算,对比计算性能。
1、StarRocks, 宣称最快的 SQL 型数据库,测试版本 3.0 和 2.5.3。
2、Oracle,使用很广泛,常常作为数据库性能测试的对比标杆,测试版本 19c。
Oracle 不是专业 OLAP 数据库,性能指标通常会较弱,仅供参考。
三、 测试环境
单台物理服务器,配置:
2 颗 Intel3014,主频 1.7G,共 12 核 CPU
64G 内存
SSD 固态硬盘
为了能测试出这些产品的外存计算能力以及对内存的敏感性,我们使用虚拟机来限制内存。设计了几套内存不同的测试环境,CPU 都是 8 核:
VM1:32G 内存;VM2:16G 内存;VM3:8G 内存;VM4:6G 内存;VM5:4G 内存
StarRocks 至少要安装两个节点 BE 和 FE,将承担计算任务的 BE 安装在虚拟机上,管理节点 FE 安装在物理机上,这样不会影响测试效果。
SPL 和 Oracle 都只要在虚拟机下安装就可以了。
SPL、StarRocks 在能跑出结果的虚拟机上都测试了,Oracle 因为仅作为参考,只在 VM1 测试了。
四、 测试数据
全部数据的日期范围是 2022-06-28 到 07-28
sessions:350 万行
events:2.8 亿行
eventtype:678 行
devicetype:8 行
点击这里下载测试数据。(如果点击后没有开始下载,请复制 http://d.raqsoft.com.cn:6888/funnel.zip 到浏览器地址栏下载。)
下载后,解压缩到一个目录中,在集算器中将这个目录配置成主目录,执行 dataInit.splx 生成文本文件。
用于测试的数据存放在 4 个 tab 分隔的文本文件(无字段名称):
sessions.txt:数据按照 userid、id 有序(升序,下同)。
events.txt:数据按照 userid、sessionid、eventtime、id 有序。events 表对于 B 类测试中的字符子串(比如“check_point”)的过滤条件,判断结果都是“真”。
eventtype.txt:数据按照 id 有序。
devicetype.txt:数据按照 id 有序。
字段先后顺序和上述表结构的字段顺序相同。
以 devicetype.txt 为例,文件内容是:
1 phone
2 other
3 unkown
4 laptop
5 pad
6 PC
7 TV
8 spider
五、 SQL 测试
Oracle 在 VM1 上测试了 A 类的三步和七步漏斗。
StarRocks 在所有能跑出结果的虚拟机上测试了三步和七步漏斗,包括 A 类和 B 类。
测试过程中发现,StarRocks 计算两步及以上的 step_count 时会报错:

所以测试中,每次只能计算一个步骤的 step_count。
例如 3 步骤漏斗中如果计算 step1_count、step2_count、step3_count 中的任意两个或者三个,都会报这个错误。所以测试的时候只能计算三个中的一个。
最新版本 3.0 和稳定版本 2.5.3 都有这个错误。
Oracle 的 SQL 语句(A 类三步漏斗):
WITH e1 AS (
SELECT
userid,
eventtime AS step1_time,
MIN(sessionid) AS sessionid,
1 AS step1
FROM events e1
JOIN eventtype ON eventtype.id = e1.eventtype
WHERE eventtime>= to_date('2022-07-21','yyyy-mm-dd')-30
AND eventtime< to_date('2022-07-21','yyyy-mm-dd')
AND (eventtype.name = 'visit')
GROUP BY userid,eventtime
), e2 AS (
SELECT
e2.userid,
MIN(e2.sessionid) AS sessionid,
1 AS step2,
MIN(eventtime) AS step2_time,
MIN(e1.step1_time) AS step1_time
FROM events e2
JOIN e1 ON e1.sessionid = e2.sessionid AND eventtime > step1_time
JOIN eventtype ON eventtype.id = e2.eventtype
WHERE eventtime < step1_time +1
AND (eventtype.name = 'view')
GROUP BY e2.userid
), e3 AS (
SELECT
e3.userid,
MIN(e3.sessionid) AS sessionid,
1 AS step3,
MIN(eventtime) AS step3_time,
MIN(e2.step1_time) AS step1_time
FROM events e3
JOIN e2 ON e2.sessionid = e3.sessionid AND eventtime > step2_time
JOIN eventtype ON eventtype.id = e3.eventtype
WHERE eventtime < step1_time+1
AND (eventtype.name = 'detail')
GROUP BY e3.userid
)
SELECT
dt.name AS devicetype,
COUNT(DISTINCT CASE WHEN funnel_conversions.step1 IS NOT NULL THEN funnel_conversions.step1_userid ELSE NULL END) AS step1_count,
COUNT(DISTINCT CASE WHEN funnel_conversions.step2 IS NOT NULL THEN funnel_conversions.step2_userid ELSE NULL END) AS step2_count,
COUNT(DISTINCT CASE WHEN funnel_conversions.step3 IS NOT NULL THEN funnel_conversions.step3_userid ELSE NULL END) AS step3_count
COUNT(DISTINCT CASE WHEN funnel_conversions.step3 IS NOT NULL THEN funnel_conversions.step3_userid ELSE NULL END)
/ COUNT(DISTINCT CASE WHEN funnel_conversions.step1 IS NOT NULL THEN funnel_conversions.step1_userid ELSE NULL END) AS step3_rate
FROM (
SELECT
e1.step1_time AS step1_time,
e1.userid AS userid,
e1.userid AS step1_userid,
e2.userid AS step2_userid,
e3.userid AS step3_userid,
e1.sessionid AS step1_sessionid,
step1, step2, step3
FROM e1
LEFT JOIN e2 ON e1.userid=e2.userid
LEFT JOIN e3 ON e2.userid=e3.userid
) funnel_conversions
LEFT JOIN sessions s ON funnel_conversions.step1_sessionid = s.id
left join devicetype dt on s.devicetype=dt.id
GROUP BY dt.name
其中:
1、子查询 e1 是找出 to_date('2022-07-21','yyyy-mm-dd') 到 to_date('2022-07-21','yyyy-mm-dd')-30 期间,eventtype 是 visit 的 event。按照用户 userid 和时间 eventtime 分组,每组取 sessionid 的最小值作为 e1 的 sessionid,eventtime 作为 e1 的 step1_time。常数 1 是结果集 e2 的 step1 字段。
2、子查询 e2 是用 e1 和 events 表内连接。连接的条件是 e1 的 sessionid 和 events 表的 sessionid 相等,且 events 的时间要大约 e1.step1_time。连接的结果在做过滤,条件是 events 的时间要小于 e1.step1_time+1 天,且 events 的 eventtype 是 view。再按照 events 的用户 userid 分组,sessionid、eventtime、step1_time 都取最小值,分别作为结果集 e2 的 sessionid、step2_time、step1_time。常数 1 是结果集 e2 的 step2 字段。
3、子查询 e3 和 e2 大致相同,只是 eventtype 不同。
4、子查询 funnel_conversions 用 e1 左连接 e2、e3,连接条件是 userid 相同。结果中有 e1 到 e3 的 userid,有 step1 到 step3。
5、最外层查询用 funnel_conversions 的 sessionid 连接 sessions 表的 id,用 sessions 表的 devicetype 连接 devicetype 表的 id。再用 devicetype 表的 name 分组,统计每一类设备 device、每一步骤的去重用户数。且用第三步的结果除以第一步的结果, 计算总体转化率。
StarRocks 的 SQL 语句(B 类七步漏斗):
WITH e1 AS (
SELECT
userid,
eventtime AS step1_time,
MIN(sessionid) AS sessionid,
1 AS step1
FROM events e1
JOIN eventtype ON eventtype.id = e1.eventtype
WHERE eventtime>= DATE_ADD(str_to_date('2022-07-21','%Y-%m-%d') ,INTERVAL -30 day) AND eventtime< str_to_date('2022-07-21','%Y-%m-%d')
AND (eventtype.name = 'visit')
AND eventmessage like '%check%'
GROUP BY userid,eventtime
), e2 AS (
SELECT
e2.userid,
MIN(e2.sessionid) AS sessionid,
1 AS step2,
MIN(eventtime) AS step2_time,
MIN(e1.step1_time) AS step1_time
FROM events e2
JOIN e1 ON e1.sessionid = e2.sessionid AND eventtime > step1_time
JOIN eventtype ON eventtype.id = e2.eventtype
WHERE eventtime < DATE_ADD(step1_time ,INTERVAL +1 day)
AND (eventtype.name = 'view')
AND eventmessage like '%point%'
GROUP BY e2.userid
), e3 AS (
SELECT
e3.userid,
MIN(e3.sessionid) AS sessionid,
1 AS step3,
MIN(eventtime) AS step3_time,
MIN(e2.step1_time) AS step1_time
FROM events e3
JOIN e2 ON e2.sessionid = e3.sessionid AND eventtime > step2_time
JOIN eventtype ON eventtype.id = e3.eventtype
WHERE eventtime < DATE_ADD(step1_time ,INTERVAL +1 day)
AND (eventtype.name = 'detail')
AND eventmessage like '%check_point%'
GROUP BY e3.userid
), e4 AS (
SELECT
e4.userid,
MIN(e4.sessionid) AS sessionid,
1 AS step4,
MIN(eventtime) AS step4_time,
MIN(e3.step1_time) AS step1_time
FROM events e4
JOIN e3 ON e3.sessionid = e4.sessionid AND eventtime > step3_time
JOIN eventtype ON eventtype.id = e4.eventtype
WHERE eventtime < DATE_ADD(step1_time ,INTERVAL +1 day)
AND (eventtype.name = 'login')
AND eventmessage like '%check_p%'
GROUP BY e4.userid
), e5 AS (
SELECT
e5.userid,
MIN(e5.sessionid) AS sessionid,
1 AS step5,
MIN(eventtime) AS step5_time,
MIN(e4.step1_time) AS step1_time
FROM events e5
JOIN e4 ON e4.sessionid = e5.sessionid AND eventtime > step4_time
JOIN eventtype ON eventtype.id = e5.eventtype
WHERE eventtime < DATE_ADD(step1_time ,INTERVAL +1 day)
AND (eventtype.name = 'cart')
AND eventmessage like '%k_point%'
GROUP BY e5.userid
), e6 AS (
SELECT
e6.userid,
MIN(e6.sessionid) AS sessionid,
1 AS step6,
MIN(eventtime) AS step6_time,
MIN(e5.step1_time) AS step1_time
FROM events e6
JOIN e5 ON e5.sessionid = e6.sessionid AND eventtime > step5_time
JOIN eventtype ON eventtype.id = e6.eventtype
WHERE eventtime < DATE_ADD(step1_time ,INTERVAL +1 day)
AND (eventtype.name = 'confirm')
AND eventmessage like '%ck_point%'
GROUP BY e6.userid
), e7 AS (
SELECT
e7.userid,
MIN(e7.sessionid) AS sessionid,
1 AS step7,
MIN(eventtime) AS step7_time,
MIN(e6.step1_time) AS step1_time
FROM events e7
JOIN e6 ON e6.sessionid = e7.sessionid AND eventtime > step6_time
JOIN eventtype ON eventtype.id = e7.eventtype
WHERE eventtime < DATE_ADD(step1_time ,INTERVAL +1 day)
AND (eventtype.name = 'pay')
AND eventmessage like '%check_poi%'
GROUP BY e7.userid
)
SELECT
dt.name AS devicetype,
COUNT(DISTINCT funnel_conversions.step7_userid) AS step7_count
FROM (
SELECT
e1.step1_time AS step1_time,
e1.userid AS userid,
e1.userid AS step1_userid,
e2.userid AS step2_userid,
e3.userid AS step3_userid,
e4.userid AS step4_userid,
e5.userid AS step5_userid,
e6.userid AS step6_userid,
e7.userid AS step7_userid,
e1.sessionid AS step1_sessionid,
step1,
step2,
step3,
step4,
step5,
step6,
step7
FROM e1
LEFT JOIN e2 ON e1.userid=e2.userid
LEFT JOIN e3 ON e2.userid=e3.userid
LEFT JOIN e4 ON e3.userid=e4.userid
LEFT JOIN e5 ON e4.userid=e5.userid
LEFT JOIN e6 ON e5.userid=e6.userid
LEFT JOIN e7 ON e6.userid=e7.userid
) funnel_conversions
LEFT JOIN sessions s ON funnel_conversions.step1_sessionid = s.id
left join devicetype dt on s.devicetype=dt.id
GROUP BY dt.name
StarRocks 的 SQL 和 Oracle 大致相同。由于 StartRocks 会出现前面说的错误,所以最外层只计算了七步中的一步:COUNT(DISTINCT funnel_conversions.step7_userid) AS step7_count。
进行 A 类测试的时候,只需要将各个步骤中的 eventmessage 过滤条件去掉即可。
六、 SPL 测试
SPL 代码:
1、 数据转换代码
将 devicetype 表和 eventtype 表存为集文件。SPL 代码很简单:
A |
|
1 |
=file("devicetype.txt").import().new(_1:id,_2:name) |
2 |
=file("devicetype.btx").export@b(A1) |
3 |
=file("eventtype.txt").import().new(_1:id,_2:name) |
4 |
=file("eventtype.btx").export@b(A3) |
对于 sessions 表,将数据存成列存组表,按照第一个字段分段。
代码大致如下:
A |
|
1 |
=file("sessions.txt").cursor().new(_2:userid,_1:id,_3:devicetype) |
2 |
=file("sessions.ctx").create@p(#userid,#id,devicetype) |
3 |
=A2.append@i(A1) |
对于 events 表,将时间 eventtime 转为长整数,存成列存组表,按照第一个字段分段。
代码大致如下:
A |
|
1 |
=file("events.txt").cursor().new(_1:userid,_2:sessionid,_3:eventtime,_4:id,_5:eventtype,_6:eventmessage) |
2 |
=file("eventtype.btx").import@b().keys@i(id) |
3 |
=A1.new(userid,sessionid,long(eventtime):eventtime,id,eventtype,eventmessage) |
4 |
=file("events.ctx").create@p(#userid,#sessionid,#eventtime,#id,eventtype,eventmessage) |
5 |
=A4.append@i(A3) |
2、 漏斗计算代码
以 B 类七步漏斗为例,代码大致是这样的:
A |
B |
|
1 |
["visit","view","detail","login","cart","confirm","pay"] |
|
2 |
["check","point","check_point","check_p","k_point","ck_point","check_poi"] |
|
3 |
=file("eventtype.btx").import@b() |
=file("devicetype.btx").import@b() |
4 |
=A3.(A1.pos(name)) |
=A1.len() |
5 |
=long(elapse(arg_date,-30)) |
=long(arg_date) |
6 |
=long(arg_date+1) |
|
7 |
=file("events.ctx").open() |
|
8 |
=A7.cursor@mv(userid,sessionid,eventtime,eventtype,eventmessage;eventtime>=A5 && eventtime<A6 && pos(eventmessage,A2(eventtype)),eventtype:A4:#) |
|
9 |
=file("sessions.ctx").open().cursor@v(userid,id,devicetype;;A8) |
|
10 |
=A8.joinx@m(userid:sessionid,A9:userid:id,devicetype) |
|
11 |
=A10.group(userid) |
|
12 |
=A11.new(~.align@a(B4,eventtype):e,e(1).select(eventtime<B5).group@u1(eventtime):e1,e(2).group@o(sessionid):e2) |
|
13 |
=A12.derive(join@m(e1:sub_e1,sessionid;e2:sub_e2,sessionid).derive@o(sub_e2.select(eventtime>sub_e1.eventtime && eventtime<sub_e1.eventtime+86400000).min(eventtime):sub_e2_min_time,sub_e1.sessionid:sessionid).select(sub_e2_min_time):e2_1 ) |
|
14 |
=A13.new(e1.id(devicetype):e1_id_devicetypeno,ifn(e2_1.min(sub_e1.eventtime),1):e1_min_time,e2_1.min(sub_e2_min_time):e2_min_time,${to(3,B4).("e("/~/").select(sessionid==e"/(~-1)/"_1.min(sessionid) && eventtime>e"/(~-1)/"_min_time && eventtime<e1_min_time+86400000):e"/~/"_1,e"/~/"_1.min(eventtime):e"/~/"_min_time").concat@c()}) |
|
15 |
=A14.news(e1_id_devicetypeno;~:devicetype ,${B4.("e"/~/"_min_time").concat@c()}) |
|
16 |
=A15.groups(devicetype;${B4.("count(e"/~/"_min_time):STEP"/~/"_COUNT").concat@c()}) |
|
17 |
=A16.new(B3(devicetype).name:DEVICETYPE,${B4.("STEP"/~/"_COUNT").concat@c()},STEP${B4}_COUNT/STEP1_COUNT:STEP${B4}_RATE) |
|
传入参数 arg_date 是日期,例如 2022-07-21。
A1 是事件类型 eventtype,A2 是每种类型对应要查找 eventmessage 的字符串。为了方便阅读,这里是写定的 7 个事件,实际上只要是 2 个以上事件就可以,作为参数动态传入,下面的代码不用做任何修改,就可以计算 2 步以上任意步骤的漏斗转化率。
A3、B3 装入 eventtype 表、devicetype 表。
A4 把 eventtype 表中,计算用到的类型依次设置为整数 1,2,3…,其他都是 null。
A5、B5、A6:对参数 arg_date 求 30 天前、1 天后的日期,三者都转为长整数 long。
A7:打开 events 组表对象。
A8:events 过滤出需要的类型事件,且满足 eventmessage 条件,日期要多取出一天。建立多路的列式游标。
A9:建立 sessions 游标,按照 A8 分段。
A10-A11:event 和 session 两个列式游标有序归并,按照 userid 分组。
A12:每个 userid 分组内,eventtype 按照 1,2,3,…对齐分组,分别依次对应各个事件类型。
A13:e1 和 e2 按照 sessionid 有序归并,结果计算出满足条件的 eventtime 最小值。过滤出最小值不为空的记录。
A14:e1 对 devicetype 去重,且将 e1 和 e2 归并的结果求 eventtime 最小值和 sessionid 最小值。从 e3 开始过滤出符合 sessionid 和时间条件的记录,也就是 e3 到 e7 中符合条件的 event。这里使用了宏,实际执行的语句是:
=A13.new(e1.id(devicetype):e1_id_devicetypeno,ifn(e2_1.min(sub_e1.eventtime),1):e1_min_time,e2_1.min(sub_e2_min_time):e2_min_time, e(3).select(sessionid==e2_1.min(sessionid) && eventtime>e2_min_time && … && eventtime<e1_min_time+86400000):e7_1,e7_1.min(eventtime):e7_min_time)
A15:在 A14 游标基础上计算去重后的 devicetype,求 e2 到 e7 的时间最小值,合并到原游标。实际执行的语句是:
=A14.news(e1_id_devicetypeno;~:devicetype,e1_min_time,e2_min_time,e3_min_time,e4_min_time,e5_min_time,e6_min_time,e7_min_time)
A16:对 A15 做小结果集分组汇总,分组字段是 devicetype,每组求各个步骤的计数值。实际执行的语句是:
=A15.groups(devicetype;count(e1_min_time):STEP1_COUNT,count(e2_min_time):STEP2_COUNT,…,count(e7_min_time):STEP7_COUNT
A17:将 A16 序表中的 devicetype 从序号转化为名称。实际执行的语句是:
=A16.new(B3(devicetype).name:DEVICETYPE,STEP1_COUNT,STEP2_COUNT,STEP3_COUNT,STEP4_COUNT,STEP5_COUNT,STEP6_COUNT,STEP7_COUNT,STEP7_COUNT/STEP1_COUNT:STEP7_RATE)
进行 A 类测试的时候,只要将 A8 中 eventmessage 的过滤条件去掉即可。
七、 测试结果
一、A 类测试(无 eventmessage 条件):
三步漏斗 |
VM1:32G |
VM2:16G |
VM3:8G |
VM4:6G |
VM5:4G |
SPL |
27 |
26 |
28 |
26 |
28 |
StarRocks |
53 |
51 |
62 |
64 |
溢出 |
Oracle |
418 |
- |
- |
- |
- |
七步漏斗 |
VM1:32G |
VM2:16G |
VM3:8G |
VM4:6G |
VM5:4G |
SPL |
30 |
32 |
28 |
33 |
34 |
StarRocks |
122 |
114 |
152 |
155 |
溢出 |
Oracle |
1827 |
- |
- |
- |
- |
二、B 类测试(有 eventmessage 条件):
三步漏斗 |
VM1:32G |
VM2:16G |
VM3:8G |
VM4:6G |
SPL |
35 |
39 |
39 |
52 |
StarRocks |
210 |
210 |
192 |
溢出 |
七步漏斗 |
VM1:32G |
VM2:16G |
VM3:8G |
VM4:6G |
SPL |
46 |
61 |
52 |
92 |
StarRocks |
510 |
520 |
溢出 |
溢出 |
三、说明:
1、 表中数值是计算所用时间,单位是秒。
2、Oracle 计算时间较长,所以仅测试了 A 类的 VM1。
3、StarRocks 在计算两步以上的时候会出现错误,所以只能计算一步。
八、 结果点评
1、 SPL 计算漏斗统计的性能最好,StarRocks 较差,Oracle 最慢。SPL 计算速度比 StarRocks 快 2 到 5 倍,比 Oracle 快 15 到 60 倍。
2、 A 类测试中漏斗计算的步骤从 3 步变 7 步时,StarRocks 计算速度降低了近 2 倍。SPL 变化则不明显。这是因为 SQL 前后步骤之间要按照 sessionid 或 userid 做 JOIN 计算,漏斗步数越多 JOIN 计算的次数越多,性能自然会相应的下降。SPL 则是将相同的 userid 和 sessionid 放在一起算,避免了反复的 JOIN。
3、 其他条件相同时,B 类计算普遍要比 A 类慢。但相比之下,SPL 差距小,StarRocks 差距大。StarRocks 的向量式计算能利用 CPU 特性提速,但只对 int/long 这种简单数据类型有效,对字符串这种复杂数据类型无效,涉及到字符串计算时性能会较大幅度下降。
4、 StarRocks 限制了内存上限(物理内存的 80%),在虚拟机内存减少时会出现内存溢出错误,无法计算出结果。因为 SQL 的 JOIN 是内存计算,需要消耗更多的内存。特别是 B 类测试有字符串参与计算,内存占用更大,所以更容易出现溢出错误。而 SPL 避免了反复 JOIN,可以用很少的内存正常运算出结果。
5、 测试结论:
SPL 可以利用有序存储,非常适合用于漏斗统计这种用户行为分析计算:总数据量很大,但每个 userid 的数据量并不大。按照 userid 和 sessionid 有序存储数据,不仅可以获得极致性能,而且代码更简洁。
漏斗统计相当复杂,勉强用 SQL 写出来,也只能用反复 JOIN 的办法,用老牌数据库 Oracle 还能得到正确结果,但是性能很差。StarRocks 出现时间较短,面对这样的复杂 SQL 直接报错了,仅计算一步的时候可以跑,但性能仍然远远不如 SPL,如果计算多步,计算速度会更慢了。


👍
英文版