使用相关系数选择变量
相关系数是度量两个变量之间相关程度的统计量,常用的有Pearson相关系数和Spearman相关系数,两者值均在[-1,1]之间分布,当其值为0时两个变量不想关,当其值为1或-1时,表示两个变量完全正相关或负相关,相关系数的绝对值越大,说明两个变量的相关性越强。
例如,对信用卡欺诈检测数据中的变量,使用相关系数法进行变量选择,筛选标准为Pearson或Spearman的绝对值大于0.5.
A |
B |
C |
|
1 |
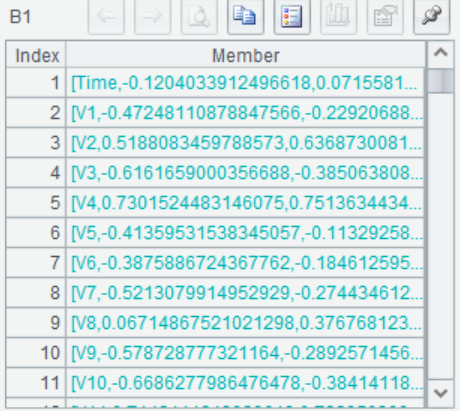
=file("D://test//creditcard_b.csv").import@tc() |
||
2 |
=A1.fname() |
||
3 |
=A2.delete(A2.pos("Class")) |
||
4 |
for A2 |
=pearson(A1.(${A4}),A1.(Class)) |
|
5 |
=spearman(A1.(${A4}),A1.(Class)) |
||
6 |
>B1=B1|[A4|B4|B5] |
||
7 |
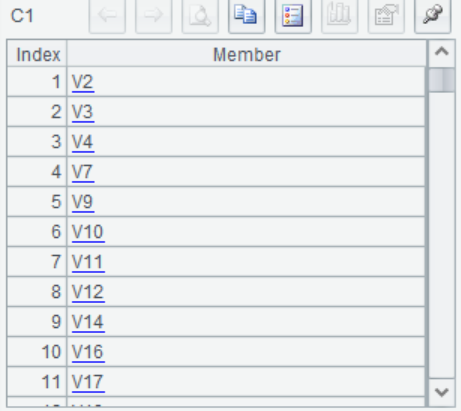
=if(abs(B4)>0.5 || abs(B5)>0.5,A4) |
||
8 |
>C1=C1|B7 |
A2-A3 取除目标变量外的字段名
A4-B8 循环所有自变量,分别计算和目标变量的相关系数,存入B1,并筛选出pearson或spearman相关系数大于0.5的变量名称存入C1。