"您好,我在使用集算器解析 JSON 时如果 json 字段有缺失的 id,看着 jdbc 会直接报错,这个有办法解决吗,这种情况我感觉应该是返回空值呀,而不是报错 [ { &nbs .."
您好,我在使用集算器解析 JSON 时如果 json 字段有缺失的 id,看着 jdbc 会直接报错,这个有办法解决吗,这种情况我感觉应该是返回空值呀,而不是报错
[ { "ksId":"ddsss", "ksUserId":"ddddddd" }, { "ksid":"ddsss", "ksUserId":"ddddddd" } ]
如上图,数据传输时有一条数据把 ksId 写成了 ksid,整个计算就开始报错了
解析 json 时 json 结构要相同,你这个第一条是 ksId,第二条是 ksid,i 大小写不同,看下能否转换成一致的
对,这是正常的 json 肯定是相同的,但是总会有异常数据,这种情况感觉好像不太友好呀,没办法保证数据一定是规整的,这种目前有办法解决么😂
json 解析没有这个要求,随便什么乱结构都可以
出错是因为后面的 new,引用了不存在的字段(json 里没有就不会生成),动态引用可能不存在的字段可以用 field
测试了一下,感觉好像是正解了,感谢👍
请问怎么写的?
表达式 =json(?).new(ksid) 报错是 new 导致的,因为有的记录没有 ksid 字段,不能直接用字段名引用可以改成 =json(?).new(~.fiend(“ksid”)),field 函数如果找不到字段会返回 null,不会抛异常。
🙏




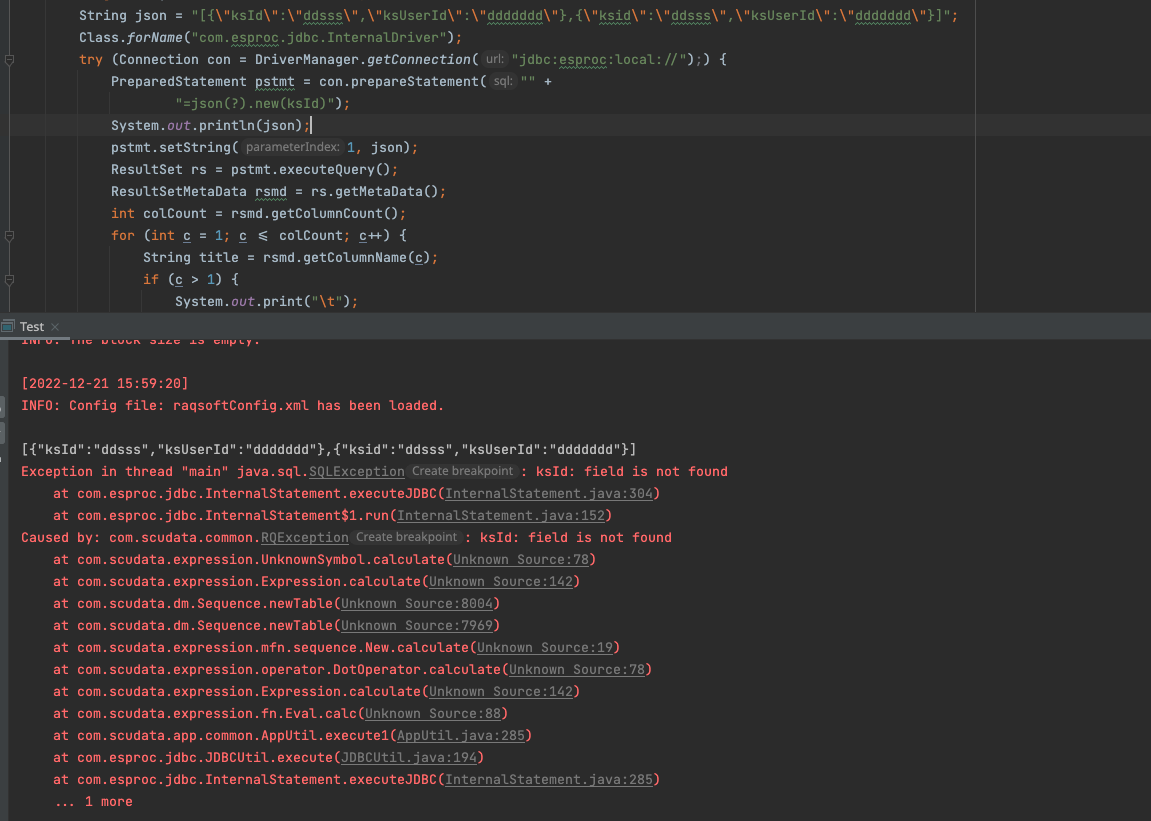

如上图,数据传输时有一条数据把 ksId 写成了 ksid,整个计算就开始报错了
解析 json 时 json 结构要相同,你这个第一条是 ksId,第二条是 ksid,i 大小写不同,看下能否转换成一致的
对,这是正常的 json 肯定是相同的,但是总会有异常数据,这种情况感觉好像不太友好呀,没办法保证数据一定是规整的,这种目前有办法解决么😂
json 解析没有这个要求,随便什么乱结构都可以
出错是因为后面的 new,引用了不存在的字段(json 里没有就不会生成),动态引用可能不存在的字段可以用 field
测试了一下,感觉好像是正解了,感谢👍
请问怎么写的?
表达式 =json(?).new(ksid) 报错是 new 导致的,因为有的记录没有 ksid 字段,不能直接用字段名引用
可以改成 =json(?).new(~.fiend(“ksid”)),field 函数如果找不到字段会返回 null,不会抛异常。
🙏