


SPL 和 SQL 能不能融合在一起?
SQL 和 SPL 都是面向结构化数据的通用处理技术。SQL 普及率高受众广,很多用户天生就会用 SQL 查询数据,如果数据引擎支持 SQL 就会很容易上手,而且历史程序也相对容易迁移;SPL 则具备简洁高效的特点,提供了更加敏捷的语法可以简化复杂计算,同时支持过程计算天然支持分步编码,计算体系更加开放可以同时针对多种数据源混合计算,利用内置的高性能存储和高性能算法容易获得更高的计算性能,在使用时更加灵活既可以独立使用也可以嵌入应用集成使用。
那么在实际应用中能否在一个数据运算体系中将 SQL 和 SPL 融合使用,根据不同场景分别使用不同的技术,以便发挥各自的优势呢?
要回答这个问题我们要从几方面来讲。
先看在已经支持 SQL 的数据库上是否能提供对 SPL 的支持。
原则上,所有的关系数据库都可以作为 SPL 的数据源,SPL 通过数据库提供的接口读取数据进行计算,读取数据时仍然使用 SQL 但后续计算完全由 SPL 完成。这虽然与使用 SQL 直接在数据库内计算不同,但对应用来讲只是计算的实施位置不同,对于应用请求和使用数据并没有太大区别,因此从这个角度来讲二者可以很好融合在一起使用。
但是,我们还要回答为什么要在 SQL 的基础上增加 SPL?肯定是要解决某些问题。
如果是功能性的需求,那没问题。有些计算用 SQL 很难写甚至写不出,用 SPL 可以简化计算。比如计算一支股票最长连续上涨了多少天?用 SQL 写出来很绕:
select max (consecutive_day)
from (select count(*) (consecutive_day
from (select sum(rise_mark) over(order by trade_date) days_no_gain
from (select trade_date,
case when closing_price>lag(closing_price) over(order by trade_date)
then 0 else 1 END rise_mark
from stock_price ) )
group by days_no_gain)
这样的语句难写难懂又难调试,在实际业务中经常会混在多步的复杂过程中,加大开发和维护难度。而读出来再用 SPL 计算就简单多了:
db.query("select closing_price from stock_price order by trade_date").group@i(closing_price<closing_price[-1]).max(~.len())
而且很容易调试,大大降低开发维护成本。
借助 SPL 的敏捷语法和过程计算等特性经常能大幅简化算法实现难度。所以, SPL 可以作为 SQL 的很好补充。而且 SPL 提供了 JDBC 接口,完全可以封装成和使用数据库一样。
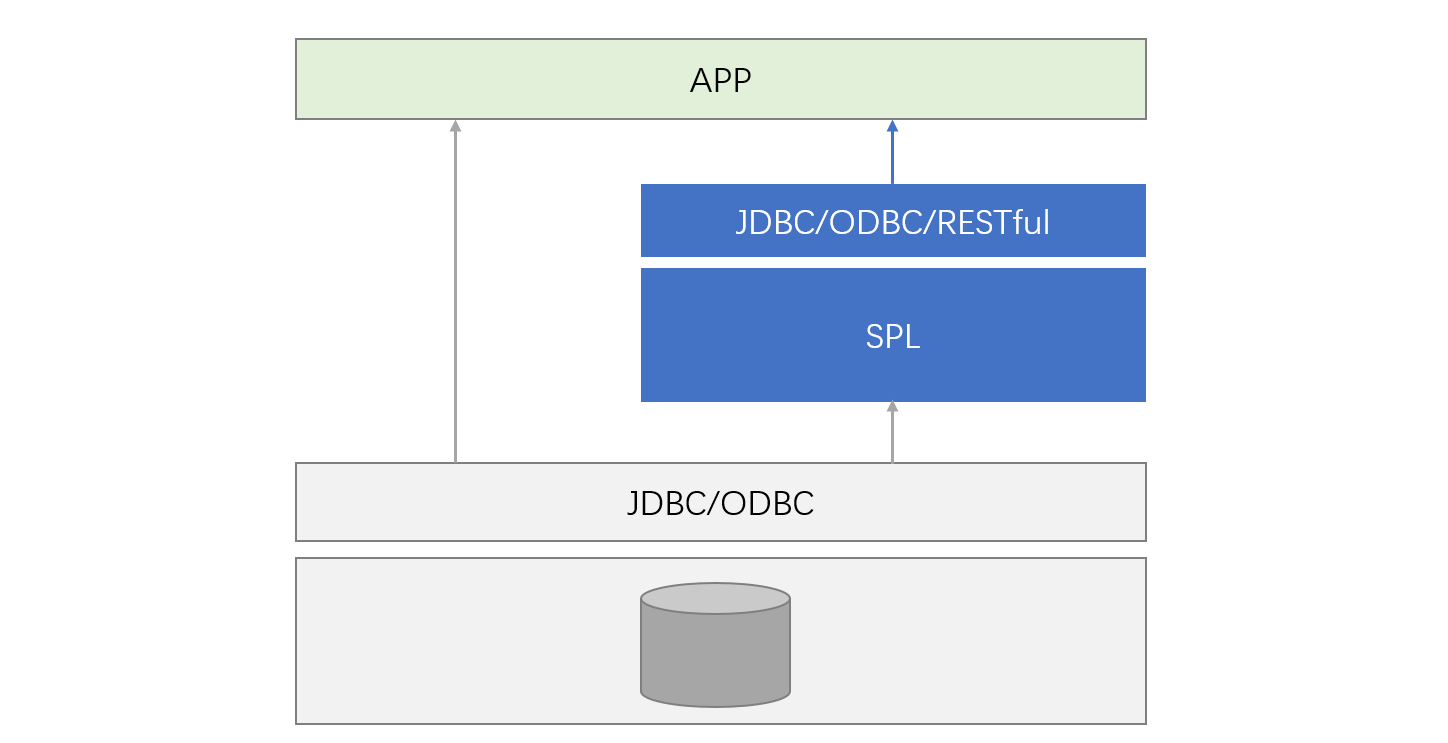
但是,如果要解决的是性能问题就没这么简单了,对于功能已经稳定的存量系统面临的绝大多数问题可能都是性能问题,引入 SPL 就是要来提速的。SPL 中有丰富的高性能算法类库,是否可以用在这里提高性能呢?
非常遗憾,大概率不可以!我们很难在现有数据库(SQL 体系)上使用 SPL 来提高性能。原因在于数据存储,即数据组织形式。
我们知道高性能算法和数据存储密切相关,SPL 也不例外。想要充分发挥 SPL 高性能算法的效力就需要将数据按照一定形式来组织。比如 SPL 的单边分堆算法就要求数据有序存储;有序归并也要求数据按照关联键有序;外键序号化则需要事先将外键值改造成维表的序号再使用;…… 类似的情况还有很多,要实施高性能算法就必须有存储做基础,而数据库的存储对外不透明没法干预,想要根据计算特征调整存储更做不到,基于数据库的存储通常也就无法再利用 SPL 中的算法实现高性能计算了。
在现有数据库体系上融合 SQL 和 SPL 要看实际需要,SPL 能基于 SQL 数据库工作,但获得不了高性能。
那么,能不能反过来,在 SPL 中提供 SQL 支持呢?即在一个体系之内提供两种查询语法。
目前 SPL 的确提供了一定的 SQL 支持,称之为简单 SQL。在 SPL 内部可以使用简单 SQL 查询文本、NoSQL、WebService 等多种数据源,支持过滤、关联、子查询等操作(与 SQL92 标准相当),对于熟悉 SQL 的小伙伴使用起来也会比较方便。比如可以在 SPL 内嵌入:
select e.Dept,sum(o.Amount) from d:/Orders.csv o
left join d:/Employees.xlsx e on o.SellerId=e.Eid
group by e.Dept
来实现文件上的运算。
但是,这种用法仍然无法保证高性能,而且只能支持相对简单的场景,比如只能针对小数据集查询。出现这个现象的原因有两方面,一方面是 SPL 团队不是专业的 SQL 实现者,不容易做出非常完善且高效的 SQL;另一方面 SQL 本身存在一些限制导致技术上很难再向上突破,因此也没有太大意愿继续完善 SQL。
那能不能将 SQL 自动转化成 SPL 呢?应用 / 使用者负责生成 SQL 交给 SPL,SPL 将接收到的 SQL 进行翻译从而转化成 SPL 原生语法再执行。
理论上来讲,SPL 是 SQL 的超集,任何 SQL 实现的计算的确都可以使用 SPL 来完成,解释或移植 SQL 是可能的,虽然这也有不少工作量,但难度并不是非常大。不过,这样做只能获得语法的兼容性,仍然不能得到高性能。SQL 本身就存在实现高性能算法的限制,由于缺乏一些关键的数据类型(如记录类型)和基本运算(如有序计算)导致很多高性能算法都无法描述,通过很绕的方式实现往往性能就很低了,再翻译过来性能就更差,甚至大数据根本跑不了。高效的代码要针对运算模型的特征去编写,而 SQL 语句中通常并没这样的信息。比如 TopN 计算:
SELECT TOP 10 x FROM T ORDER BY x DESC
这句 SQL 表达出来的执行逻辑是对所有数据进行大排序,然后再取出前 10 个。大数据排序很慢,会涉及多次内外存交互,如果按照表面的意思去执行效率会很低。但传统数据库通常有很强的优化引擎,可以猜出 SQL 的实际意义并进行有效优化而不会按照 SQL 的表面意思执行。像这个 TopN 运算,数据库优化引擎就有办法采用避免大排序的更高效执行方式,而这种高效算法在 SPL 语法中也很容易实现,但是如果只是原样翻译 SQL 语句的执行逻辑就只能进行大排序,用不了高效算法,也就无法保证高性能了。
关系数据库诞生了几十年,数据库优化工作从未停止,这些能力需要丰富的经验和长时间的不断投入才能完成。相比之下,SPL 团队的这个能力远远不如传统数据库厂商,基本做不了这事,如果要做翻译,通常也只能硬搬 SQL 的执行逻辑,那性能就会非常低下。这个任务,只能等 SPL 普及较多后,由传统数据库厂商利用自己的经验来做。
那么在实际应用中,SQL 和 SPL 该如何分工呢?
OLTP 业务目前使用 SQL 还是相对必须的(SPL 的 OLTP 功能还在路上),使用 SPL 做分析需要先将业务数据(通常是冷数据)同步到 SPL 存储中再使用,这样就可以获得高性能。同时借助 SPL 的 T+0 查询能力可以完成全量数据的实时查询( 开源 SPL 轻松应对 T+0 ),还可以配合 OLTP 数据库实现 HTAP 需求( HTAP 数据库搞不定 HTAP 需求 )这样就可以同时享受到 SQL 和 SPL 的便利。
对于新建的 OLAP 系统,可以直接使用 SPL 的自有存储和计算能力完成而不涉及 SQL,如数据仓库、数据中台、数据湖建设等,这样不仅可以享受 SPL 的高性能而且 SPL 代码比 SQL 也更简单。
数据中台为什么不好搞?
现在的湖仓一体像是个伪命题
对于存量 OLAP 系统希望通过 SPL 提升性能时,需要根据实际场景决定,通常先是哪痛医哪,将具体问题涉及的数据转存到 SPL 再利用 SPL 的高性能计算来提速。
随着应用的深入可以将原来的 SQL 实现逐步迁移到 SPL 中实现性能优化的同时还能改善应用结构。
开源 SPL 消灭数以万计的数据库中间表
爱恨交加的存储过程该往何处去?
ETL 为什么经常变成 ELT 甚至 LET?
总的来说,在一定程度内(相对简单的情况)兼容 SQL 可以方便用户使用,但如果想要进一步发挥 SPL 的效力去解决 SQL 解决不了的问题时就需要基于 SPL 存储使用原生 SPL 语法完成,继续深入兼容 SQL 既不现实也无必要。


英文版