




报表中总是得写 java 程序怎么办
为什么会用到 JAVA
数据信息化项目中的报表,现在基本都有报表工具来做了,用工具就是为了解决手工做的麻烦和困难,为啥用了工具还得手工写 JAVA 呢?而且要写的情况还挺多
这个问题其实不能完全怪报表工具,报表工具的作用是提升报表制作的效率,在这一点上,它是完全可以胜任的,而且做的很好,但报表整个生命周期中的难题,除了制作外,还有一个是在数据准备阶段,这个阶段的难题,就不是所有报表工具都可以解决的了
每一个报表,都需要把数据整理计算准备好以后,才可以进入到报表制作的环节,数据的准备阶段,有的简单,有的复杂,简单的,用 SQL 就可以轻松搞定,业务逻辑复杂的,SQL 写起来困难或者写不了,那就得用 JAVA 等高级语言去准备了
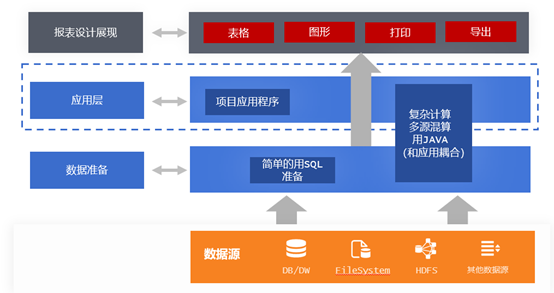
而且数据多元化的时代,用户的数据有着各种类型的存储方式,有来自 NOSQL,有的来自 TXT 、EXCEL、CSV 等文件,有的是 XML、JSON,有的是 Webservice,还有 HDFS、Elasticsearch、Kafka 等等,这些又大部分都不能用 SQL 来直接处理和计算,尤其是出现多种来源混合计算的时候,也只能用 JAVA 来写了
这就是为什么做报表的时候还得频频用 JAVA 的原因,也是为什么几乎所有报表工具都留了程序员自定义数据源接口、而且并非摆设经常被用的原因
用 JAVA 的弊端
用 JAVA 其实也有优势,就是自由,JAVA 写得好,遇到啥都能解决
但是弊端却也很明显
JAVA 开发成本高
本来人就贵,结果做个报表还得会写 JAVA 的,人工成本自然就会高很多,项目和公司的压力就会很大
工作量还大,JAVA 这类高级语言,对结构化数据的计算支持很有限,虽然都能做,但却能力比较弱,写起来非常繁琐,简单做个求和运算都需要写数行代码的循环来实现,而报表数据源处理则大量涉及批量数据运算,采用高级语言开发时会导致动辄数百行的冗长代码,编写、调试和后续维护都会很困难,开发成本也会高出很多
JAVA 破坏应用架构
造成高耦合
报表和应用的关系,原本是松散低耦合的,报表模板以文件形式存放在服务器文件系统中,
独立管理和应用互不影响
但 JAVA 程序写的自定义数据集就不行了,这部分代码将作为应用程序的一部分被一起编译和打包,有啥改动,都需要改两处,很容易导致不一致,报表做起来又没完没了,还得 JAVA 开发人员一直跟着
不能热切换
报表原本是支持热切换的,报表开发人员对报表模板的修改或者新增,都不需要重启应用,直接刷新浏览器就可以
但有 JAVA 自定义数据集的报表就不行了,每改动一次,都需要重新编译,都得整个项目陪着重启甚至停机,严重影响了应用和项目的稳定
怎么解决
频繁的使用 JAVA 是因为报表工具不具备良好的数据准备功能,如果报表工具可以很好的做好数据准备,具备了这样的能力,那问题就解决了
润乾报表就具备这样的能力,它集成了开源的的集算器 SPL,可以轻松应对各类数据准备的难题
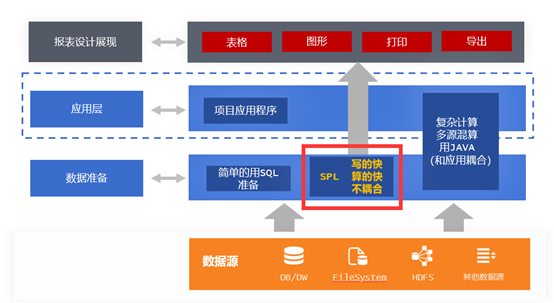
SPL 是一款流行的专业的数据计算处理工具,很多项目开发商都在用,因为它不仅能解决问题,而且还免费,开源,是常年做项目,总需要做数据处理的工程师的好帮手
集成 SPL 后,润乾报表相当于多了一个计算层,这个计算层相对 JAVA 做数据准备有如下优势:
支持各类数据来源
直接连接各类数据来源使用

简单易上手
易学易懂,初级工程师就可以搞定,不再非得需要 java 人员了
| A | B | |
|---|---|---|
| 1 | =httpfile(“http://125.125.315.88:6868/demo/order.json”:“utf-8”).read() | 读取 Restful 数据 |
| 2 | =json(A1) | 解析数据 |
| 3 | =connect(“oracle”) | 连接 oracle 数据源 |
| 4 | =A3.query(“select 订单 ID, 回款 ID, 客户 ID, 金额 from 回款表”) | 从 oracle 取数 |
| 5 | =join(A2:order, 订单 ID;A4:hk, 订单 ID) | 关联计算 |
提升报表开发效率
SPL 计算层有更高效的函数和符合自然思维的写法,可以大大提升了报表数据准备阶段的开发效率,比如下面这个小例:
例子:报表中需要呈现连续上涨超过 5 天的股票及上涨天数
这样的报表,制表时候只需要设计几个格子,很简单,但数据准备却不简单,大部分的工作量都得花在这个数据的准备上
用 SQL 来算的话,得写好几层嵌套
select code,max(risenum)-1 maxRiseDays
from (
select code,count(1) risenum
from(
select code,changeSign,sum(changeSign) over(partition by code order by ddate) unRiseDays
from(
select code,ddate,case when price>=lag(price) over(partition by code order by ddate)
then 0 else 1 end changeSign
from stock_record
)
)
group by code,unRiseDays
)
group by code
having max(risenum) > 5
用 Java 写那要再长十几倍,没法列在这里了。而且经验不足的人可能还写不出来
而用润乾计算层的 SPL,则短短两行就可以搞定,而且逻辑也更清晰易懂
| A | B | |
|---|---|---|
| 1 | =db.query(“select * from stock_record order by ddate”) | |
| 2 | =A1.group(code;~ .group@i(price < price[-1]).max(~.len()):maxrisedays) | 计算每只股票的连续上涨天数 |
| 3 | =A2.select(maxrisedays>5) | 选出符合条件的记录 |
(注释:导入股市数据表,并按日期排序。使用函数 group 的选项 @o,根据股价是否上涨进行分组。分组时只和相邻的对比,当股价是否上涨发生变化时产生新组。计算出每支股票连续上涨的最大天数,最后选出连续上涨超过 3 天的)
更多的提升效率的实际具体案例可以参考:
避免应用耦合支持热切换
SPL 作为润乾报表的计算层,它编写的计算脚本和报表模板一样,都是解释执行的,而且可以直接放到报表模板里面,就相当于报表工具同时也负责了数据准备任务,这样报表维护时很容易保证这两部分一致,避免了应用耦合的问题
解释执行的 SPL 同时也具备了热切换的能力,不会再因为报表数据的改动影响应用的稳定了,重新上载报表及其数据准备脚本后就能立即生效
说在最后
像润乾报表这样的集成了高效的数据计算层的报表工具,就可以轻松应对那些不得不频繁使用 JAVA 自定义数据的场景了,项目开发商也不必再为投入过多的人工成本而苦恼了,而且润乾报表本身也好用便宜,是广大的开发商伙伴们信赖的工具,1W 一套,3W 一年随便用,用润乾不仅能 0 成本解决数据计算和准备的难题,还能低成本解决报表工具成本的问题,一举两得了
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

