


巨大量的订单及明细的关联如何提速?
订单和明细表如下图,订单表主键是订单号(id),明细表主键是订单号(id)和产品号(productid)。订单和明细表要按照订单号关联计算,比如:按客户和订单日期分组汇总订单金额,分组字段是订单表的客户号、订单日期,订单金额则等于明细表的单价乘以数量。
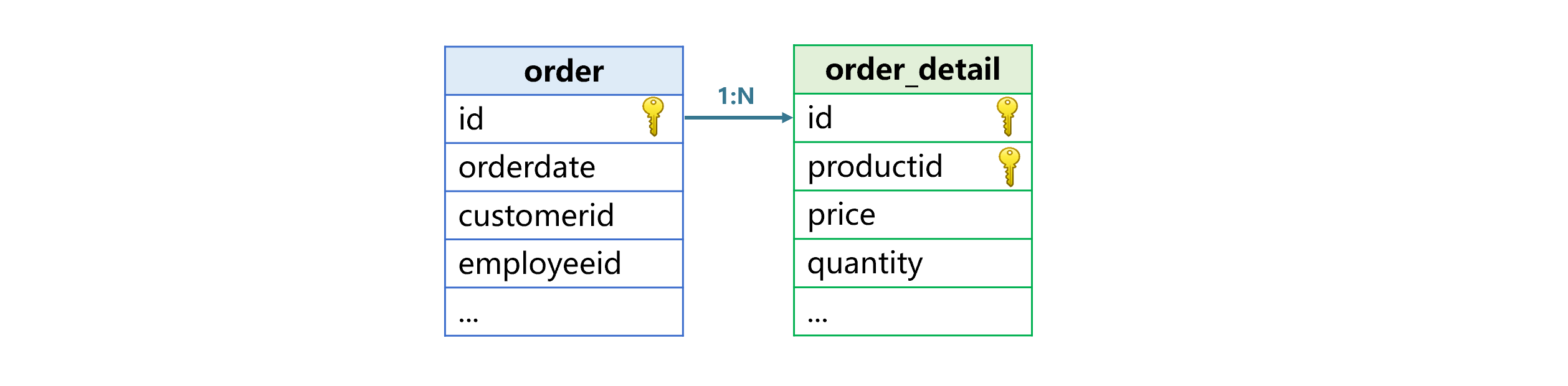
类似订单和明细表的关联比较常见,主要特征是:关联字段是主键或部分主键;表与表是一对一,或一对多关系;一对多关系的表也可以称为主子表,一个主表可以有多个子表。
在 SQL 中,这种关联计算就是 JOIN,数据库会采用 HASH JOIN 算法。在两个表都很巨大的情况下,常常出现计算速度非常慢的现象。这是因为 HASH JOIN 本质上是内存运算,数据量巨大的时候需要做分堆缓存才能把大数据 JOIN 转换成若干小数据 JOIN,IO 开销很大,HASH 运气不好时还可能多次缓存。而且,HASH 分堆技术实现并行比较困难,多线程时会造成共享资源冲突,还要消耗大量内存,难以发挥并行的性能优势。
如果预先将两表都按照主键有序存储,就可以使用归并算法实现关联。这种有序归并算法只需要对两个表依次遍历,不必借助外存缓存,可以大幅降低 IO 量。有序归并算法的复杂度是加法级的,相比乘法级的 HASH JOIN,复杂度降低很多,性能会大幅提升。
排序成本很高,每次都排序会导致总体性能还不如直接 HASH JOIN 算法。不过,这类订单表和其明细表之间只会按主键关联,不会针对其它字段关联。这种主键(或部分主键)之间关联的场景非常多,能解决这个场景应用面就足够广了。预先按照主键排序虽然慢,但是一次性的,而且只需要保持主键有序这一种存储即可,并没有冗余。
有序归并还易于分段并行。并行计算时需要把数据分成多段,单个表分段比较简单,但两个关联表分段时必须同步对齐,否则归并时两个表数据会错位。而数据按照关联字段有序就可以保证同步对齐分段,可以充分利用并行的性能优势。
SQL 语言采用笛卡尔积定义的 JOIN 运算,不区分 JOIN 类型,不假定某些 JOIN 总是针对主键的,就没办法从算法层面上利用关联字段是主键(或部分主键)的特征,只能在工程层面进行优化。有些数据库会检查数据表在物理存储上是否针对关联字段有序,如果有序则采用归并算法,但基于无序集合概念的关系数据库不会刻意保证数据的物理有序性,许多操作都会破坏归并算法的实施条件。使用索引可以实现数据的逻辑有序,但物理无序时的遍历效率还是会大打折扣。
开源的集算器 SPL 语言支持有序归并算法,实现订单、订单明细关联计算的代码大致是这样的:
1. 先对两表排序,实现有序存储
A1=file("order_original.ctx").cursor().sortx(id) // 原订单表按主键(订单号)做外存排序
A2=file("order_detail_original.ctx").cursor().sortx(id,productid)
// 原定单明细表按主键(订单号、产品号)做外存排序
>file("order.ctx").create(#id,…).append(A1)
// 新建订单表,对主键有序,追加数据
>file("order_detail.ctx").create(#id,#productid…).append(A2)
// 新建订单明细表,对主键有序,追加数据
2. 然后就可以进行有序归并计算
A1=file("order.ctx").open().cursor@m(id,customerid,employeeid,orderdate)
// 生成订单表的多路游标,多线程并行读取数据
A2=file("order_detail.ctx").open().cursor(id,productid,price,quantity;;A1)
// 基于 A1 生成订单明细的多路游标,分段与 A1 对齐,相同的订单号不会错位
A3=joinx(A1:id,o;A2:id,od)
// 两个游标按照订单编号有序归并
… // 归并后再做其他计算
实际测试表明,在同等硬件条件下,即使不使用列存的优势,SPL 计算大数据量订单及明细关联计算的速度也能比 Oracle 快出数倍到数十倍!
对比测试看这里:性能优化技巧:有序归并


英文版