


没完没了的报表开发怎么破?
报表业务的稳定性天生很差,业务开展过程中会催生出许多新的查询统计需求,报表就要随之不停增加、修改,这就造成了没完没了的报表。一般企业信息系统上线后主要功能模块都相对稳定不再变化,只有报表会随着整个系统生命周期不断变化调整,十分耗费精力。
如何搞定没完没了的报表开发呢?
要回答这个问题,首先我们要考虑报表变化的问题能否消除?
答案是否定的。
报表需求是业务的真实需求,无法消除只能适应。
如何更快速、低成本地适应没完没了的报表开发呢?可以尝试如下五步。

一. 引入报表工具
使用报表工具画报表,快速搞定报表呈现方面的工作。这步大部分用户都已实现,使用了报表工具开发报表。
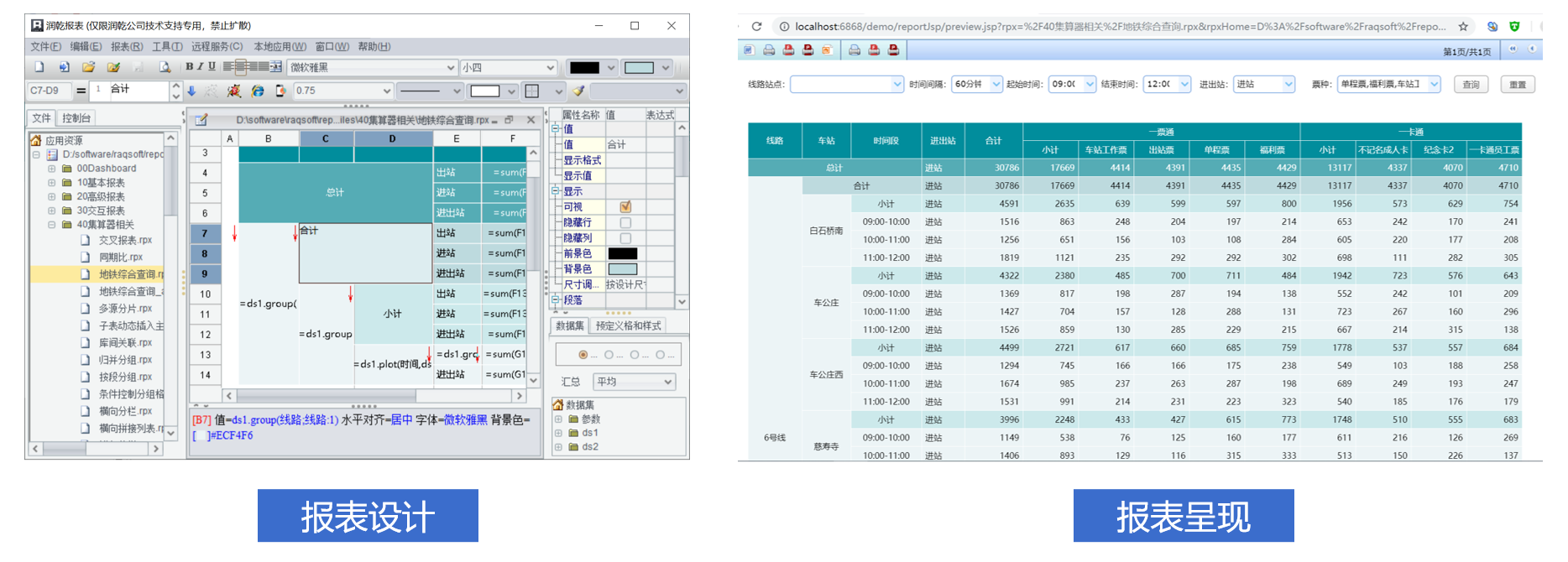
二. 引入计算工具
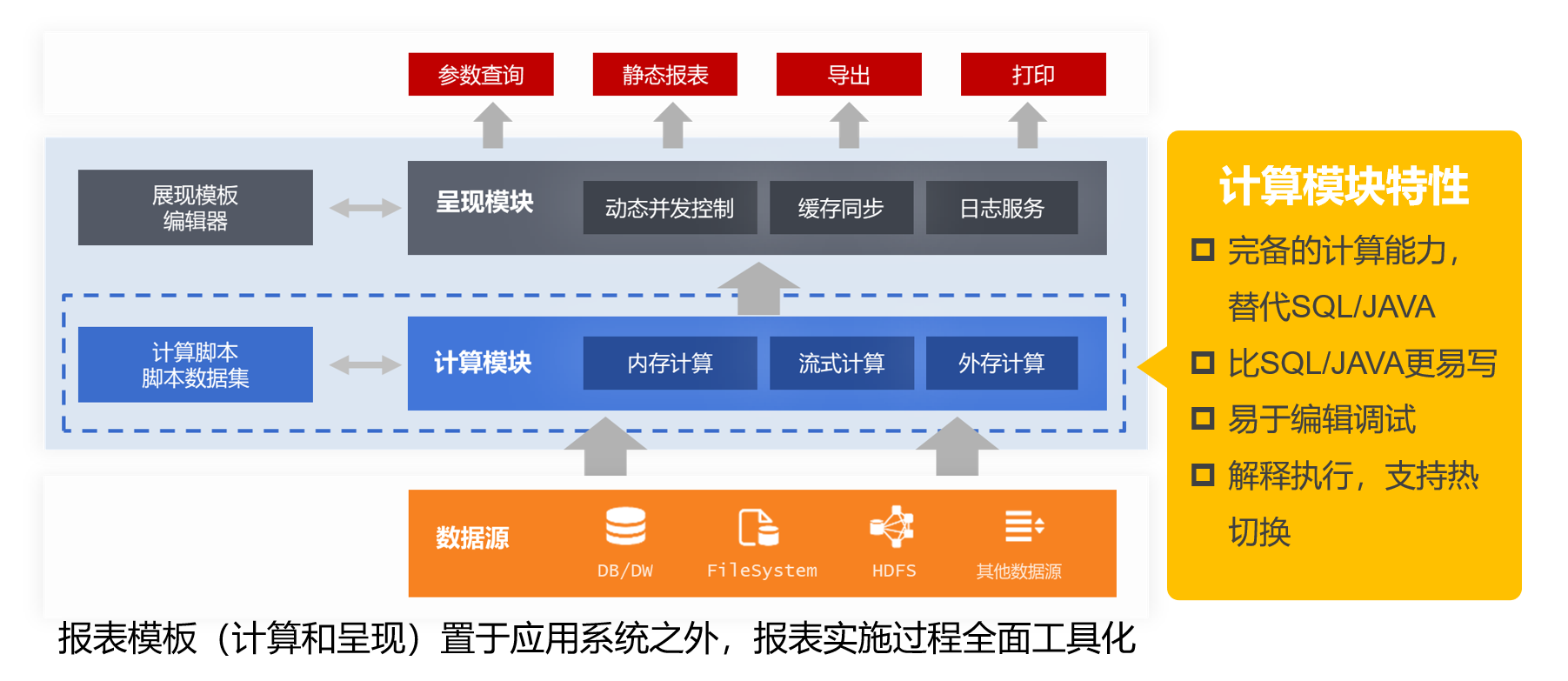
报表开发除了呈现(图表)方面的工作,还有数据准备。以往使用复杂 SQL/ 存储过程 /Java 实现方式过于原始,开发效率低,对人员要求也高。要提升数据准备开发效率要引入专用计算工具,让报表数据准备也工具化!

这个工作可以使用集算器 SPL 完成,一个专门用于报表数据准备的计算工具,开源免费。借助集算器的敏捷语法 SPL 可以快速完成报表数据准备,一般报表开发人员就能胜任,让报表数据准备也工具化,加上报表工具(数据呈现)可以让整个报表开发过程工具化,从而降低报表开发成本。
集算器提供了优于 SQL 的敏捷语法—SPL,算法实现更加简洁。比如根据月度销售额表查询每次第一个月比上季同月的增长额,及销售情况(有些月可能无数据)。
A |
|
1 |
=db.query(“select * from sales”).align@1([1,4,7,10],smonth) |
2 |
=A1.new(#:month,amount,amount-amount[-1]:growth) |
同时,SPL 支持多样性数据源(RDB、NoSQL、Json、CSV、HDFS、RESTful 等),还可以实现跨数据源的混合计算。SPL 是解释执行的,支持热切换,报表修改无需重启服务方便运维。SPL 支持与报表工具嵌入集成,提供了标准 JDBC 接口,报表工具调用 SPL 就像访问数据库一样方便。
此外,SPL 还提供了诸多高性能计算机制,高效算法、并行计算、高性能存储等,让报表数据准备不仅写的简单,跑的也快。与报表工具结合全面解决报表开发问题。
三. 独立报表模块
报表开发全面工具化后,就可以调整应用结构,把报表模块从业务系统中解耦出来。报表模块仅仅共享业务系统的数据源(数据库或别的数据存储介质),而不再和业务系统紧密耦合。报表呈现和数据准备都工具化之后,报表运算可以被集算器解释执行,这样,报表的频繁修改增加也不需要让业务系统都重新启动,大幅降低运维的复杂度。

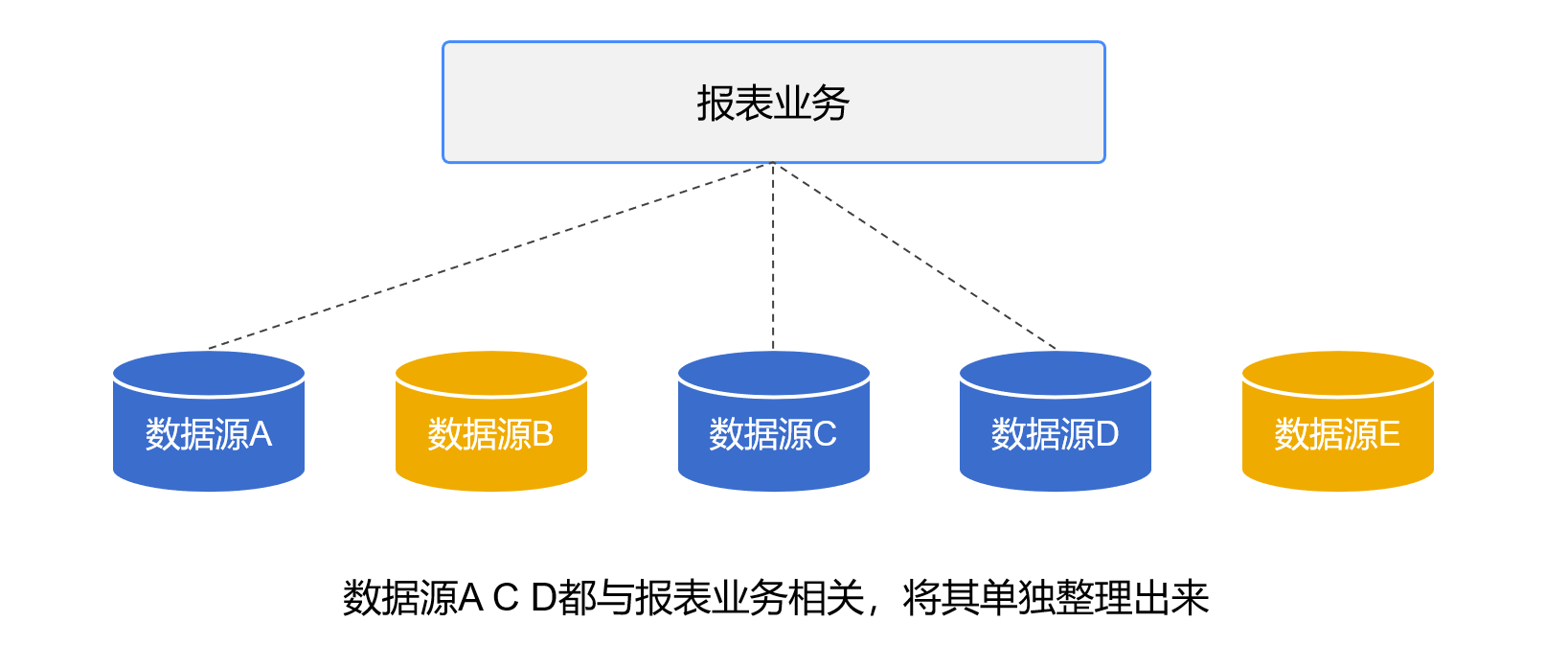
这个过程特别重要的是梳理数据源,把报表模块需要的数据源单独整理出来,以后开发报表只需要和这些数据源打交道。
四. 建设报表团队
在报表模块独立之后,就可以建设专门的报表开发团队了。
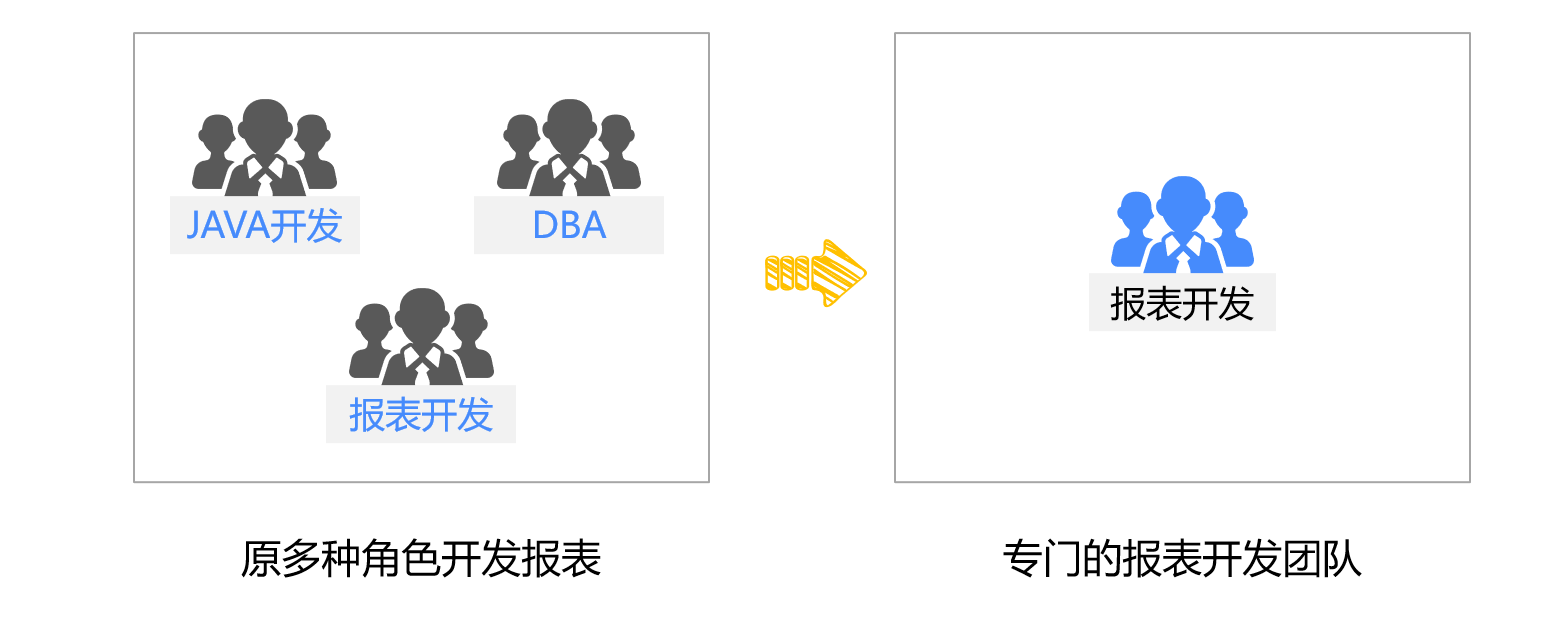
开发报表只需要理解业务逻辑和数据结构,而不必面对业务系统的复杂技术环境。而且开发工作的工具化,也不需要开发人员熟悉复杂 SQL(存储过程)以及 Java 这类高级程序语言。这样,报表开发并不需要太强的技术人员,人工成本可以有效降低,甚至很多情况时还可以把持续报表开发工作移交给客户方的本地运维人员,这样不仅能降低开发商的成本,还能提高对客户的响应速度。

五. 完善沟通机制
最后就是建立有效的沟通机制,减少交流中的误解。一个简单可行的办法就是建立企业内部的报表知识库,技术形式上搞一个论坛即可。
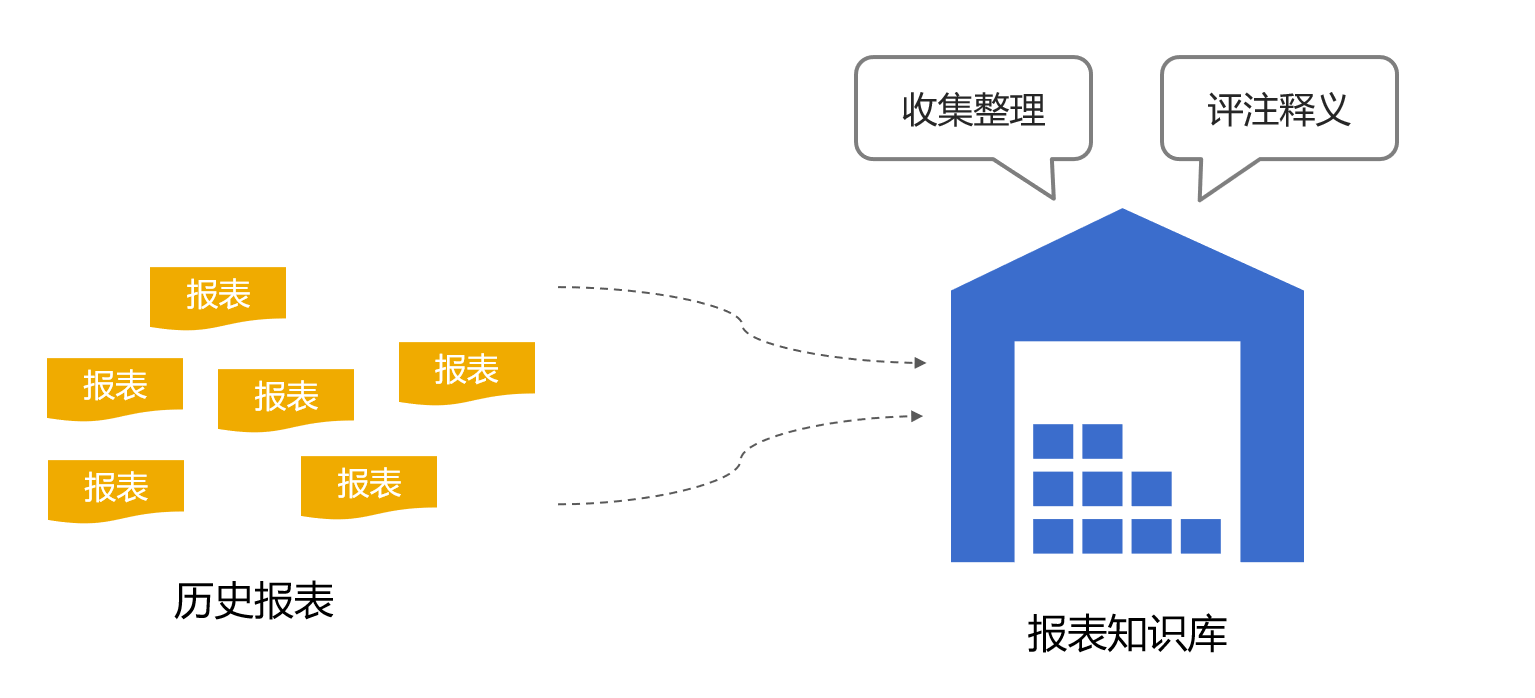
把以前做过的报表收集到论坛上加以评注,并提供搜索功能。当有了新的报表需求时,可以搜索历史库中是否曾经做过类似的报表(出现过相同的业务术语)。
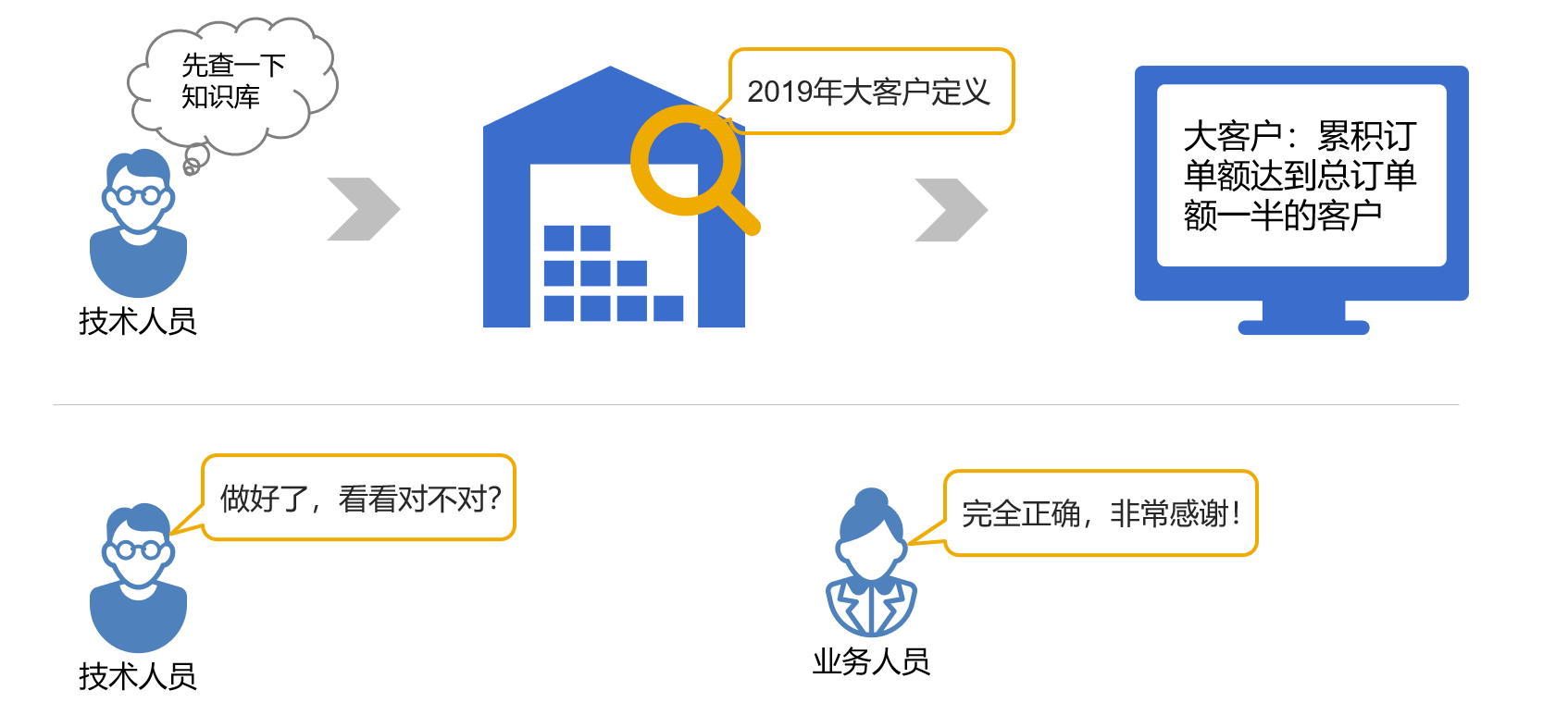
历史报表中保留有相关代码或公式,而这些形式化的信息不会有歧义,这就能帮助新的开发人员正确理解业务术语,甚至许多报表部分还可以被直接复用,在人员变动时也可以最大限度地保证业务知识的继承。
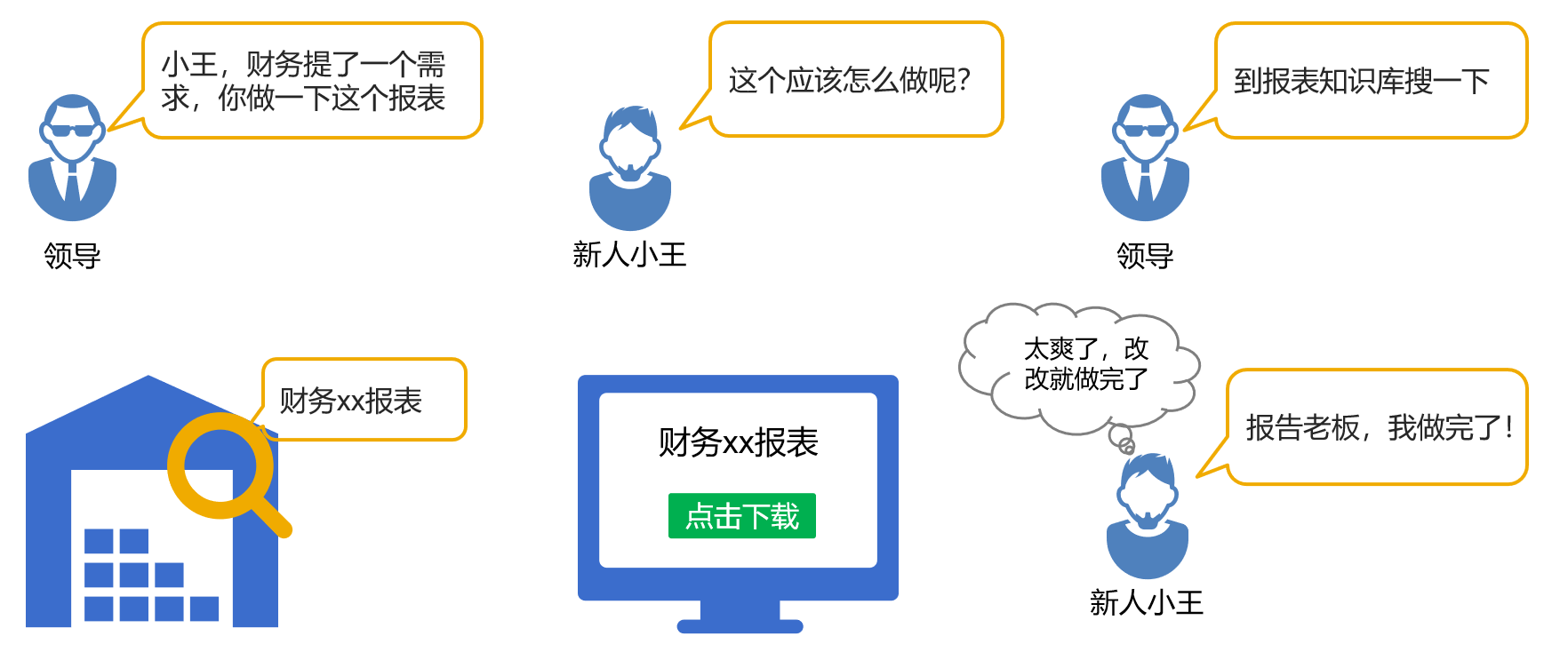
要应对好报表没完没了的问题,是个涉及技术和管理等多方面的综合事务,并不是一朝一夕能完成的。这里面的关键是第二步,如果没有数据准备的工具化,报表模块就无法单独运维,报表开发还要依赖 DBA 和程序员,建设知识库也就无从谈起了。

