


SPL:按指定基准对齐的分组和排序
在分组时经常会要求结果集必须按基准集合的次序出现,这种对齐分组在日常统计中是很常见的。比如按北上广深的顺序,统计某公司在这些城市的总销售额;按指定的部门顺序,查询各部门的平均工资等等。
这种分组我们称为对齐分组。对齐分组可能会有空组,也可能有成员未分配到任何一个组中。
1. 按指定基准集合排序
按基准表中指定字段的顺序,将数据排序,每组保留最多一个匹配成员。适用于我们希望按照指定顺序查看或者使用数据的情况。
【例 1】 根据某年的中国城市 GDP 表,按照北上广深的顺序查询这些一线城市的 GDP 和人口。部分数据如下:
ID |
CITY |
GDP |
POPULATION |
1 |
Shanghai |
32679 |
2418 |
2 |
Beijing |
30320 |
2171 |
3 |
Shenzhen |
24691 |
1253 |
4 |
Guangzhou |
23000 |
1450 |
5 |
Chongqing |
20363 |
3372 |
… |
… |
… |
… |
在 SPL 中函数 A.align() 用于对齐分组,默认每组保留最多一个匹配成员。
SPL脚本如下:
A |
|
1 |
=T("CityGDP.txt") |
2 |
["Beijing","Shanghai","Guangzhou","Shenzhen"] |
3 |
=A1.align(A2,CITY) |
4 |
=A3.new(CITY,GDP,POPULATION) |
A1:查询城市 GDP 表。
A2:定义城市序列。
A3:使用函数 A.align(),将城市 GDP 表按照指定的城市序列排序,每组保留最多一个匹配成员。
A4:创建以城市、GDP、人口为字段的结果表。
其中A4的执行结果如下:
CITY |
GDP |
POPULATION |
Beijing |
30320 |
2171 |
Shanghai |
32679 |
2418 |
Guangzhou |
23000 |
1450 |
Shenzhen |
24691 |
1253 |
2. 每组保留所有匹配成员
按基准表中指定字段的顺序,将数据分组,每组保留所有匹配成员。适用于关心每组的成员信息,或者需要用这些成员记录继续进行统计的场景。
【例 2】 根据相互关联的员工表和部门表,按部门表中的部门顺序统计各部门人数。员工表和部门表的关系如下:
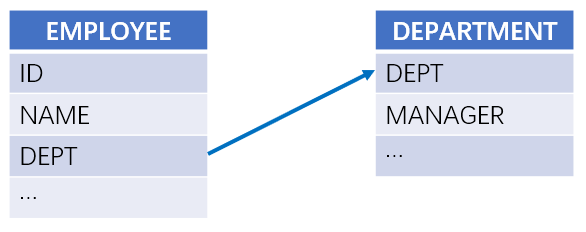
在 SPL 中函数 A.align() 的选项 @a,用于在对齐分组时每组保留所有匹配成员。
SPL脚本如下:
A |
|
1 |
=connect("db") |
2 |
=A1.query("select * from EMPLOYEE") |
3 |
=A1.query("select * from DEPARTMENT") |
4 |
=A2.align@a(A3:DEPT, DEPT) |
5 |
=A3.new(DEPT, A4(#).count():COUNT) |
A1:连接数据库。
A2:查询员工表。
A3:查询部门表。
A4:使用函数 A.align@a() 将员工按部门对齐分组,其中选项 @a 每组返回所有匹配成员。
A5:根据部门表创建结果序列,并通过 A4 对齐分组后的结果计算每组的数量,即每个部门的人数。
其中A5的执行结果如下:
DEPT |
COUNT |
Administration |
4 |
Finance |
24 |
HR |
19 |
… |
… |
对齐分组可能会有空组,也就是没有一个成员被分配到某个分组中。
【例 3】 根据相互关联的课程表和选课表,按课程表顺序查询各课程报名的人数。课程表与选课表的关系如下:
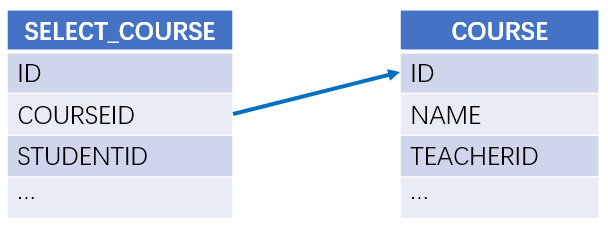
SPL脚本如下:
A |
|
1 |
=connect("db") |
2 |
=A1.query("select * from SELECT_COURSE") |
3 |
=A1.query("select * from COURSE") |
4 |
=A2.align@a(A3:ID,COURSEID) |
5 |
=A3.new(ID, A4(#).len():COUNT) |
A1:连接数据库。
A2:查询选课表。
A3:查询课程表。
A4:使用函数 A.align@a(),将选课表按照课程表的 ID 对齐,每组保留所有匹配成员。
对齐分组后的结果中可能会有空组,也就是有的课程没有学生选择:
成员 |
[] |
[[13,2,7],[15,2,50],…] |
[[7,3,41],[11,3,5],…] |
[[45,4,28],[51,4,18],…] |
[[3,5,52],[4,5,44],…] |
… |
A5:根据课程表创建结果序列,并通过 A4 对齐分组后的结果计算每组的数量,即选择该课程的人数。
其中A5的执行结果如下:
ID |
COUNT |
1 |
0 |
2 |
6 |
3 |
5 |
4 |
4 |
5 |
11 |
… |
… |
3. 不匹配记录放到新组
按基准表中指定字段的顺序,将数据分组,不匹配的记录放到新组。适用于不仅关心匹配的成员信息,还要关心其他不匹配记录的场景。
【例 4】 根据员工表,统计 [California, Texas, New York, Florida] 的平均工资,其他州作为“Other”组进行统计。员工表部分数据如下:
ID |
NAME |
STATE |
DEPT |
SALARY |
1 |
Rebecca |
California |
R&D |
7000 |
2 |
Ashley |
New York |
Finance |
11000 |
3 |
Rachel |
New Mexico |
Sales |
9000 |
4 |
Emily |
Texas |
HR |
7000 |
5 |
Ashley |
Texas |
R&D |
16000 |
… |
… |
… |
… |
… |
在 SPL 中函数 A.align() 的选项 @n,用于在对齐分组时将不匹配记录放到新组。
SPL脚本如下:
A |
|
1 |
=T("Employee.csv") |
2 |
[California,Texas,New York,Florida] |
3 |
=A1.align@an(A2,STATE) |
4 |
=A3.new(if (#>A2.len(),"Other",STATE):STATE,~.avg(SALARY):AvgSalary) |
A1:查询员工表。
A2:创建地区序列。
A3:使用函数 A.align@an() 将员工表按地区对位分组,选项 @a 每组返回所有匹配成员,选项 @n 不匹配成员存放到新组。
A4:统计每组的平均工资,将不匹配的分组(最后一组)命名为“Other”。
其中A4的执行结果如下:
STATE |
AvgSalary |
California |
7700.0 |
Texas |
7592.59 |
New York |
7677.77 |
Florida |
7145.16 |
Other |
7308.1 |

