


有边界的线性拟合算法
有边界的线性拟合算法
已知自变量矩阵X和因变量矩阵Y,两者存在线性关系,但系数被限制在一个范围内,这个范围称为边界,试求出该边界范围内的最佳系数矩阵。
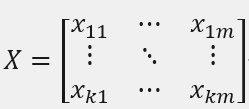
其中X是k*m矩阵,k是样本数,m是自变量数,xij是第i个样本的第j个自变量。
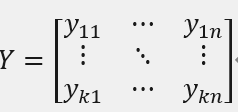
其中Y是k*n矩阵,k是样本数,n是因变量数,yij是第i个样本的第j个因变量。
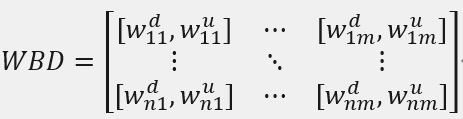
其中WBD的是n*m矩阵。wdij是第i个因变量第j个自变量的下边界,wuij是第i个因变量对应的第j个自变量的上边界, [wdij, wuij]是i个因变量对应的第j个自变量的取值范围。每一行是一个因变量所有的自变量边界。
应用背景
在生产环境中,进料转换成出料的转换率称为收率,收率的取值范围在[0,1]之间,也就是转换率不可以小于0,也不可以大于1。进料矩阵就是自变量X,出料矩阵就是因变量Y,收率的取值范围就是边界矩阵BD。
算法目标:
计算边界范围内的最佳拟合系数。
算法原理:
计算拟合系数通常会使用最小二乘法(LS)来实现,但简单执行LS算法,可能会导致拟合系数超出边界的情况,比如在生产拟合时会出现收率大于1或小于0的情况,这就完全没有意义了。
用最小二乘法求拟合系数的过程本质上是二次函数的极值问题,可以证明,在有界范围,二次函数的极值可能在边界上,也可能在偏导数为0的位置,穷举所有X的系数边界和偏导数为0的所有可能,每个自变量对应的系数都有3种取值,分别是上界,下界,偏导数为0,m个自变量就会有3m种可能,找到使rmse最小的一套系数即为边界范围内的最佳系数。在m不大的时候,这个算法具有实际可行性。
算法过程:
设求得的系数矩阵W如下:
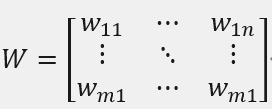
其中Wij是第i行,第j列的元素。
1. 计算每列因变量的系数
所有可能的系数组合共有3m种,记为s。
s=3m
用Yj表示Y的第j列元素,用Xh表示X的第h列元素。
(1) 若没有自变量取到边界,则所有自变量的系数都是偏导数为0时的系数;
Wj(r)=linefit(X,Yj),r∈[1,s]
其中linefit()函数是最小二乘法拟合得到的系数,Wj (r)是Yj对应的第r个系数矩阵。
(2) 若某些自变量的系数取到边界,其他列的系数需要偏导数为0求得;
假设Xa,Xb,…,Xk这些自变量的系数取到了边界,则这些自变量的系数已经知道,为Waj,Wbj,…,Wkj。
未取到边界的自变量记为X’,对应的因变量Yj’
Yj’=Yj-(Xa*Waj+ Xb* Wbj+…+Xk* Wkj)
系数矩阵记为Wj’
Wj’=linefit(X’, Yj’)
将Waj,Wbj,…,Wkj按序合并后即得到相应的Wj(r)。
(3) 若所有自变量的系数都取到边界,则这些边界就是一组系数。
经过(1)(2)(3)就得到了s=3m组系数,即Wj (1), Wj (2),…, Wj (s)。
(4) 筛选所有系数都在边界内的系数Wj (r’)
Wj (r’)= Wj (r), wdji≤Wj (r)i≤wuji
其中Wj (r)i是Wj (r)的第i个的元素。
(5) 计算每组系数关于Yj的rmse(r’)。
Yj’=X* Wj (r’),r∈[1,s]
其中Yj’是X与Wj (r’)的预测结果。
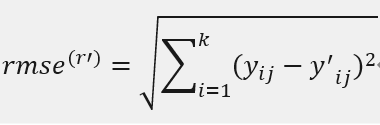
其中yij是Yj的第i个元素是,y’ij是Yj’的第i个元素。
(6) 使rmse(r’)最小的Wj (r’)即为最佳系数矩阵Wj
所有的rmse(r’)组成的序列称为rmse序列,记为RMSE。
Wj=Wj(r’),rmse(r’)=min(RMSE)
2. 合并所有因变量的最佳矩阵就得到最佳矩阵W。
写出代码:
A |
B |
C |
D |
E |
||
1 |
=X |
/参数:X 矩阵 (k*m) |
||||
2 |
=Y |
/参数:Y 矩阵 (k*n) |
||||
3 |
=BD |
/参数:边界矩阵 BD(n*m) |
||||
4 |
=func(A6,A1,A2,A3) |
/计算结果 |
||||
5 |
/有边界的线性拟合,参数:X,Y, 边界 |
|||||
6 |
func |
|||||
7 |
[0,1,2] |
0:偏导数 =0,1: 下边界,2: 上边界 |
||||
8 |
=(A6.~.len()-1).iterate(func(A52,B7,~~),B7) |
/边界的取值标记 |
||||
9 |
=B6.~.len().((idx=~,B6.([~(idx)]))) |
/Y |
||||
10 |
=B9.(func(A14,A6,~,C6(#),B8)) |
/Yj对应 Wj |
||||
11 |
=B10.(~.conj()) |
/整理 W |
||||
12 |
=transpose(B11) |
/转置 W |
||||
13 |
/某个 Yj 拟合 W,参数:X,Yi,某个 Yj 对应的 Wj 边界,边界的取值标记 |
|||||
14 |
func |
|||||
15 |
=D14.(func(A22,A14,B14,C14,~)) |
/3^m种取值标记 |
||||
16 |
=B15.(func(A43,A14,B14,~)) |
/RMSE |
||||
17 |
=B15.pselect@a(func(A47,~,C14)) |
/边界内的 W |
||||
18 |
=B16(B17) |
/边界内的 RMSE |
||||
19 |
=B18.pmin() |
/最小的 RMSE 索引 |
||||
20 |
=B15(B17(B19)) |
/RMSE最小的 W |
||||
21 |
/3^m种取值中的一种拟合结果,参数:X,Y, 边界,1 种取值类型 |
|||||
22 |
func |
|||||
23 |
=D22.align@ap([true,false],~!=0) |
|||||
24 |
=B23(1) |
/第几个自变量取边界 |
||||
25 |
=D22(B24) |
/上界,下届,偏导 =0? |
||||
26 |
=B23(2) |
/第几个自变量不取边界 |
||||
27 |
if B24.len()>0 |
=A22.(~(B24)) |
/取边界的 Xh |
|||
28 |
=C22(B24) |
/Xh对应的边界 |
||||
29 |
=C28.([~(B25(#))]) |
/xh边界的值 |
||||
30 |
=mul(C27,C29) |
/xh*边界 |
||||
31 |
=B22.(~--C30(#)) |
/Y-Xh*边界 |
||||
32 |
=A22.(~(B26)) |
/不取边界的 X' |
||||
33 |
if B26.len()==0 |
=D34=null |
/如果都是边界,取边界 |
|||
34 |
else |
=w=linefit(C32,C31),if(ifnumber(w),[[w]],w) |
/拟合不取边界的 X' 和 Y-Xh* 边界 |
|||
35 |
=C29|D34 |
/合并边界与拟合的 W |
||||
36 |
=B23.conj() |
/Xh的索引 |
||||
37 |
=C36.psort() |
/Xh的原序 |
||||
38 |
=C35(C37) |
/对应 Xh 的 Wj |
||||
39 |
return C38 |
|||||
40 |
else |
=w=linefit(A22,B22),if(ifnumber(w),[[w]],w) |
/如果都不取边界,直接拟合 |
|||
41 |
return C40 |
|||||
42 |
/计算某个 wj(r) 的 rmse(r), 参数:X,Yj,Wj(r) |
|||||
43 |
func |
|||||
44 |
=mul(A43,C43) |
/X*W(r) |
||||
45 |
=sqrt(mse(B43,B44)) |
/rmse(r) |
||||
46 |
/筛选条件,参数:Wj(r),边界 |
|||||
47 |
func |
|||||
48 |
=A47.conj() |
/合并系数 |
||||
49 |
=B48.(~>=B47(#)(1)&&~<=B47(#)(2)) |
/筛选 |
||||
50 |
=B49==B49.(true) |
|||||
51 |
/3^m种取值标记,参数:标记序列 |
|||||
52 |
func |
|||||
53 |
=A52.conj((idx=#,B52.(A52(idx)|~))) |
/3^m种取值标记 |
||||
输入参数说明:
1. A1中的X是输入自变量矩阵,形状是k*m。
2. A2中的Y是输入自变量矩阵,形状是k*n。
3. A3中的BD是输入边界矩阵矩阵,形状是n*m(这里要注意,每一行是1个Y的所有X的边界)。
应用举例:
自变量矩阵X:
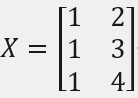
因变量矩阵Y:
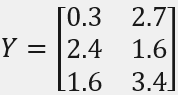
边界矩阵BD:
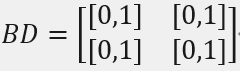
1. 先来看下直接用最小二乘法的拟合结果
系数矩阵W:

系数矩阵W的rmse:
rmse1= 0.684
rmse2= 0.684
注意:约束条件是所有收率都不小于0且不大于1,这种方式肯定是无法满足需求的。
2. 再来看有边界的线性拟合算法拟合结果
最佳系数矩阵W:

最佳系数矩阵W的rmse:
rmse1= 0.697
rmse2= 0.697
rmse1是第1列Y的rmse,rmse2是第2列Y的rmse。
说明:虽然简单最小二乘法的拟合结果更好,但因为有边界约束条件的限制,还是要选择有边界的线性拟合算法。

