


SQL 提速:TopN 和组内 TopN
【摘要】
从原理上分析 SQL 语句慢的原因,用代码示例给出提速办法。点击了解SQL 提速:TopN 和组内 TopN
问题描述
TopN 是指从数据中查找前 N 名 / 后 N 名。以 Oracle 为例,SQL 是这样的:
select * from (select x from T order by x desc) where rownum<=N
从 SQL 语句上看,是将全部数据按照 x 排序后,取出前 N 条。测试表明,Oracle 可以自动优化这种全集 TopN,没有大排序,性能很好。但是,对于分组后计算组内 TopN 这种更复杂的情况,数据库就很难优化了。
Oracle 组内 TopN 的写法是:
select * from
(select y,x,
row_number()over (partition by y order by x desc) rn
from T)
where rn<=N
SQL 无法直接写出分组后取 TopN 的运算,只能借助窗口函数计算组内序号,再过滤出结果。对于没有窗口函数的数据库来说,组内 TopN 的 SQL 甚至很难写出来。
实测发现,Oracle 计算组内 TopN 比全集 TopN 慢了 n 倍,说明很可能做了排序。情况复杂化之后,Oracle 的优化引擎不起作用了。
排序求 TopN 方法之所以这么慢,是因为算法复杂度很高:M 个成员排序的复杂度是 Mlog2M,需要对数据遍历 log2M 次,计算非常耗时。当数据量较大时,内存无法装下全部数据,还要缓存到外存中,计算速度更会急剧下降。而且,大排序也不容易并行。
提速方案
为了让 TopN 避免全排序,我们可以保持一个大小为 N 的小集合。遍历数据时,将已经计算过的数据前 N 名保存在这个小集合中,取到的新数据如果比当前的第 N 名还大,则插入进去并丢掉现在的第 N 名,如果比当前的第 N 名要小,则不做动作。
这样做,只需要对数据遍历一次。而且,一般来说 N 都不会太大,小集合可以在内存中放得下,即使总数据量很大,也不会发生内外存的数据交换。实际上,对于总数据量不大,全内存计算 TopN 的情况,由于新的算法不必排序,性能也会提高。
在 M 个成员中取出前 N 名,新算法的复杂度是 Mlog2N,在 N<<M 时,比排序方式的复杂度低了很多。分段并行也比较容易,只要每个段都算出前 N 名,再对这些前 N 名的并集计算最终的前 N 名即可,不会出现硬盘并发写的情况。
这种算法的本质是将 TopN 看做聚合运算。通常,我们理解的聚合运算是将一个集合计算成一个单值,比如求和、计数、最大、最小。现在,我们将 TopN 这种返回一个小结果集的情况也看成是聚合,就可以用聚合运算的思路来解决 TopN 问题。这样,分组求组内 TopN 问题,就和分组求和、计数、最大、最小值一样了,很容易实现,可以避免排序计算。
代码示例
一、全集 TopN
A |
|
1 |
=file("T.ctx").open() |
2 |
=A1.cursor@m(x;;4).total(top(-5,x), top(5,x)) |
A1:打开组表。
A2:建立 4 线程的多路游标。total()是对数据全集做聚合,top(-5,x) 计算出 x 最大的前 5 名,top(5,x) 是 x 最小的前 5 名。
A2 执行结果如下:
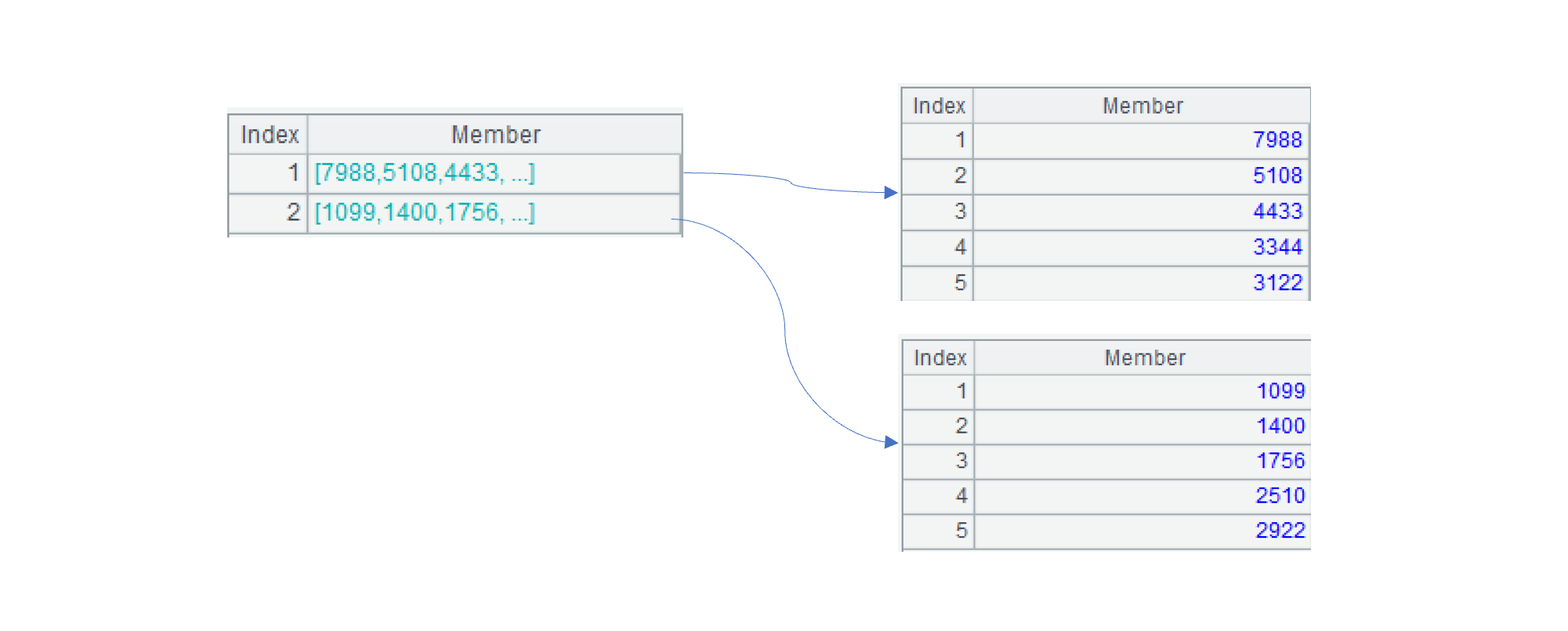
从上图可以看到,最大前 5 名和最小前 5 名的计算结果各是一个集合。
二、组内 TopN
A |
|
1 |
=file("T.ctx").open() |
2 |
=A1.cursor@m(x,y).groups(y;top(-3,x), top(3,x)) |
A2:groups(y;top(-3,x), top(3,x) 是按照 y 分组,计算组内 x 最大、最小的前 3 名。游标参数中省略了并行数,计算时自动按系统配置中的最大并行数生成多路游标。可以用 top(-3,x):top3 的方式来重命名结果集合中的字段。
A2 执行结果如下:
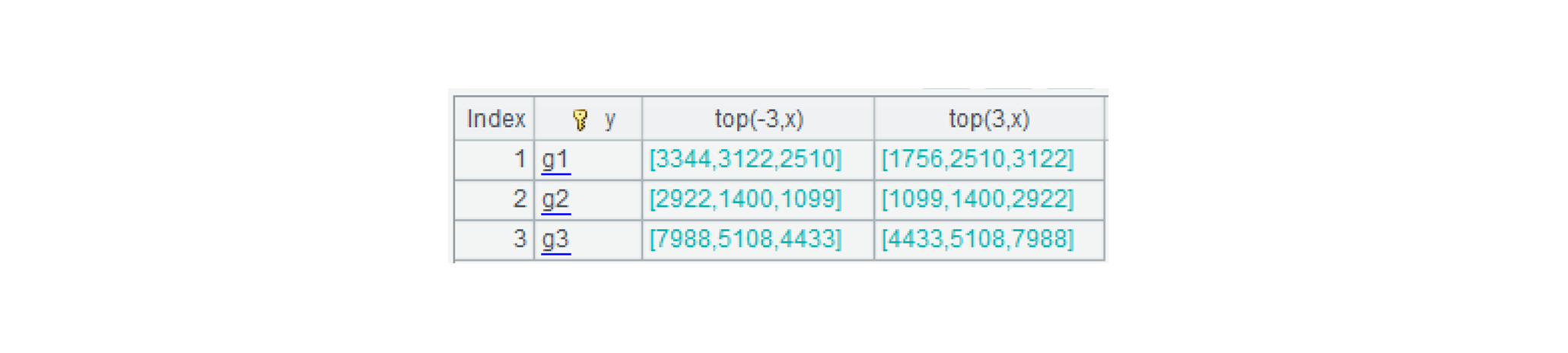
可以看到,结果集除了分组字段以外,第二个字段是最大前 3 名的集合,第三个字段是最小前 3 名的集合。

