


SQL 提速:WHERE 中的 IN
【摘要】
从原理上分析 SQL 语句慢的原因,用代码示例给出提速办法。点击了解SQL 提速:WHERE 中的 IN
问题描述
WHERE 子句中出现 IN 比较常见,比如:按照客户年龄段枚举值过滤,还有地区、订单类型等等。
IN 条件一般是 F IN (f1,…,fn)的形式,即字段 F 取值包含于值集合 {fi,..} 时为真。
IN 的计算比较慢,原因如下:
1、 要判断字段 F 是否包含在值集合中,如果采用顺序查找,需用 F 与值集合中的成员做 1 到 n 次的比较计算。即使在值集合有序的情况下用二分法查找,也要比较数次。IN 计算是一种效率很差的集合运算,且值集合越大,性能越差。
2、 IN 涉及字段常常是字符串类型,相比整数值来说,字符串存储占用空间更大,且比较计算也更慢。大数据量计算时,数据通常都存储在外存中,IN 计算从外存读取字符串以及字符串比较都慢一些,全表遍历时速度慢的就会非常明显。
提速方案
首先,找出 IN 字段的取值范围。
通常,IN 字段的可能取值是不多的有限种,有时还会有个代码表来存储所有可能的取值(这里称为维表)。相应的,我们将待查询表(也就是 IN 字段所在的表)称为事实表。
对于有对应维表的字段,取值范围已经确定了,不需要特殊处理。对于没有对应维表的字段,需要预先遍历事实表生成取值范围(我们这里也称为这个字段的维表)。
无论是已有的维表还是生成的,都要按照值集合有序存放。这样做,在后续计算中就可以用二分法定位(后面会讲到),提高计算速度。
第二,将事实表字段值转换为整数。
转换的方法是对数据做遍历,在对应维表中找到字段值,并将字段值替换为对应条目在维表中的位置序号,另存成新的事实表。一般来说维表都不会太大,序号通常会是小于 65536 的小整数。
第三,将 IN 的值集合 {fi,..} 转换成布尔维序列。
生成一个与维表等长的布尔序列。这个序列中第 i 个成员是不是为 true,由维表中第 i 个成员是否在值集合 {fi,..} 中来决定。如果在值集合中那么就是 true,否则就是 false。这样生成的序列我们称之为布尔维序列。
第四,实现 IN 查询。
查询时依然要遍历事实表,只是不再做 IN 集合的比较运算。我们已经预先将字段值转换为维表对应序号了,查询时用序号去取布尔维序列中的成员,如果取出来是非空,就表示字段值符合 IN 过滤条件,否则就不符合。
这种方法本质上是将“集合值比较”转换为“序号引用”,有效的减少了计算时间。遍历事实表的时候,无论 IN 的值集合有多大,每个字段值都只要按照序号引用布尔维序列中的一个成员就可以完成过滤计算。也就是说,计算时间和 IN 枚举值的多少无关,不会随着 IN 枚举值的增加而增加。按序号取值的运算复杂度远远小于 IN 集合的比较运算,可以大幅提升查询性能。
示例代码
假设事实表为 T,SQL 语句可以表示为:
Select … from T where … F1 in (…) … F2 in (…) … F3 in (…) …
表 T 结构和数据示例如下,其中 F1、F2 有对应的维表,F3 是一般的字符串字段,没有对应维表:
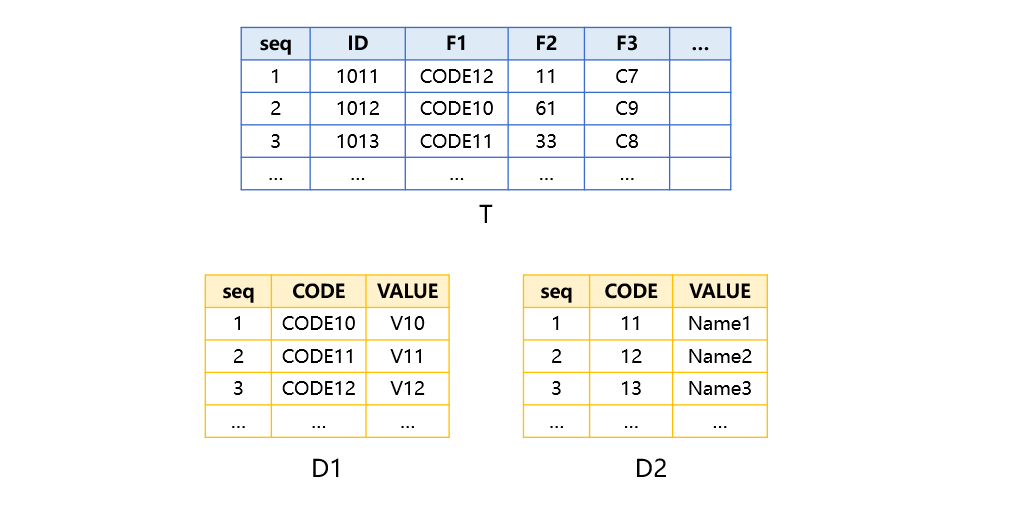
第一步,找出 IN 字段的取值范围。
F1、F2 有对应维表,F3 要通过下面的代码创建维表 D3:
A |
|
1 |
=file("T-original.ctx").open().cursor('F3') |
2 |
=A1.groups('F3') |
3 |
=A2.new('F3':CODE) |
4 |
=file("D3.btx").export@b(A3) |
A1:打开转换前的原始组表 T-original.ctx,只取 F3 字段。
A2:对 F3 做分组,F3 取值一般不会太多,所以采用 groups。结果对 F3 有序。
组表的字段名 F3 和单元格名重复了,所以要加上单引号以示区别。如果字段名和变量名重复,也要加上单引号。
A3:F3 字段名改为 CODE。
A4:结果输出到 D3.btx。
注意:F1、F2 对应维表 D1、D2 也要对 CODE 有序,如果原始数据无序的话,要用排序函数预处理。
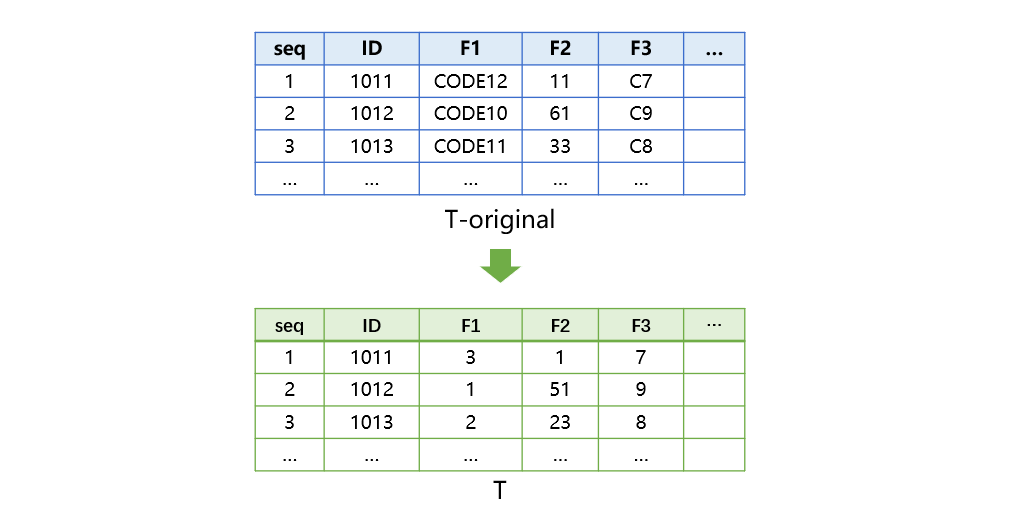
第二步,将事实表字段值转换为整数。
表 T 中的 F1、F2、F3 字段值需要转换成对应维表的序号,代码如下:
A |
B |
|
1 |
=file("T-original.ctx") |
=file("T.ctx") |
2 |
["D1","D2","D3"] |
=A2.(file(~/".btx").import@ib(CODE)) |
3 |
=A1.open().cursor().run('F1'=B2(1).pos@b('F1'),'F2'=B2(2).pos@b('F2'),'F3'=B2(3).pos@b('F3')) |
|
4 |
=A1.reset@n(B1) |
=B1.open().append@i(A3) |
A1、B1:定义原始组表 T-original.ctx 文件、新组表文件 T.ctx。
A2:定义需要转换的三个维表名称序列。
B2:用 A2 循环打开维表文件,读入数据,取 CODE 字段序列。
A3:用 A1 定义游标,取全部字段,并定义新游标,将 F1、F2、F3 字段值分别转换成在维表的位置序号。
A4:用原始组表新建同构的空组表 T.ctx;B4:打开 T.ctx 将 A3 的结果输出到新组表中。
前面我们将维表数据有序存放,在这里可以体现性能优势:A3 中,pos@b 利用维表数据有序的特征,采用二分法查找提高性能。
转换之后的 T 表如下图:
第三步,用布尔维序列实现 IN 查询。
以 F1 为例,先定义参数 arg_F1,传入 F1 的枚举值过滤条件。例如,arg_F1 参数值为 ["CODE11","CODE12","CODE13","CODE15"]。
SPL 代码:
A |
|
1 |
=file("T.ctx").open() |
2 |
=file("D1.btx").import@ib(CODE) |
3 |
=A2.(arg_F1.contain@b(~)) |
4 |
=A1.cursor(…;A3('F1')) |
5 |
… |
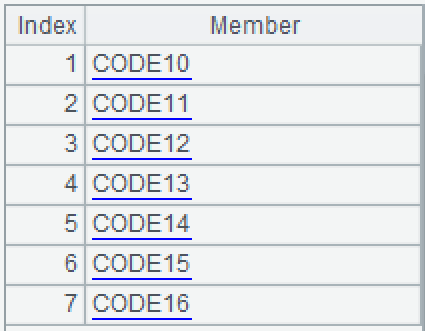
A1:打开 T.ctx 组表。
A2:读入 D1.btx,取 CODE 字段的序列。结果如下图:
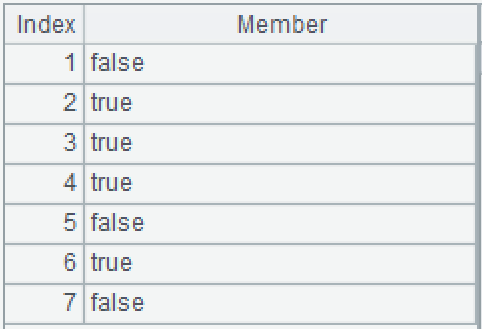
A3:循环计算 A2,将参数 arg_F1 中能找到的 CODE 对应位置设置为 true,其他设置为 false。参数 arg_F1 是有序的,所以可以用 contain@b 二分法查找。结果如下图:
A4:采用布尔维序列的方式,定义游标前过滤。过滤方法如下图:
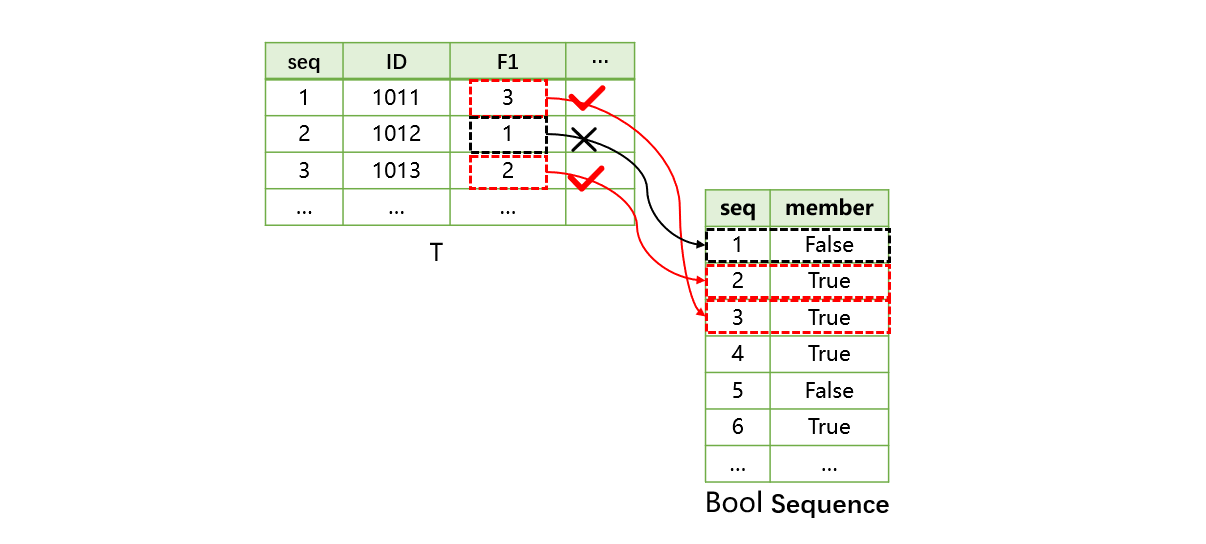
第 1 条记录,用 F1 字段的值 3,找到布尔维序列中第 3 个成员,值为 true,因此第 1 条记录满足条件。如果值为 false,则不满足条件。其他记录依此类推。
A5:继续做其他计算。
注意,arg_F1 传入的值集合是有序的,可以用 contain@b 来查找定位计算出布尔维序列。如果无序,则需要先做一次 sort,这样,后面多次(维表成员数)的查找定位都可以用二分法,带来的性能提升会远超过一次 sort 的成本。不过,相对于再后面的遍历来讲,参数的处理成本总体不高,不做 sort 也不用 contain@b 通常也能接受。
如果维表较大,在追求极致性能时,还可以用反过来的方法来计算布尔维序列:
A |
|
1 |
=file("T.ctx").open() |
2 |
=file("D1.btx").import@ib(CODE) |
3 |
=A2.(false) |
4 |
>arg_F1.(A3(A2.pos@b(~))=true) |
5 |
=A1.cursor(…;A3('F1')) |
6 |
… |
A3:定义 A2 等长的序列,成员都是 false。
A4:对 arg_F1 循环计算,在 A2 中查找当前 arg_F1 的成员的位置序号,把 A3 中这个位置序号的成员设置成 true,否则就不变。
这种写法结果和前面相同,但是准备布尔维序列的计算次数不同。
假设 arg_F1 的长度是 n,D1 的长度是 m,那么前面算法 A3 中的平均比较次数是 m*log2n。后面算法中 A4 的平均比较次数是 n*log2m,在 m≫n 时,后者要比前者性能好很多。


英文版