


Java 程序员如何轻松搞定文本计算?
解决办法:esProc - Java 专业计算包
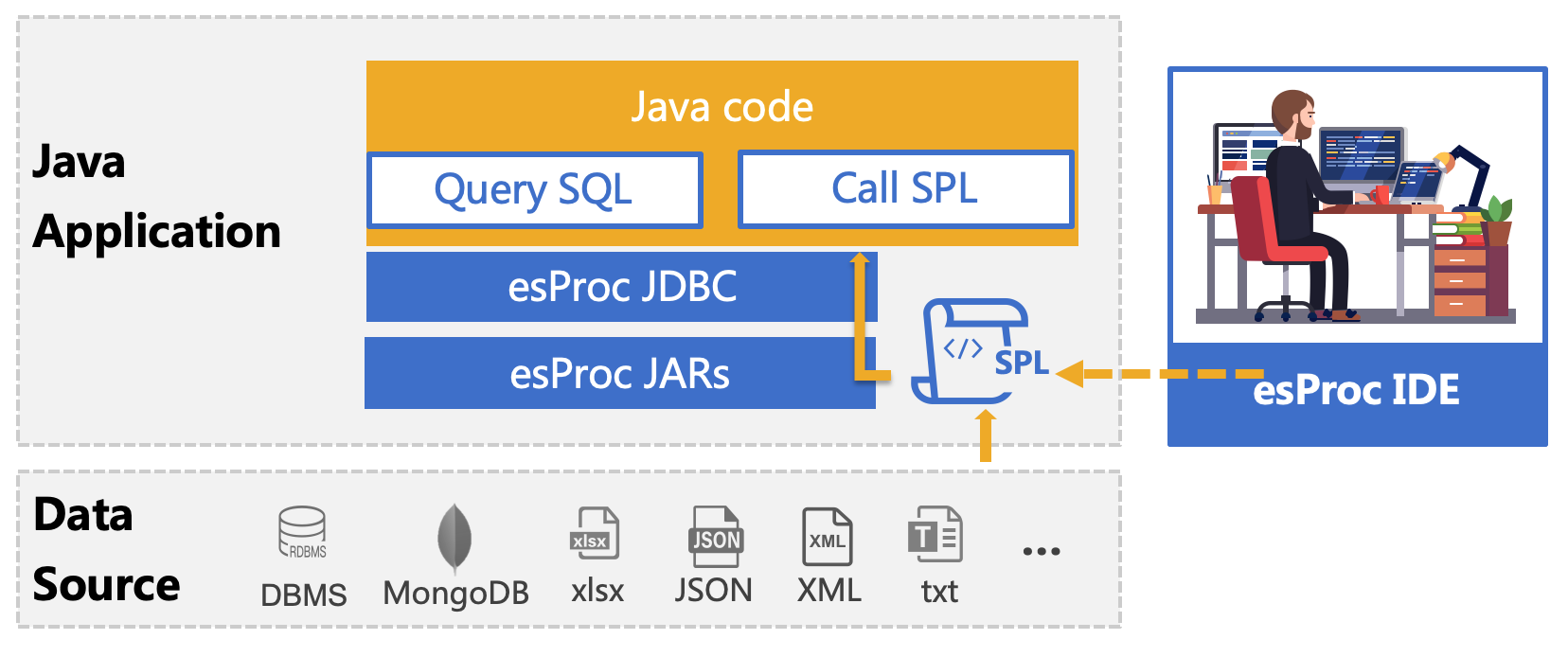
esProc 是专门用于 Java 计算的类库,旨在简化 Java 代码,提供不依赖数据库的计算能力。 SPL 是基于 esProc 计算包的脚本语言,和 Java 程序一起部署,用法和 Java 程序中调用存储过程相同,通过 JDBC 接口调用,返回 ResultSet 对象。
常规文本查询
Java 只提供比较基础的底层函数,缺乏专业的结构化数据计算函数,比如数据集的过滤、排序、分组统计、连接等,都需要程序员自己去编写,用 SPL 读取则非常简单。
比如:找出英语平均分低于70分的班级。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.groups(CLASS;avg(English):avg_En) |
3 |
=A2.select(avg_En<70) |
这段代码可在esProc的IDE中调试/执行,然后将其存为脚本文件(比如condition.dfx),通过JDBC接口在JAVA中调用,具体代码如下:
package Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class test1 {
public static void main(String[] args)throws Exception {
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call condition.dfx");
printResult(result);
if(connection != null) connection.close();
}
…
}
上面的用法类似存储过程,其实 SPL 也支持类似 SQL 的用法,即无须脚本文件,直接将 SPL 嵌入 JAVA,代码如下:
…
ResultSet result = statement.executeQuery("
=file(\"D:\\sOrder.csv\").groups(CLASS;avg(English):avg_En).select(avg_En<70)");
…
用 SPL 实现多文本关联计算:
比如:销售订单信息和产品信息分别存储在两个文本文件中,计算各订单的销售额。两个文件数据结构如下图:
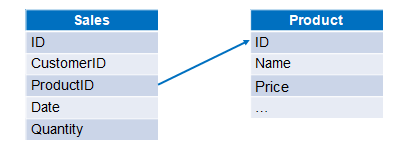
A |
|
1 |
=T(“e:/orders/sales.csv”) |
2 |
=T(“e:/orders/product.csv”).keys(ID) |
3 |
=A1.join(ProductID,A2,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
一个目录里有很多相同结构的文本,用 SPL 合并后查询汇总同样十分简单:
| A | |
| 1 | =directory@p("./"+user+"/*.csv") |
| 2 | =A1.conj(file(~).import@tc()) |
| 3 | =A2.groups('Customer ID':CID,year('Purchase Date'):Year; 'Customer Name':Customer,sum('Sale Amount'):Total,round(avg('Sale Amount'),1):Average) |
| 4 | =A3.select(Year==when).new(Customer,Total,Average) |
SPL 中提供了完善的用 SQL 查询文件数据的方法:
比如:州信息,部门信息和员工信息分别存储在3个文本文件中,查询经理在California州的New York州员工。
A |
|
1 |
$select e.NAME as ENAME from E:/txt/EMPLOYEE.txt as e join E:/txt/DEPARTMENT.txt as d on e.DEPT=d.NAME join E:/txt/EMPLOYEE.txt as emp on d.MANAGER=emp.EID where e.STATE='New York' and emp.STATE='California' |
大文本计算
如果数据量较大,SPL 还有游标读取的方式,可以在游标上绑定计算,比如按 Employees 表的 Dept 字段分组,对 Orders 表的 Amount 字段汇总,在游标上实现了排序、关联和分组计算,可以利用小内存完成大数据计算。
A |
|
1 |
=file("E:/txt/Employees.txt").cursor@t().sortx(EId) |
2 |
=file("E:/txt/Orders.txt").cursor@t().sortx(SellerId) |
3 |
=joinx(A2:O,SellerId; A1:E,EId) |
4 |
=A3.groups(E.Dept;sum(O.Amount)) |
大文本计算经常需要加入并行计算提高计算效率,每个线程各自用大文件计算的方式处理一段数据,最后将各线程处理的结果进行汇总。
比如:在大数据用户登录记录文件 user_info_reg.csv 中,统计各省用户的登录总次数,SPL 脚本如下:
| A | |
|---|---|
| 1 | =file(“E:/txt/user_info_reg.csv”).cursor@tcm(;4) |
| 2 | =A1.groups(id_province;count(~):cnt) |
在 SPL 中使用并行提速非常容易,@m 表示并行计算,参数 4 表示 4 路并行,与单线程代码相比,仅仅多一个游标选项与参数,让用户使用并行非常方便。
不规则文本处理
如下数据格式,要求每行从开始都有的字段各分一列,其他不够有多少项归为一列。
col1,col2,clo3,col4
word1,date1,date2,port1,port2,....some amount of port
word2,date3,date4,
....
SPL 处理如下:
| A | |
|---|---|
| 1 | =file(“file.txt”).import@st() |
| 2 | =A1.(#1.split@c()).new(~(1):col1,~(2):col2,~(3):col3,~.to(4,).concat@c():col4) |
导入文本,按逗号分隔,第 1-3 项各分一列,从第 4 项开始分为一列。
又比如,文本 T2.txt 中都是形如下行的串,需要提取含有字符 US 前的州名(LA)和 COOP: 后的数字。
COOP:166657,'New Iberia Airport Acadiana Regional LA US',200001,177,553
COOP:177562,'Bobo Dioulasso Airport BF',200001,322,682
COOP:179534,'La Tapoa Airport NE',200002,408,514
COOP:196410,'Caribou Municipal Airport ME US',200003,436,658
……
| A | |
|---|---|
| 1 | =file(“T2.txt”).import@c() |
| 2 | =A1.select(pos(_2, “US”)!=null) |
| 3 | =A2.derive(mid(_2, pos(_2,"US")-2, 2):State) |
| 4 | =A3.derive(right(_1, pos(_1,“:”)+1):ID) |
导入文本,过滤第二列,字符串必须含有”US”; 找到” US”的位置,左挪 2 个位置,向右提取 2 个字符; 找到”:”的位置,向右提取到末尾,提取结果如下:

集算器也提供了对正则表达式,但仍建议用常规方法实现,集算器 IDE 支持单步、断点等高级调试模式,应对复杂的拆解需求非常便利。


英文版