


与 Apache POI 不同,动态读写 Excel 的轻量级 Java 库是什么?
解决办法:esProc - Java 专业计算包
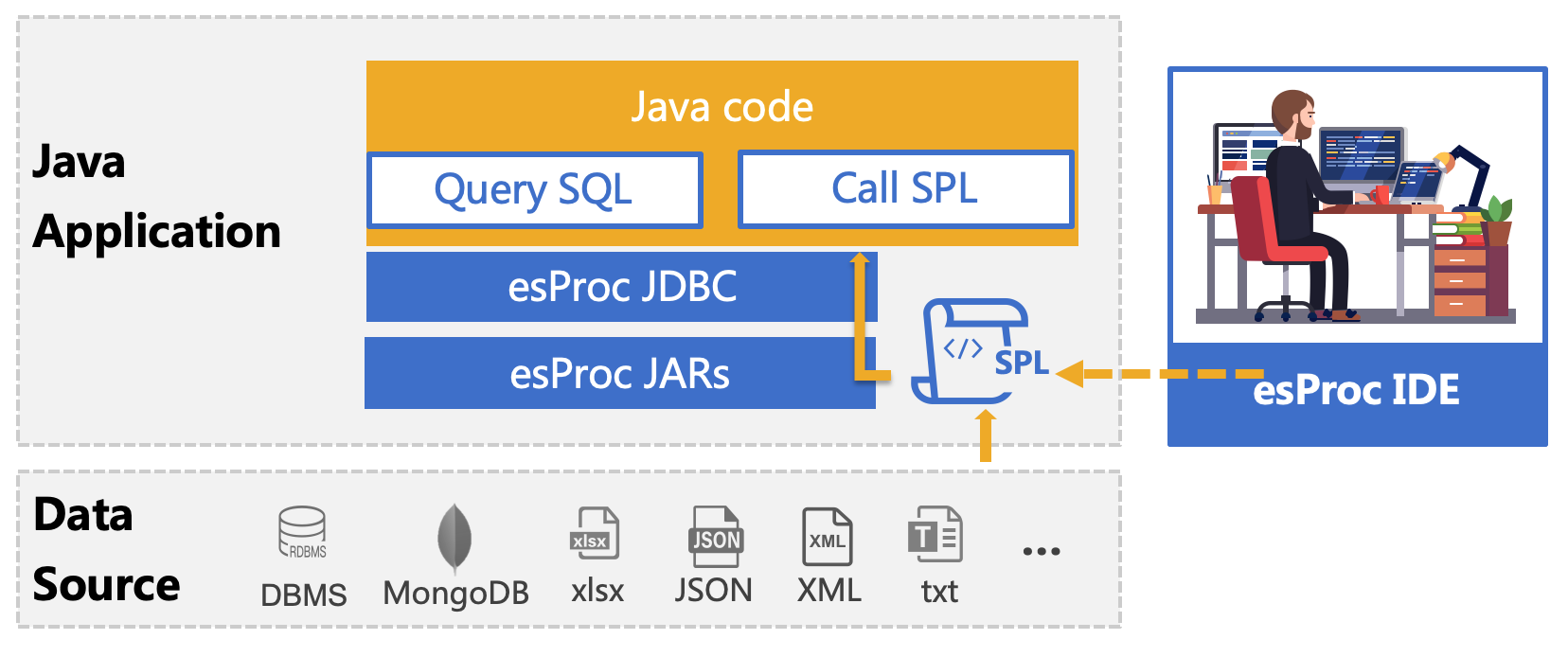
esProc 是专门用于基于 Java 计算的类库,旨在简化 Java 代码。 SPL 是集算器所基于的脚本语言,用法类似于在 Java 程序中调用存储过程,只不过 SPL 独立存储于库外,和 Java 程序一起部署,通过 JDBC 接口传递给 Java 程序执行,实现结构化计算。SPL 非常轻巧,语法简单,类似执行 SQL 的方式计算 Excel 数据,返回 ResultSet 对象。
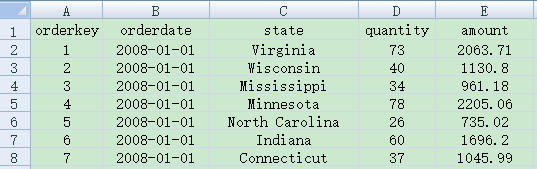
先看一个很简单的文件:第一行是列标题,第二行开始直到最后一行都是数据行。文件内容如下图:
用Apache为Java提供的开源包poi读写Excel文件,写出来的程序是这样:
DataSet ds = null; //此类用来保存从Excel中读取的数据,需要自己编写
HSSFWorkbook wb = new HSSFWorkbook( new FileInputStream( "simple.xls" ) );
HSSFSheet sheet = wb.getSheetAt( 0 ); //假定要读取的数据在第一个sheet中
int rows = sheet.getLastRowNum();
int cols = sheet.getRow(0).getLastCellNum();
ds = new DataSet( rows, cols );
for( int row = 0; row <= rows; row++ ) {
HSSFRow r = sheet.getRow( row );
for( int col = 0; col <= cols; col++ ) {
HSSFCell cell = r.getCell( col );
int type = cell.getCellType();
Object cellValue; //单元格数据值对象
switch( type ) { //根据单元格数据类型,将格值处理成对应的Java对象
case HSSFCell.CELL_TYPE_STRING:
......
case HSSFCell.CELL_TYPE_NUMERIC:
......
......
//格值处理代码比较长,此处省略
}
if( row == 0 ) ds.setColTitle( col, (String)cellValue );
else ds.setCellValue( row, col, cellValue );
//如果是第一行,则将格值设成列标题,否则设成数据集单元格数据
}
}
这段代码只能读取最简单格式的Excel文件,中间还省略了很多格值处理的代码,但代码已经不短了。如果文件格式更复杂,比如有合并格、复杂的多行表头表尾、数据记录分散于多行、交叉表等,读取数据的程序代码就会变得更长更复杂。可以看出,即使有了poi这样强大的开源包,使用Java来解析Excel仍然是非常麻烦的。
而且,Java 只提供比较基础的底层函数,缺乏专业的结构化数据计算函数,比如数据集的过滤、排序、分组统计、连接等,都需要程序员自己去编写,因此即使数据读出来了,但要进行后续的计算,仍然有大量的工作要做。
如果用 SPL 读取该文件则非常简单,只要写一行代码就可以:
A |
|
1 |
=file("simple.xls").xlsimport@t() |
2 |
=A1.select(amount>500 && amount<=2000) |
选项 @t 表示第一行是列标题,之后用select函数完成条件查询。
这段代码可在esProc的IDE中调试/执行,然后将其存为脚本文件(比如condition.dfx),通过JDBC接口在JAVA中调用,具体代码如下:
package Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class test1 {
public static void main(String[] args)throws Exception {
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call condition()");
printResult(result);
if(connection != null) connection.close();
}
…
}
上面的用法类似存储过程,其实SPL也支持类似SQL的用法,即无须脚本文件,直接将SPL script 嵌入JAVA,代码如下:
…
ResultSet result = statement.executeQuery("
=file(\"D:\\data\\simple.xls\").xlsimport@t().select(amount>500 && amount<=3000)");
…
其实 esProc 计算库也是封装了 Apache POI,但提供了更易读取 Excel 文件的方法,通过 SPL 专业的数据处理语法,不仅可以非常简洁的读写 Excel,还可以完美地支持各种后续计算工作。
读写 Excel 表格
结构化的Excel表格比较规范, SPL可用xlsimport/xlsexport函数进行读写。
比如:ordersNT.xlsx中第1个sheet的各列的业务意义依次是订单ID、客户编号、销售ID、订单金额、订单日期。部分数据如下:
A |
B |
C |
D |
E |
|
1 |
26 |
TAS |
1 |
2142.4 |
2009/8/5 |
2 |
33 |
DSGC |
1 |
613.2 |
2009/8/14 |
3 |
84 |
GC |
1 |
88.5 |
2009/10/16 |
4 |
133 |
HU |
1 |
1419.8 |
2010/12/12 |
5 |
32 |
JFS |
3 |
468 |
2009/8/13 |
6 |
39 |
NR |
3 |
3016 |
2010/8/21 |
7 |
43 |
KT |
3 |
2169 |
2009/8/27 |
将该表按客户编号的字母顺序从小到大的排序,相同的客户编号再按订单金额从大到小排序,最后保持原格式存入新Excel。
要计算出上述结果,可用如下SPL脚本:
A |
|
1 |
=file("D:/data/ordersNT.xlsx").xlsimport() |
2 |
=A1.sort(_2,-_4) |
3 |
=file("D:/data/ordersNT_sort.xlsx").xlsexport(A2) |
A1、A3:读写excel的第1个sheet。如果要读入指定sheet,可用xlsimport(;sheet序号或sheet名),如果要写入指定的sheet,可用xlsexport(A2; sheet序号或sheet名)
SPL也可以处理带列名(标题)的结构化表格,方法与文本文件类似。比如orders.xlsx部分数据如下:
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
26 |
TAS |
1 |
2142.4 |
2009/8/5 |
3 |
33 |
DSGC |
1 |
613.2 |
2009/8/14 |
4 |
84 |
GC |
1 |
88.5 |
2009/10/16 |
5 |
133 |
HU |
1 |
1419.8 |
2010/12/12 |
6 |
32 |
JFS |
3 |
468 |
2009/8/13 |
7 |
39 |
NR |
3 |
3016 |
2010/8/21 |
8 |
43 |
KT |
3 |
2169 |
2009/8/27 |
对该文件进行排序,结果带列名写入新文件,可用如下SPL脚本:
A |
|
1 |
=file("D:/data/orders.xlsx").xlsimport@t() |
2 |
=A1.sort(Client,-Amount) |
3 |
=file("D:/data/orders_sort.xlsx").xlsexport@t(A2) |
有时候我们需要在原表格后面追加结构相同的新数据,这种情况下只需使用@a选项,形如:
=file(""D:/data/orders_sort.xlsx").xlsexport@at(A2) |
如果原表格的最后一个有内容的行设置了外观属性,则追加的数据会继承该行的风格。比如原表格D列风格为#,##0.00,E列风格为mmm-dd-yyyy。如下表:
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
26 |
TAS |
1 |
2,142.40 |
Aug-05-2009 |
3 |
33 |
DSGC |
1 |
613.20 |
Aug-14-2009 |
4 |
84 |
GC |
1 |
88.50 |
Oct-16-2009 |
则追加数据后,结果如下表:
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
26 |
TAS |
1 |
2,142.40 |
Aug-05-2009 |
3 |
33 |
DSGC |
1 |
613.20 |
Aug-14-2009 |
4 |
84 |
GC |
1 |
88.50 |
Oct-16-2009 |
5 |
133 |
HU |
1 |
1,419.80 |
Dec-12-2010 |
6 |
32 |
JFS |
3 |
468.00 |
Aug-13-2009 |
如果原表格最后一个有内容的行之后的第一个空行设置了风格属性,则追加的数据会继承该行的风格属性。利用这个特点,我们可以实现按指定格式从无到有的输出数据。比如先建立空白Excel,设置第2行的D列风格为#,##0.00,E列风格为mmm-dd-yyyy。
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
再向该空白表格追加数据,结果如下:
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
133 |
HU |
1 |
1,419.80 |
Dec-12-2010 |
3 |
32 |
JFS |
3 |
468.00 |
Aug-13-2009 |
读写 Excel 单元格
前面的内容都是以表格或序列为单位读写Excel,有时候我们也会以精细的单元格为单位读写Excel。
比如:下面的表格在第1行有编辑者和编辑日期。
A |
B |
C |
D |
E |
|
1 |
editor:emily |
date:Dec-30-2011 |
|||
2 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
3 |
26 |
TAS |
1 |
2,142.40 |
Aug-05-2009 |
4 |
33 |
DSGC |
1 |
613.20 |
Aug-14-2009 |
5 |
84 |
GC |
1 |
88.50 |
Oct-16-2009 |
6 |
|||||
7 |
现在要将编辑者和编辑日期复制到第7行对应的位置上,结果应当如下:
A |
B |
C |
D |
E |
|
1 |
editor:emily |
date:Dec-30-2011 |
|||
2 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
3 |
26 |
TAS |
1 |
2,142.40 |
Aug-05-2009 |
4 |
33 |
DSGC |
1 |
613.20 |
Aug-14-2009 |
5 |
84 |
GC |
1 |
88.50 |
Oct-16-2009 |
6 |
|||||
7 |
editor:emily |
date:Dec-30-2011 |
要计算出上述结果,可用如下SPL脚本:
A |
B |
|
1 |
=file("D:/data/cell.xlsx") |
|
2 |
=A1.xlsopen() |
|
3 |
=str=A2.xlscell("A1") |
=A2.xlscell("A7";str) |
4 |
=str=A2.xlscell("E1") |
=A2.xlscell("E7";str) |
5 |
=A1.xlswrite(A2) |
A2:以对象方式打开Excel文件。
A3:读Excel对象的A1格,赋予变量str。默认从第1个sheet读,如果想读取指定sheet里的A1单元格,可用A2.xlscell("A1",sheet序号或sheet名)
B3:将A1格内容写入A7格。类似地,如果想在指定sheet里写入A7单元格,可用A2.xlscell("A7",sheet序号或sheet名;str)
A4-B4:读E1格内容,并写入E7格
A5:将Excel对象写入Excel文件。
上面例子中,需要读入的A1-E1是连续单元格,需要写入的A7-E7也是连续单元格,对于这种连续单元格的读写,SPL可以用更简化的代码来实现。比如上例的代码可以改成:
A |
|
1 |
=file("cell.xlsx") |
2 |
=A1.xlsopen() |
3 |
=arry=A2.xlscell@w("A1":"E1") |
4 |
=A2.xlscell("A7":"E7";arry) |
5 |
=A1.xlswrite(A2) |
A3:以序列的格式读入连续单元格
A4:向连续单元格写入序列,序列的每个成员对应一个单元格。既可以用序列向连续单元格写入数据,也可以用\t或\r分隔的字符串,其中\t表示横向分隔,\r表示纵向(跨行)分隔。
多sheet处理
使用Excel对象,不仅可用读写单元格,也可以处理多个sheet,下面举例说明。
某Excel用多个sheet存储订单表格,每个sheet的格式相同,但数量和名称不定。现在要将这些订单整理到新Excel中,每个sheet存一年的数据。
要计算出上述结果,可用如下SPL脚本:
A |
|
1 |
=file("orders_sheet.xlsx").xlsopen() |
2 |
=A1.(stname).(A1.xlsimport@t(;~)).conj() |
3 |
=A2.group(string(year(OrderDate)):name;~:content) |
4 |
=file("orders_result.xlsx").xlsopen@w() |
5 |
=A3.(A4.xlsexport@t(~.content;string(~.name))) |
6 |
=A4.xlsclose() |
A1:以对象方式打开源Excel文件。
A2:遍历每个sheet,读取每个sheet的订单,再合并所有订单。A1.(stname)表示从Excel对象A1中取出所有的sheet名。
A3:将订单按年份分组。
A4:以对象方式打开目标Excel文件。@w表示写模式,文件不存在时将新建文件。
A5:遍历A3的每组(每年)订单,依次写入到A4的新sheet中。
A6:@w模式打开的Excel对象必须用函数xlsclose关闭。
多文件关联计算
对两个数据表中的数据进行关联计算
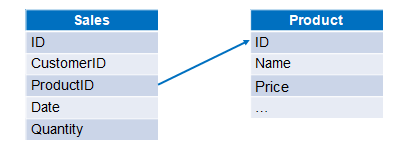
示例:销售订单信息和产品信息分别存储在两个Excel文件中,计算各订单的销售额。两个文件数据结构如下图:
A |
|
1 |
=T(“e:/orders/sales.xlsx”) |
2 |
=T(“e:/orders/product.xlsx”).keys(ID) |
3 |
=A1.join(ProductID,A2,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
A1 读取销售订单数据
A2 读取产品信息数据,设置ID为主键
A3 将A1按照ProductID与A2中的主键进行关联,同时引入Name、Price列数据
A4 A3中新增一列amount,其值为销售数量Quantity与产品价格Price的积
对两个数据表中的数据进行关联查询。
示例:仍用上节中的2个文件,查询产品价格大于20元的销售订单。
A |
|
1 |
=T(“e:/orders/sales.xlsx”) |
2 |
=T(“e:/orders/product.xlsx”).select(Price>20).keys(ID) |
3 |
=A1.switch@i(ProductID,A2) |
A1 读取销售订单数据
A2 读取产品信息数据,选出价格大于20的产品信息,然后设置ID为主键
A3 将A1按照ProductID与A2中的主键进行关联,选项@i表示在A2中找不到与ProductID匹配的产品ID时,则过滤掉此条记录
对主表与明细表数据进行关联查询
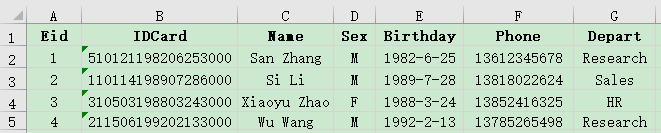
示例:有员工信息表employee.xlsx与员工家庭成员表family.xlsx部分数据如下,请查询家中有70岁以上老人的员工信息。
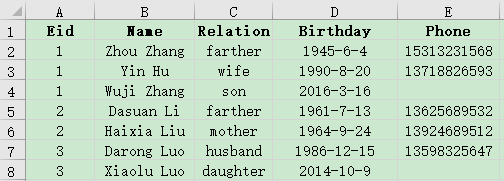
A |
|
1 |
=T("e:/work/employee.xlsx") |
2 |
=T("e:/work/family.xlsx").select(age(Birthday)>=70) |
3 |
=join(A1:employee,Eid;A2:family,Eid) |
4 |
=A3.conj(employee) |
A1 读取员工信息数据
A2 读取员工家庭成员数据,选出年龄70以上的成员
A3 将A1与A2按照Eid进行关联过滤,删除不匹配的记录,将A1命名为employee,A2命名为family
A4 取出A3中的employee列,连接为序表
最后说下esProc的配置。在 esProc IDE 读写计算Excel是esProc的基本功能,无需额外配置。
了解更多
常规数据表计算,参考 SPL 常规数据表运算
Excel 解析和导出专题,参考 SPL 解析及导出 Excel
SPL 与 Java 程序集成,参考 Java 如何调用 SPL 脚本


英文版