


十款好用的数据挖掘工具详细介绍
Python/R
Python 和 R 数据科学家最常用的工具,在机器学习领域有非常丰富的库资源,两者都是开源并且免费的,因此深受数据玩家们的喜爱。通常使用 Python 和 R 的都是专业的数据科学家,但是随着大数据的普及越来越多的非专业人士也需要使用数据做预测,Python 和 R 对他们来讲门槛就有些高了。因此本文调研了市场上一些比较知名的数据挖掘工具,以供不同水平和需求的人选择适合自己的工具。
SAS
SAS(STATISTICAL ANALYSIS SYSTEM)是由美国 NORTH CAROLINA 州立大学 1966 年开发的统计分析软件。SAS(Statistical Analysis System) 是一个模块化、集成化的大型应用软件系统。它由数十个专用模块构成,功能包括数据访问、数据储存及管理、应用开发、图形处理、数据分析、报告编制、运筹学方法、计量经济学与预测等等。SAS 系统基本上可以分为四大部分:SAS 数据库部分;SAS 分析核心;SAS 开发呈现工具;SAS 对分布处理模式的支持极其数据仓库设计。SAS 系统主要完成以数据为中心的四大任务:数据访问、数据管理、数据呈现、数据分析。SAS 持续良好的统计分析功能,得到了业界广泛好评,这为它在国际专业统计分析软件领域获得头把交椅奠定了基础。
SAS EM 是专门用作数据挖掘的模块,它将数据挖掘的核心过程分为抽样、探索、修整、建模及评估几个阶段,采用图形化的操作界面,用户可以通过拖拉拽的方式进行建模。同时 SAS 也支持通过编程的方式来处理数据进行分析,但是编程语法要符合 SAS 的要求。SAS EM server 负责处理从客户端的发来的数据挖掘要求,并把处理的结果经过 SAS connect 转送给客户端。SAS EM 中提供了大量的功能模块,可让有经验的人士快速精细的调整分析建模过程。
相比于 Python/R,SAS 的操作更加简单,运行稳定,但是价格也比较昂贵,在金融行业和医药行业 SAS 比较流行,一般大型银行几乎都会部署 SAS。SAS 比较适合高级用户使用。它的学习过程是艰苦的,最初的阶段会使人灰心丧气。然而它还是以强大的数据管理和同时处理大批数据文件的功能,得到高级用户的青睐。
SPSS
SPSS Clementine 是 Spss 公司收购 ISL 获得的数据挖掘工具。在 Gartner 的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS 和 SPSS。
SPSS 界面友好,使用简单,但是功能强大,可以编程,能解决绝大部分统计学问题,比 SAS 更加好学。它有一个可以点击的交互界面,能够使用下拉菜单来选择所需要执行的命令。它也有一个通过拷贝和粘贴的方法来学习其“句法”语言,但是这些句法通常非常复杂而且不是很直观。相比于 SAS,SPSS 在政府和教育行业更受欢迎。虽软 SPSS 操作相对简单,但使用者通常也需要具备一定的统计学基础。
Weka
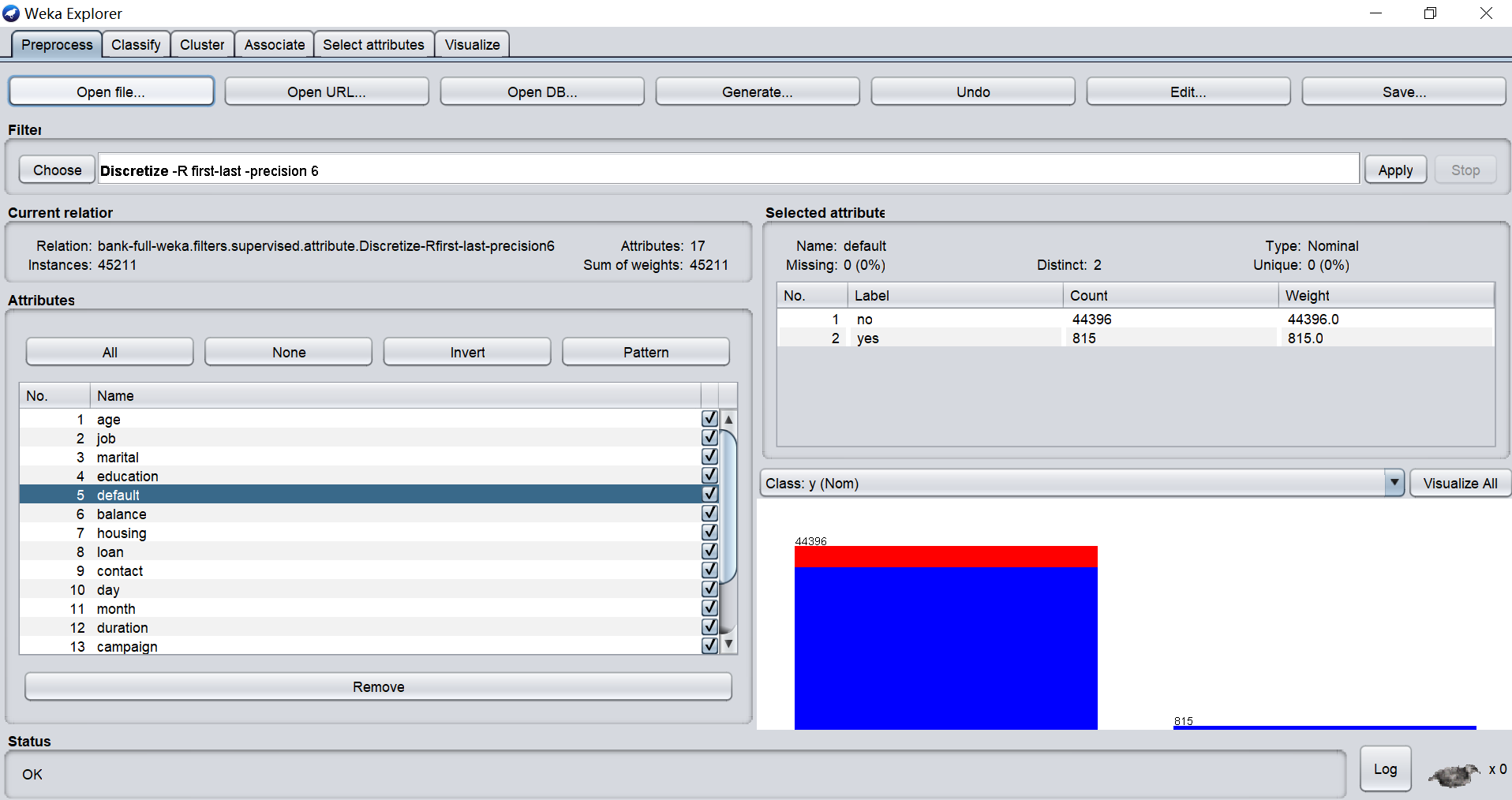
WEKA 的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),同时 weka 也是新西兰的一种鸟名,而 WEKA 的主要开发者也来自新西兰。WEKA 作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。如果想自己实现数据挖掘算法的话,可以看一看 weka 的接口文档。在 weka 中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
Weka 基于 Java 开发,是一款开源且免费的软件,有 Windows 版本,Linux 版本和 Mac OS 版本。在数据源上支持 ARFF(Attribute-Relation File Format)文件,这是一种 ASCII 文本文件,CSV 文件和 JDBC 数据库访问功能。
Weka 轻巧便捷,安装简单,非常适合个人用户和中小企业使用。在操作上可以可视化操作无需编程,支持拖拉拽式工作流程使用起来非常方便,但是无论是数据预处理还是算法选择和调参都需要工程师手动完成,因此使用者需要具备一定统计学基础和数据挖掘经验。

H2O.ai
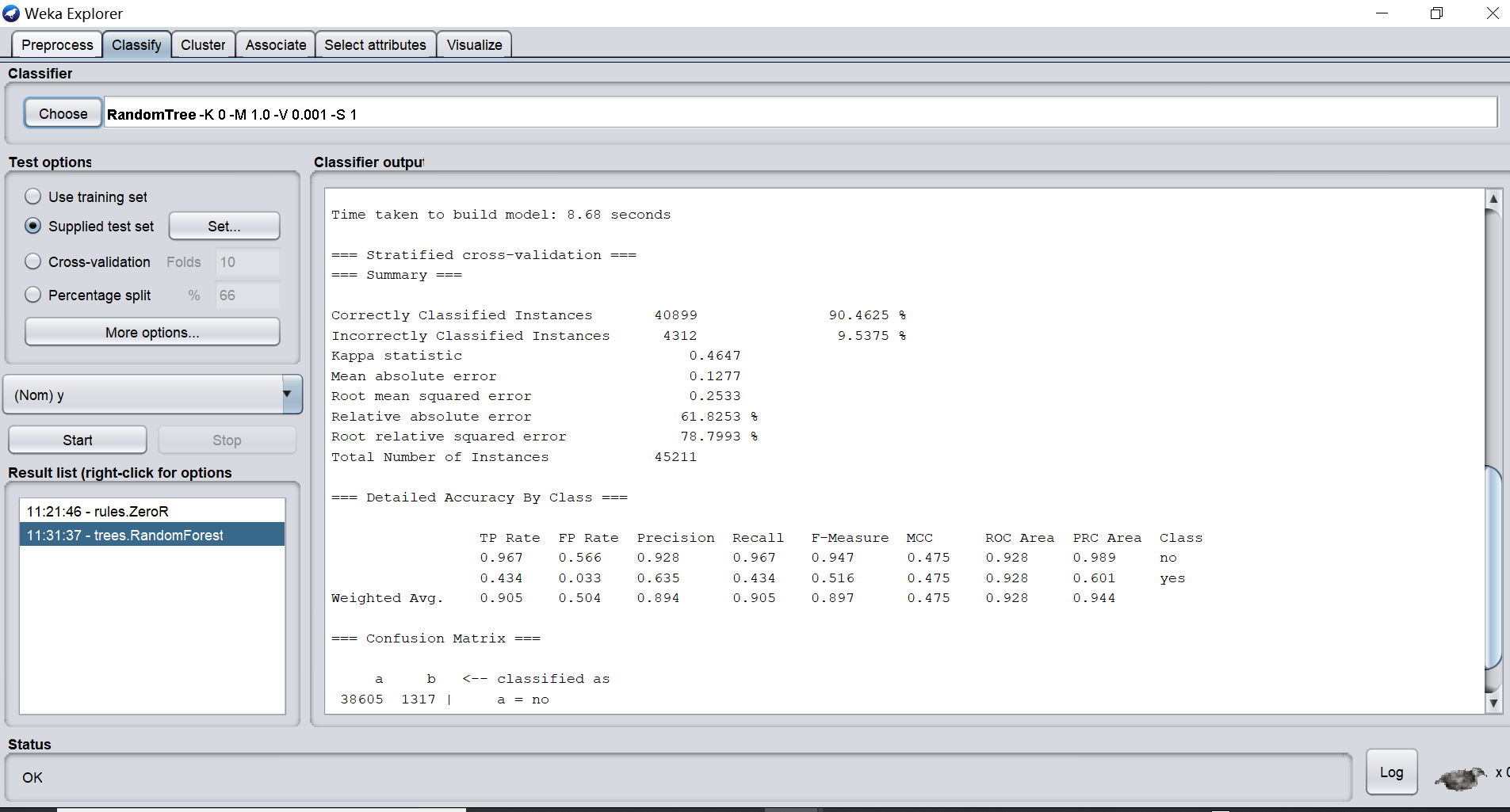
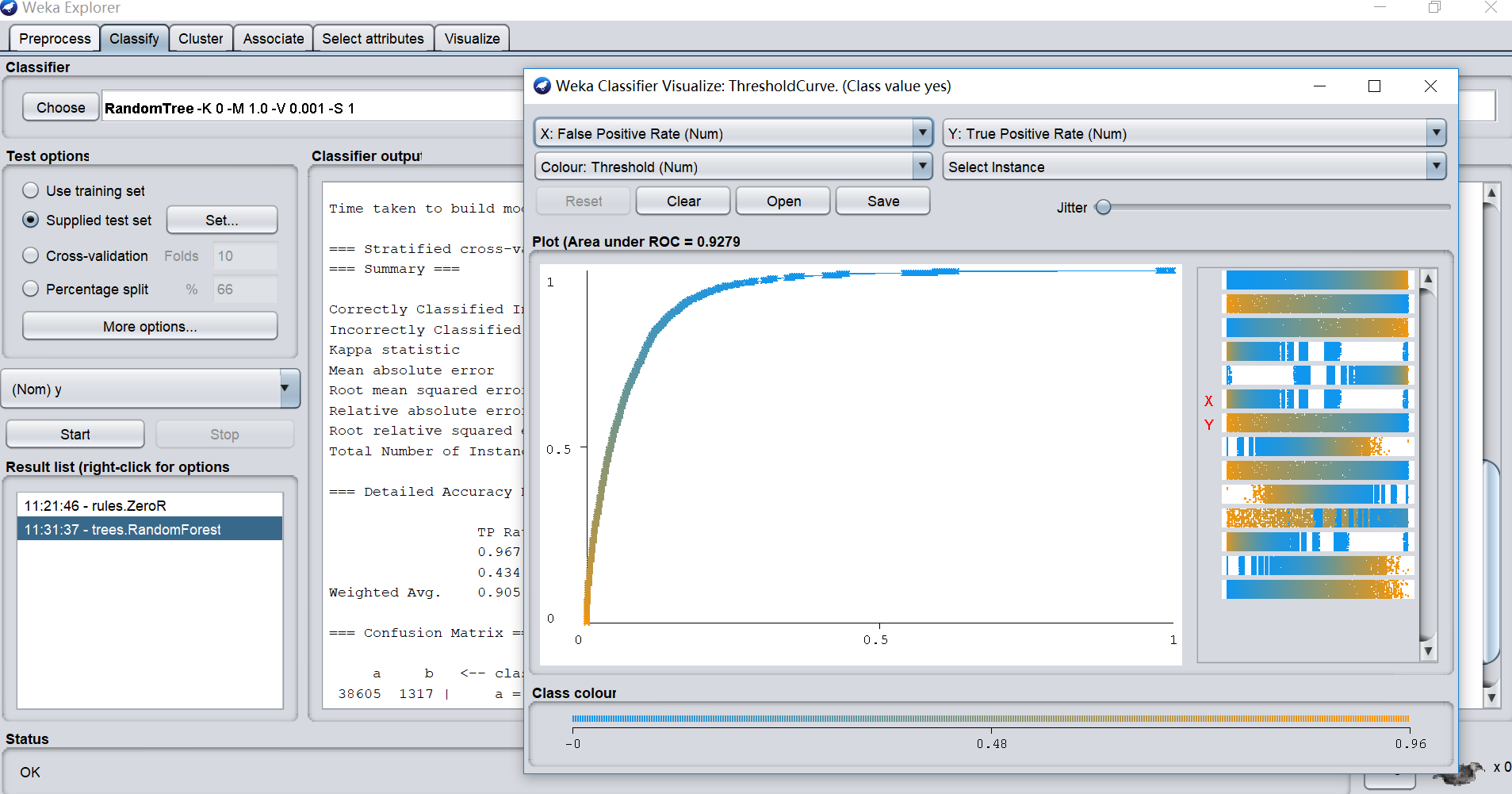
H2O.ai 是初创公司 Oxdata 于 2014 年推出的一个机器学习平台,它是一个开源的分布式内存机器学习平台,具有线性可扩展性。 H2O 支持分类、回归、聚类常用的机器学习算法,并且还具有 AutoML 功能。 H2O 的开发语言式 Java 和 Python,它的 REST API 允许从外部程序或脚本访问 H2O 的所有功能,该平台包括用于 R、Python、Scala、Java、JSON 和 CoffeeScript / JavaScript 的接口,以及内置的 Web 界面。
虽然 H2O 是开源的但其实还是一个商用的机器学习平台,用户需要付费使用。H2O 有安装版和云服务,其中安装版只支持 Linux。相比于 Weka 的轻巧便捷,H2O 安装部署起来则就相对麻烦,对机器配置也有一定要求。
实际上 H2O.ai 平台主要集成了三部分内容:
1、jupter notebook:通过代码的方式处理数据和搭建模型,适用于对建模熟悉,编程熟悉的人;
2、H2Oflow:提供图形化界面,进行拖拉拽式建模,适用于熟悉建模的人,快速数据分析;提供 21 天的试用授权
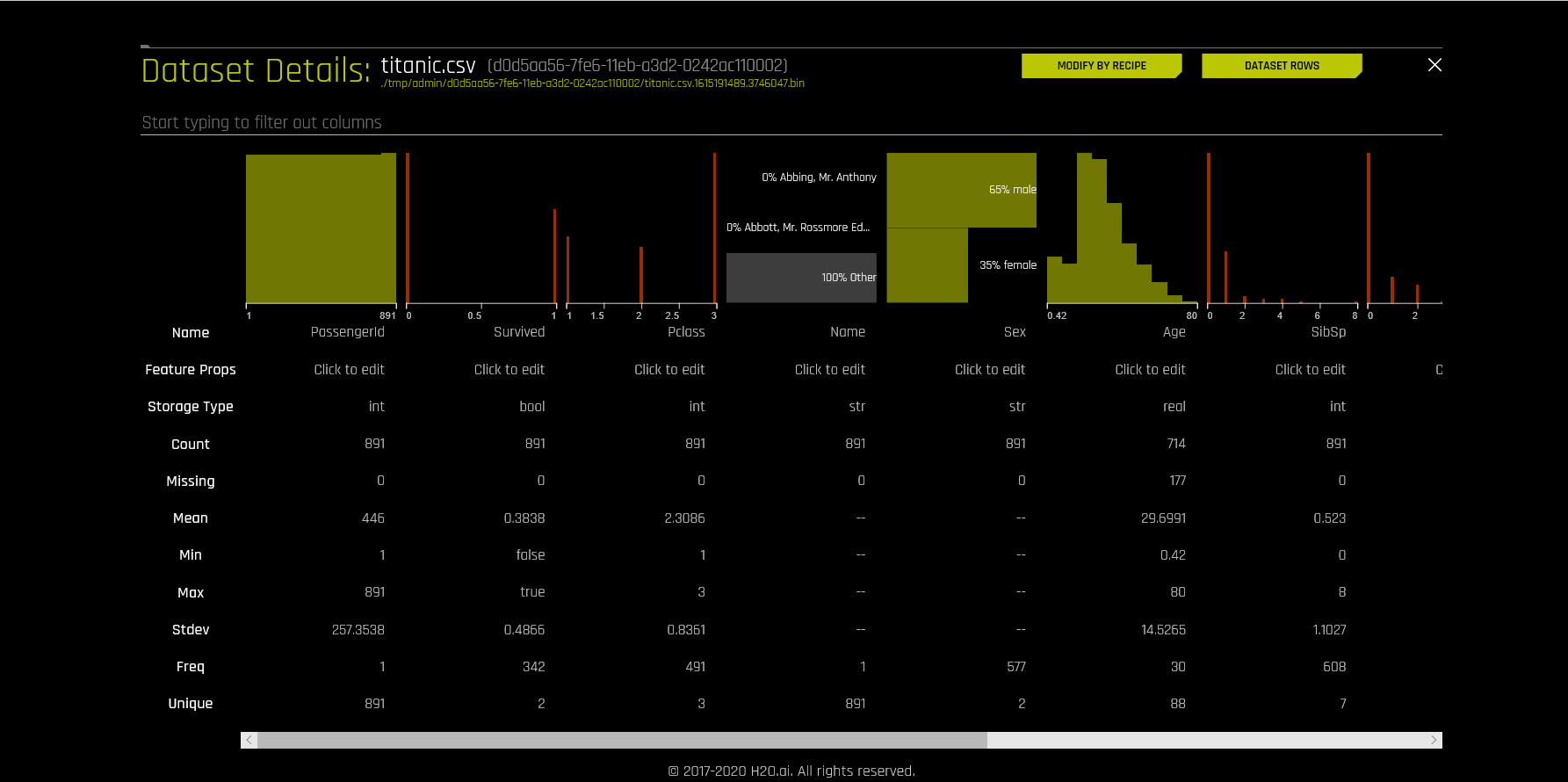
3、Driverless:自动建模,适用于初学者。但需要注意的是 Driverless 需要设置要训练的模型个数上线或最长训练时间,因为自动建模的底层会尝试对用户所选择的模型的参数进行 GridSearch(网格搜索),以此来进行模型超参的调优。若没有设置好模型个数上线或最长训练时间,可能会出现跑了很久依然没有结束的情况。这种类似于暴力搜索的寻参方式虽然可以自动建模但是缺点也比较明显,一方面耗时长,投入计算资源较大,经济型差,另一方面对于无建模经验的人士也不太友好。Driverless 提供 2 个小时的免费使用,之后就要付费试用。
以下是 Driverless 的界面截图:
RapidMiner
RapidMiner 公司总部位于美国马萨诸塞州剑桥,是一款基于 Java 开发的数据挖掘软件。RapidMiner 功能强大,通过在图像化界面拖拽建模,可轻松实现数据准备、机器学习和预测模型部署,无需编程,运算速度快,并且 RapidMiner 还具备自动建模功能,使用非常方便。
RapidMiner 主要有以下系列产品:
RapidMiner studio: 可零代码操作的客户端软件,基于图形化的拖拉拽操作,可手动建模也可自动建模。能够实现完整的建模步骤,从数据加载、汇集、到转化和准备阶段(ETL),再到数据分析和产生预测阶段。Studio 安装包支持 Windows,Linux,MaxOS,有免费版和商业版,其中免费版对于数据量有限制,最多可运行 10000 行数据。Studio 安装包和授权可在官网申请下载。
RapidMiner Server: 可以在局域网服务器或外网连接的服务器上,与 RapidMiner Studio 无缝集成
RapidMiner Radoop: 一个与 Hadoop 集群相连接的扩展,可以通过拖拽自带的算子执行 Hadoop 技术特定的操作.
RapidMiner go 云平台服务,提供 5 天免费试用期。
总体来讲,RapidMiner 是一款非常不错的软件,界面操作非常友好,功能完善,既适合初学者也适合有经验的工程师,并且可在自动建模和手动建模之间切换。
YModel
YModel 是由易明公司开发的一款专注于自动建模的软件,在自动建模领域有着很大优势。
与大多数拖拉拽式建模不同的是,自动建模可以实现一键式操作,既数据预处理,算法选择调参,模型选择和评估等一系列流程完全由软件自动完成。这对于初级用户来说是非常友好的,也很适合没有专业数据团队中、小企业快速实现数字化应用。
YModel 的自动建模最大的特点就是不仅模型精准,而且由于它的寻参方式采用自主研发的智能寻参,因此建模速度很快,非常节省计算资源。例如大多数的自动建模时间至少以小时起计算,而 YModel 可能几分钟就建好了。为保证模型的泛化能力,YModel 会将几个优质模型自动融合,这也是几乎所有自动建模产品所不具备的功能。
YModel 基于 Java 和 Python 开发,有 Windows 版本和 Linux 版本。和 Weka 类似,YModel 也是一款轻巧便捷的软件,安装简单,一台笔记本就能运行。
YModel 产品分为个人版和企业版,个人版是完全免费的,数据量和功能上也没有限制,只是不能连接数据库。企业版则可以支持各种 JDBC 标准接口的数据库以及并行运算,虽然企业版是收费的但是也相当便宜,一年才几千块人民币。
总体来讲,YModel 的优势就是自动化能力强,轻巧便捷部署方便,经济性强,适合中小企业、初学者和普通职场人士使用。
Orange
Orange 由斯洛文尼亚大学计算与信息学系的生物信息实验室 BioLab 进行开发,是一款免费开源的数据挖掘软件,可在官网下载,支持 Windows, Linux 和 MacOS。
Orange 由 C++ 和 Python 开发,包含了一系列的可视化组件可以进行数据预处理,建模和模型评估的功能,并且用户还可以在 Python 里调用 Orange。Orange 可以支持分类、回归和聚类算法,全流程采用图形化操作。
Orange 的优点就是开源免费,可视化操作,可以帮助有经验的工程师快速建模,适合高级用户。
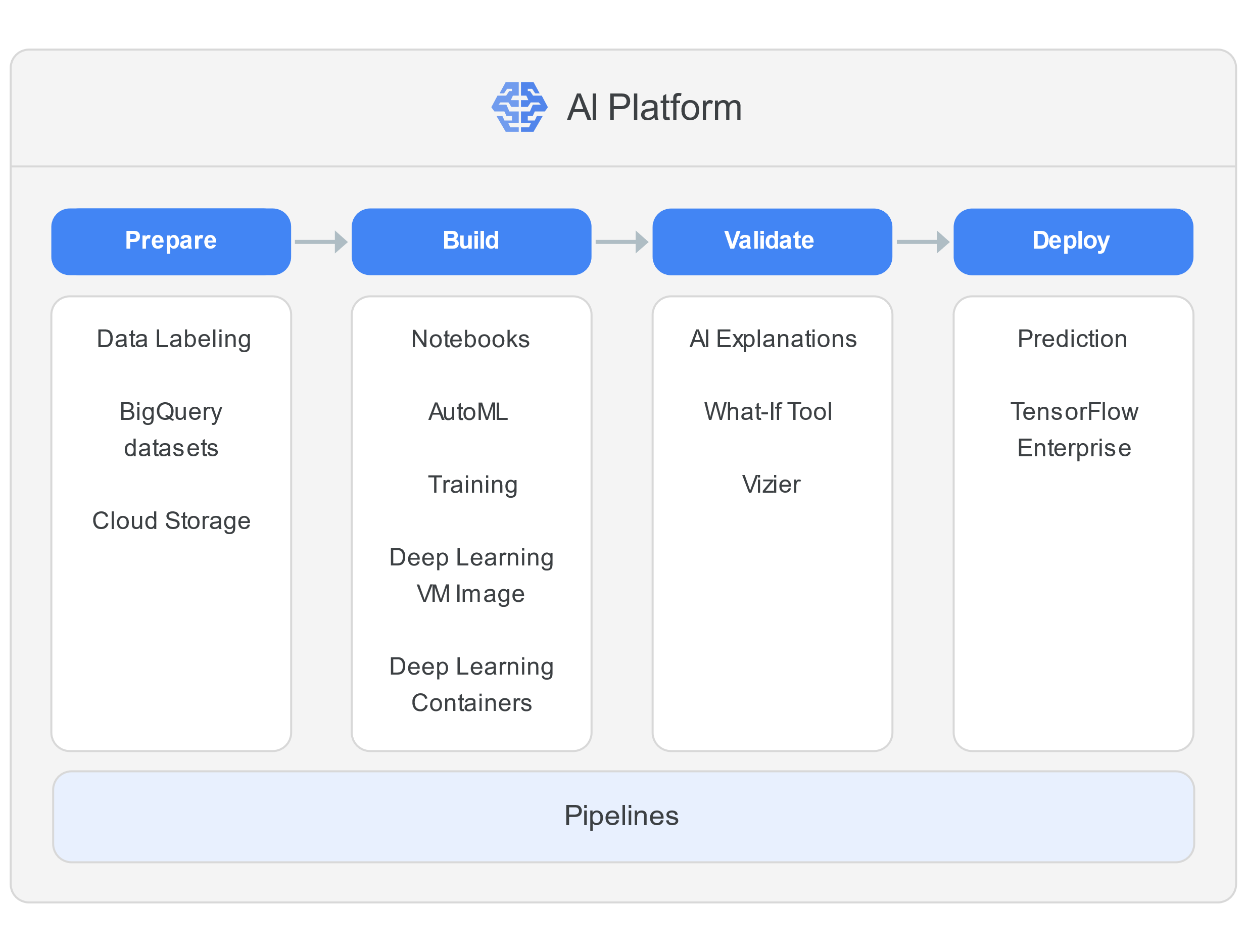
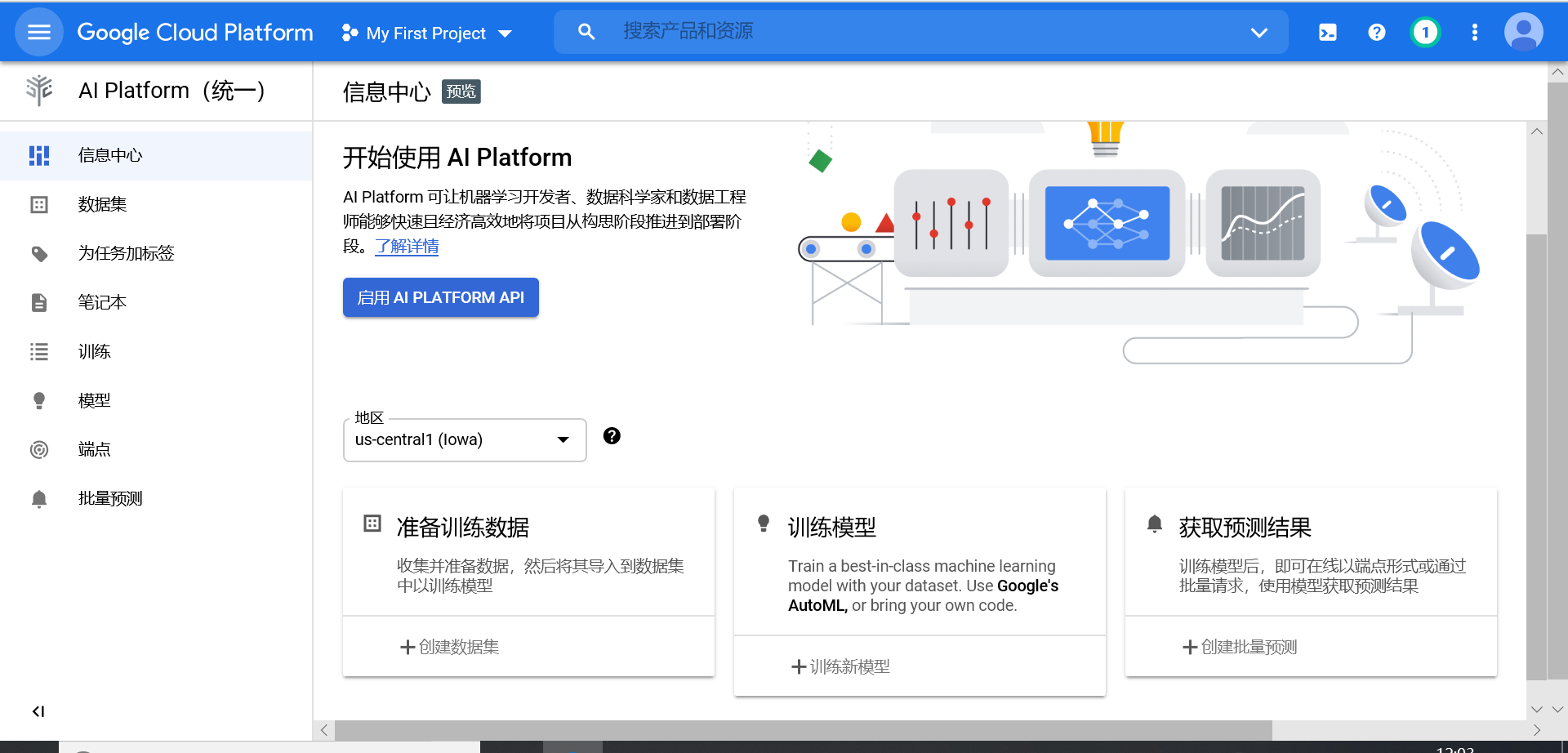
Google 的人工智能平台可以提供端到端机器学习生命周期,用户可以自行通过 Notebooks(一种代管式 Jupyter Notebook 服务)编写代码,使用 Deep Learning VM Image 或 Deep Learning Containers 上最新的开源深度学习框架,然后,使用全代管式 Training 服务训练模型。也可以使用 Google 的 AutoML 无需编写任何代码就能构建机器学习模型。
Google 的人工智能平台采用基于 Tensorflow 的神经网络模型,模型精度较好,但是需要海量的算力支持,背后是 Google 强大的计算机工程,建立成百上千 cpu、gpu 集群才行,一般的企业和个人很难落地投产,即使是购买 Google 的服务收费也是比较贵的。
在场景方面深度学习适合于计算机视觉、语音识别、记忆网络、自然语言处理等领域。
Knime
KNIME 的原始开发团队来自硅谷的一家公司,最初为制药行业提供软件,目前已发展成一个高度可扩展和开放的数据处理平台。
KNIME 允许用户直观地创建数据流(或管道),有选择地执行一些或所有分析步骤,然后检查结果,模型和交互式视图,也就是支持拖拉拽式的图形化建模方式。KNIME 采用 Java 编写,并且基于 Eclipse,利用其扩展机制来添加提供附加功能的插件。核心版本已经包含数百个数据集成模块(文件 I / O),数据转换(过滤器,转换器,组合器)以及常用的数据分析和可视化方法。KNIME 还集成了很多其他的开源项目,例如从机器学习算法的 Weka,统计包 R 项目,以及 LIBSVM,JFreeChart 的,ImageJ 的和化学开发工具包。
KNIME 的产品有开源的部分也有闭源的部分,开源的部分有,KNIME Analytics Platform、KNIME Extensions、KNIME Integrations、Community Extensions;闭源的部分有,KNIME Server 以及 Partner Extensions。
KNIME Analytics Platform:KNIME 分析平台,我们可以利用 KNIME 来图形化的构造数据模型。
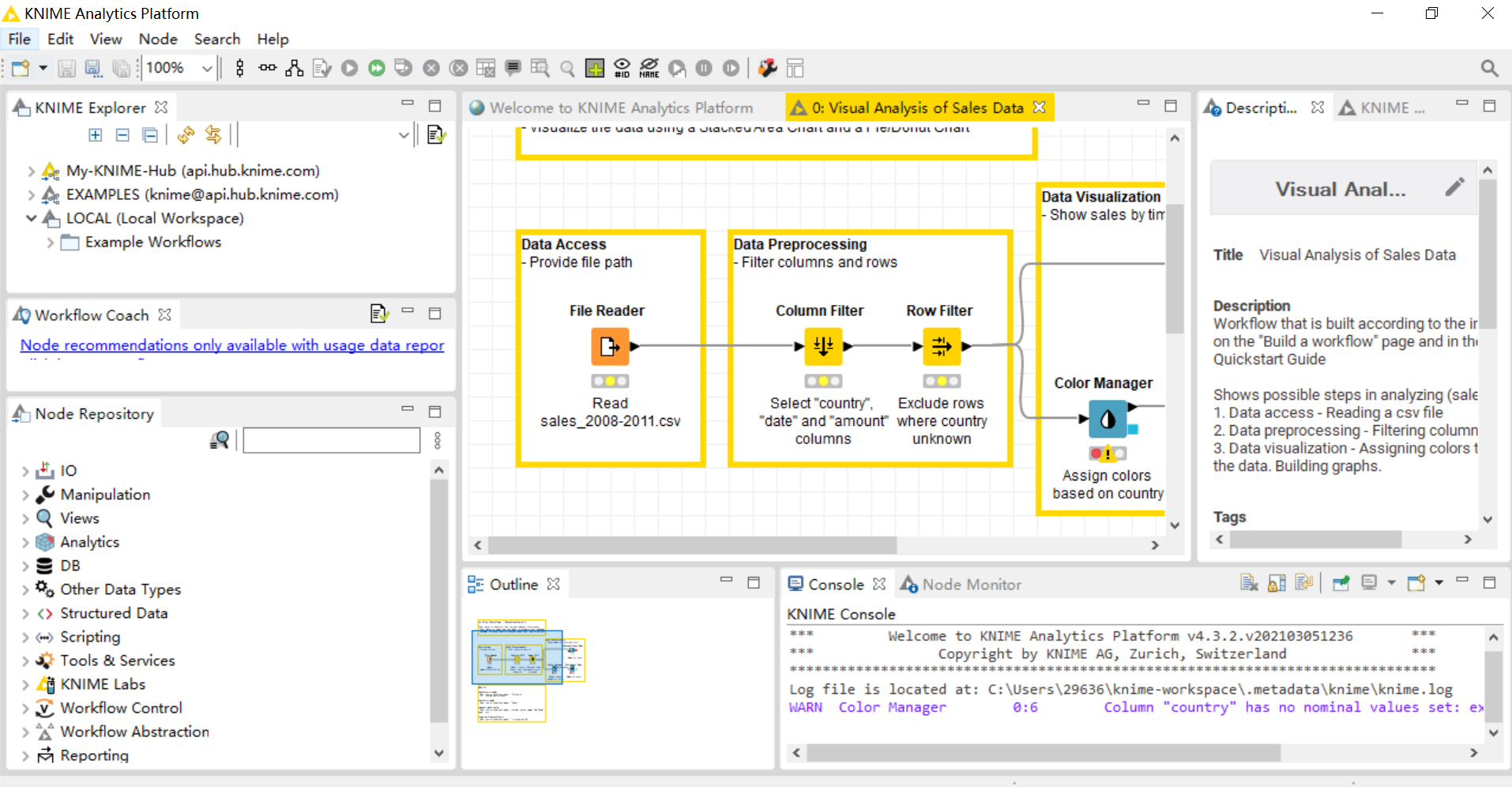
KNIME Server:KNIME 服务端程序。KNIME 服务端程序提供了 workflow 协作、自动化执行、自动化管理、自动化部署、引导式分析(guided analytics)等一系列功能,这部分功能为团队提供了极大的便利。这部分是需要收费的。这也是 KNIME 公司的主要收入来源之一。
KNIME Extensions:KNIME 扩展程序。扩展程序主要是在 KNIME Analytics Platform 的基础上,增加了一些复杂的数据类型,以及一些额外的机器算法。比如对于文字处理、图模型等等模块就属于 KNIME 的扩展程序。
KNIME Integrations: KNIME 集成程序。这一部分主要是 KNIME 利用大型的第三方的工具或是语言,用来完成复杂的任务。这里的好处在于,有的功能 KNIME 中没有,但第三方的工具已经实现好了,那么 KNIME 就可以直接调用第三方工具进行处理,甚至可以再将第三方工具处理后的结果再放回 KNIME 进行下一步处理。对于一些需要大数据、机器学习、以及 Python、R 等工具的任务会特别方便。
Community Extensions:社区扩展程序。社区扩展是由社区成员贡献的扩展。其中有一部分被称为 Trusted Community Extensions – 信任的社区扩展,它是社区扩展程序的子集,它的主要特点在于它有一套严格的测试、版本兼容,以及版本的发布运维流程。
Partner Extensions:第三方扩展程序。这部分程序是由第三方公司维护的扩展,通常,这一部分扩展需要购买才能使用。
总体来看,Knime 是一个开放性比较高的平台,适合特殊场景或特殊算法需求较多的企业,其用户也是以高级用户为主。

