


【程序设计】9.1 [分类别] 分组与汇总
9.1 分组与汇总
当事物比较多的时候,人们会习惯将这些事物按属性分成若干类别,然后考察每个类别的一些汇总信息,这个操作表现在结构化数据上就叫分组。分组的具体动作为:把一个数据表中的记录按某个字段分成若干小集合,字段取值相同的分到同一个小集合,称为分组子集或一个组,然后计算每组记录的某些统计值以研究这些数据的规律。
比如,前面生成的人员表,我们可以按性别来统计平均身高和最大体重。
A |
|
1 |
=100.new(string(~):name,if(rand()<0.5,"Male","Female"):sex,50+rand(50):weight,1.5+rand(40)/100:height) |
2 |
=A1.groups(sex;avg(height):avg_height,max(weight):max_height) |
groups 函数即可实现上面的说的动作,这里也使用了层次参数,分号前是用来分组的字段,这里是 sex;分号后会是要做的汇总运算,这里有两个,平均身高和最大体重,用逗号分隔。
groups 函数的返回值是一个序表,它将以用于分组的字段以及汇总表达式作为数据结构;因为返回的是序表,需要设置字段名,就在 groups 函数的每项参数后面写上,用冒号分隔。被分组的排列中,分组字段有多少种取值,这个返回序表就会有多少条记录。

(因为数据随机生成,统计值每次都会变,且不太符合生活常识,但不影响理解)
groups 函数后半部分的汇总运算并不能随便写,只能支持事先做好的几种聚合函数,常见的汇总运算有五种:求和 sum、计数 count、平均 avg、最大 max、最小 min。在参数中写上这些运算,就相当于针对这些分出来的子集(也是个排列)再执行聚合函数。
汇总还可以针对表达式来做,比如:
A |
|
1 |
… |
2 |
=A1.groups(sex;min(weight/height/height):min_bmi) |
也不一定是按字段分组,还可以用字段计算出来的结果来分组。
A |
|
1 |
=100.new(date(now())-100+~:dt,rand()*100:price) |
2 |
=A1.select(day@w(dt)>1 && day@w(dt)<7) |
3 |
=A2.groups(day@w(dt)-1:wday;min(price):min_p,max(price):max_p) |
对股票数据分组汇总,计算出所有周一、周二、…、周五的最高和最低股价,计算结果是 5 条记录(周末已经被排除掉了)。
用于分组的字段或表达式,我们有了一个术语叫分组键。等学习到后面,我们会理解为什么会用键这个词。
分组键还可以有多个:
A |
|
1 |
=1000.new(date(now())-1000+~:dt,rand()*100:price) |
2 |
=A1.select(day@w(dt)>1 && day@w(dt)<7) |
3 |
=A2.groups(month(dt):m,day@w(dt)-1:wd;avg(price):price) |
A3 可以计算每个月内的每个星期几的平均股价。有多个分组表达式时,会把数据表拆得更细,成员数大体会相同于这些分组键的取值种类数量之积,比如上面这个运算就会分出 12*5=60 组,因为月份有 12 种,星期有 5 种(除去周末)。返回序表也就是有 60 条记录。
不过,这并不是绝对的,因为这套数据中,任何一种月份下任何星期几的数据都存在,所以这 60 个分组都会对应有汇总数据。但有时数据不完整,有些分组就会不存在,比如在把 A2 做个抽样,随便其中 100 条记录再观察分组结果(我们之前学过如何做抽样),看看返回序表是不是总会有 60 条记录。请读者自己尝试一下。
因为可能有多个分组键,所以 groups 函数要用更高一级的分号来分隔参数中用于分组键的表达式和用于汇总的表达式,这里可以体会一下层次参数的方便之处。
分组汇总其实还可以干脆没有分组键。
A |
|
1 |
… |
2 |
=A1.groups(;min(weight/height/height):min_bmi) |
这意味着把所有成员分成一个集合,其实也就是不拆分了,针对这个全集再计算出一些汇总值,返回的序表只有一条记录。
不过,这种运算不常见了,因为可以直接用聚合函数来做了。
类似地,分组汇总也可以没有汇总值部分:
A |
|
1 |
… |
2 |
… |
3 |
=A2.groups(month(dt):m,day@w(dt)-1:wd) |
A3 将计算出这些股票交易发生在哪些月份和星期几(可以结合刚才我们说的抽样减少数据量来尝试),也就是说我们只关心能分出什么样的组,而不关心每个分组的汇总值了。
这是个较常见的运算,它将计算出一个数据表中针对分组键有哪些可能的取值,把这些可能的取值一个不落且没有重复地列出来。数据库界对这种运算有个专门的名字叫求DISTINCT值,中文则有多种译法,常见的术语有去重、取唯一值,我们这里就直接叫 DISTINCT 算了。
SPL 另外给了一个函数 id 用来计算 DISTINCT。
A |
|
1 |
… |
2 |
… |
3 |
=A2.groups(month(dt):m) |
4 |
=A2.id(month(dt)) |
与 groups 返回序表不同,id 返回的是序列,没有数据结构,所以也没有字段名参数。
有多个参数的 id 函数也不是针对多个分组键一起计算 DISTINCT,而是分别计算得到多组 DISTINCT 值,如果想针对多个分组键一起计算,需要用序列表达式。
A |
|
1 |
… |
2 |
… |
3 |
=A2.groups(month(dt):m,day@w(dt)-1:wd) |
4 |
=A2.id(month(dt),day@w(dt)-1) |
5 |
=A2.id([month(dt),day@w(dt)-1]) |
可以观察 A3、A4、A5 的返回结果,特别是看看这些返回值(作为序表或序列)的长度。
再提醒一下,把数据抽样后再执行这些代码,会更容易看出差别。
现在给我们一些 Excel 文件,我们已经会对其中的数据做各种分类统计了,比如我们多次用来举例的这个数据:
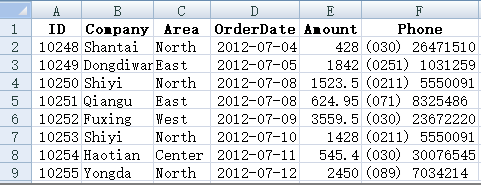
想按地区或月份统计销售额和订单数量,那是非常容易的事:
A |
|
1 |
=T("data.xlsx") |
2 |
=A1.groups(Area;sum(Amount),count(Amount)) |
3 |
=A2.groups(month@y(OrderDate);sum(Amount),count(Amount)) |
file(…).xlsimport@t() 可以简化成一个 T 函数。注意 SPL 是大小写敏感的语言,字段名要写正确。
想算算都和哪些公司做过生意,也很轻松:
A |
|
1 |
=T("data.xlsx") |
2 |
=A1.id(Company) |
DISTINCT 让我们知道了存在不必做汇总的分组,其实还有不能做汇总的分组。
比如,一群人中,我们想知道有哪些人和别人有相同的生日。很简单,按生日分组后看看哪些组的成员数大于 1 就行了。但是,groups 函数会迫使一个汇总动作,我们将失去那些分出来的小组了。
分组不一定总是被强制汇总,有时候我们还对分组后子集感兴趣。其实分组这个词在字典上就是只有拆分的意思,并没有继续汇总的意思。因为这个运算是 SQL 发明的,而 SQL 的集合数据类型比较弱,无法保持分组的中间结果,所以强迫做一次汇总。久而久之,整个业界都觉得分组必然伴随汇总,而把分组的本意都忘了。
SPL 还原了这个运算,没有 s 的 group 函数就只管分组不管汇总,groups 函数名中多的这个 s 就是表示汇总(summary)的意思。
A |
|
1 |
=200.new(string(~):ID, date(now())-10000+rand(3000):Birthday) |
2 |
=A1.group(month(Birthday),day(Birthday)) |
3 |
=A2.select(~.len()>1).conj() |
随机生成 200 个人的生日,然后按生日(不能算年)分组。group 函数返回的就是分出来的各个组,也就是一些排列构成的序列,相当于一个二层序列。然后,我们只要看看哪个组的成员数大于 1 就行了,这是我们已学过的语法。最后把这些组再合并起来。
只分组不汇总是有现实业务意义的。找有同生日的人,还只能算个游戏。我们再举个实用的例子,比如还是刚才那个 Excel 文件,我们希望把它按 Area 字段拆分成多个,分别不同的经理去处理。
用分组运算来拆分是合理的,但显然不能再做汇总了。
A |
B |
|
1 |
=T("data.xlsx") |
=A1.group(Area) |
2 |
for B1 |
>T(A2.Area/".xlsx",A2) |
T 函数还可以把一个排列直接写成一个 Excel 文件。按 Area 分组后,把每个组写成对应的文件就完事了。A2.Area 就是 A2(1).Area 的简写,SPL 约定,对一个排列取字段就相当于对其第一个成员取字段。
有时候即使我们想得到的是分组子集的某个聚合结果,但它并不容易计算,没有简单的聚合函数能写出来,这时我们也需要保持分组子集用来进一步计算。
比如想把人员表按性别分组后,把同性别的人名(现在就是些数字串)连成一个逗号分隔的串。这确实是个聚合结果,但 SPL 没有这样的的聚合函数,不过自己写表达式却是会的:
A |
|
1 |
=100.new(string(~):name,if(rand()<0.5,"Male","Female"):sex,50+rand(50):weight,1.5+rand(40)/100:height) |
2 |
=A1.group(sex).new(~.sex,~.(name).concat@c():Names) |
针对分组后子集序列再做一次 new 就可以了。
这种运算比较常见,SPL 还允许把它简化到 group 函数的参数中:
A |
|
1 |
… |
2 |
=A1.group(sex;~.(name).concat@c():Names) |
注意,这容易和 groups 混淆。group 分号后的计算相当于简化的 new,需要写表示分组后的某个子集,而 groups 里是不用写的,它的计算方式其实也不一样,没有先算出子集再计算汇总值。
我们前面说过有五种常见汇总运算,SPL 还提供了其它可以用到分组汇总中的聚合函数,但大部分不用专门讲,需要时去查资料就可以。只有一个 icount 需要提一下。
icount(x) 返回每个组内的 x 的 DISTINCT 值的数量。这大体相当于在分组内又做了一次分组,但内层分组只做计数而不再做其它汇总了。
比如,我们想计算每个地区都和几个公司做过生意:
A |
|
1 |
=T("data.xlsx") |
2 |
=A1.groups(Area;icount(Company)) |
如果理解了前面讲过的迭代函数,SPL 还允许自己拼出新的分组汇总运算。而且充分理解迭代函数后,也能体会到 groups 和 group 在计算汇总值时采用的方法不同,groups 是用迭代函数的方法来计算汇总值的,过程中并不会保持每个分组子集,这样会更高的效率并占用更少的存储空间,这也是把 groups 单独设计出来的主要原因(比 group 有时写得略微简单只是次要原因)。
另外提一句,分组运算并不只是针对结构化数据才有效,对于数值或字符串序列也可以执行分组。
A |
|
1 |
=100.(rand(100)).groups(~%2;sum(~)) |
2 |
=directory("*.*").group(filename@e(~)) |
A1 将把整数按奇偶分组并计算每组的和;A2 把路径下的文件名按扩展名分成若干组。
不过,针对序列的分组相对不太常见,所以我们放到结构化数据部分来讲这个运算。

