


【程序设计】8.5 [表一表] 字段上的计算
8.5 字段上的计算
我们前面说过,结构化数据在行和列方向的能力是不对称的,方便的批量运算通常只对行方向提供,而列总是以独立的个体出现。但我们在个别时候也需要对列方向也进行一些整体运算,也就是把一批字段作为一个集合一起处理。
我们再来做那个合并 Excel 的问题,需求改一下:要把文件名拼到所有列的前面。
derive 函数只能把字段追加到后面,要改变字段的次序,目前只能重新 new 出来,但这样我们必须知道这个序表已经有些什么字段,把这些字段重新抄一下才可以。
fname 函数可以返回序表字段名构成的序列,也就是个字符串构成的序列。但这还不够,即使我们把新的字段拼到了前面,却仍然不知道怎么写这个 new,比如下面的代码:
A |
|
1 |
=10.new(rand(10):a,rand(20):b,rand(30):c) |
2 |
=A1.fname() |
3 |
=A1.new(0:NewField, A2) |
A1 是个序表,A2 取出了它的字段名序列,但 A3 这么写却没什么意义,SPL 会生成一个名叫 A2 的字段,其取值就是 A2 现在的格值,也就是 A1 的字段名序列。SPL 执行到这里的时候,并不知道要把 A2 的值拼到这句代码中,而会把 A 和 2 这两个字符本身作为代码的一部分执行。
那要怎么办呢?
SPL 提供了动态程序的语法,上面的代码写成这样,就可以正确执行了:
A |
|
1 |
=10.new(rand(10):a,rand(20):b,rand(30):c) |
2 |
=A1.fname().concat(",") |
3 |
=A1.new(0:NewField, ${A2} ) |
concat 函数我们用过了,它会把一个字符串序列用指定分隔拼到一起,这里我们用的是逗号。这里 A1 有 a,b,c 三个字段,那么 A2 的计算结果就是字符串 "a,b,c"。
A3 中 ${} 的意思,就是告诉 SPL,要把花括号里面的表达式计算出来(会是一个字符串),然后把这个字符串作为部分拼进去语句,然后再执行。A2 现在是 "a,b,c",那现在 ${A2} 就会把这个字符串拼进 A3 中的语句,结果 A3 实际要执行的语句是
=A1.new(0:NewField, a,b,c)
这就就是我们想要的结果了。
${} 的写法称为宏。利用宏可以动态地拼出一些代码来执行,可以实现出非常灵活的运算效果。与不确定个数字段相关的计算常常会用宏来配合,
利用宏,我们来解决合并 Excel 中把文件名拼到前面的问题:
A |
B |
|
1 |
=directory@p("data/*.xlsx") |
|
2 |
for A1 |
=file(A2).xlsimport@t() |
3 |
=B2.new(filename@n(A2):File,${B2.fname().concat@c()}) |
|
4 |
=@|B3 |
|
5 |
=file("all.xlsx").xlsexport@t(B4) |
|
concat@c 就表示用逗号分隔,${} 里可以写计算表达式,只要计算结果是字符串即可。
使用宏的办法,我们可以方便地生成学生成绩表:
A |
|
1 |
[English,Maths,Science,Arts,PE] |
2 |
=A1.("rand(100):"+~).concat@c() |
3 |
=100.new(string(~,"0000"):id, ${A2}) |
A2 的计算结果会是字符串:
“rand(100):Engligh,rand(100):Maths,rand(100):Science,rand(100):Arts,rand(100):PE”
拼入 A3 后即就得到一个 100 个学生的成绩表,id 字段是学生的学号。
现在我们想为每位学生计算一个总分字段 Total 并追加到后面。
A |
|
… |
… |
4 |
=A3.derive(English+Maths+Science+Arts+PE:Total) |
这当然没问题,但如果这些科目很多,那写起来就比较辛苦了。
SPL 提供了把记录的字段转换成序列的方法,需要批量处理字段值时就会方便很多:
A |
|
… |
… |
4 |
=A3.derive(~.array().to(2,).sum():Total) |
r.array()将记录 r 的各字段值取出来构成一个序列返回。这样,无论多少科目,都只要写这么长。需要注意的是,由于各个字段取值的数据类型可能不一样,array() 的返回值也不一一定是由同一种数据类型成员构成的序列。
利用宏,还可以完成更复杂的任务。
我们以前处理过的都是行式 Excel 文件,但是,就如前面讲结构化数据概念时,还会有许多存储结构化数据的 Excel 文件并不是行式的,比如这样:
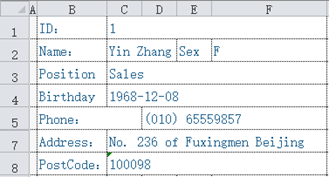
(这是前面例子中的部分,为简化问题只有一条记录)
假如有一批这样的文件,每个文件中存储了一个人的信息,现在我们希望把这些数据提取出来做成一个行式的表格。就用这个表格中的字段名:ID、Name、Sex、Postion、Birthday、Phone、Address、PostCode。
如果有几百个这样的文件,手工做显然会累死人的,我们用程序来做。
要做这件事,还需要用到两个 Excel 相关的函数 xlsopen、xlscell。
xlsopen 能打开一个 Excel 文件后形成一个 Excel 对象,xlscell 则可以从 Excel 对象中读出某个单元的内容。有了它们,我们就可以完成这个工作了。
A |
B |
C |
|
1 |
=create(ID,Name,Sex,Postion,Birthday,Phone,Address,PostCode) |
||
2 |
=directory@p("data/*.xlsx") |
||
3 |
for A2 |
=file(A3).xlsopen() |
|
4 |
=B3.xlscell("C1") |
=B3.xlscell("C2") |
|
5 |
=B3.xlscell("F2") |
=B3.xlscell("C3") |
|
6 |
=B3.xlscell("C4") |
=B3.xlscell("D5") |
|
7 |
=B3.xlscell("C7") |
=B3.xlscell("C8") |
|
8 |
=A1.insert(0,B4,C4,B5,C5,B6,C6,B7,C7) |
||
9 |
>file("all.xlsx").xlsexport@t(A1) |
||
代码逻辑不复杂,就不细解释了。
但是,写起来还是有点麻烦,而且如果表格样式和数据结构变了,要改动很多。
我们利用宏和循环函数来简化它。
A |
B |
C |
|
1 |
[ID,Name,Sex,Postion,Birthday,Phone,Address,PostCode] |
||
2 |
[C1,C2,F2,C3,C4,D5,C7,C8] |
||
3 |
=directory@p("data/*.xlsx") |
||
4 |
for A3 |
=file(A4).xlsopen() |
=B2.(B4.xlscell(~)) |
5 |
=@|C4 |
||
6 |
=create(${A1.concat@c()}).record(B5) |
||
7 |
>file("all.xlsx").xlsexport@t(A6) |
||
把字段和对应单元格做成两个序列,针对每个 Excel 文件取出数据和拼接就容易多了,代码不仅更短,而且更通用了。碰到新格式,只要修改前两行就行了。
反过来,我们还可能用一个行式表格的数据来生成多个这种自由格式 Excel。显然之件事手工做也是会累死人的。
我们还是用程序完成这件任务,需要增加一点知识:xlscell 函数还可以往 Excel 对象的某个单元格里填入数据,再学一个 xlswrite 函数,它可以将处理好的 Excel 对象写入文件。
A |
B |
C |
|
1 |
[ID,Name,Sex,Postion,Birthday,Phone,Address,PostCode] |
||
2 |
[C1,C2,F2,C3,C4,D5,C7,C8] |
||
3 |
=file("temp.xlsx").xlsopen() |
||
4 |
=file("all.xlsx").xlsimport@t() |
||
5 |
for A4 |
=A1.(A5.field(~)) |
>A2.(A3.xlscell(~;B5(#))) |
6 |
=file(A5.ID/".xlsx").xlswrite(A3) |
||
先做好一个这种格式的模板 Excel 文件,把它读成 Excel 对象,然后针对每条记录,把相关的值填入这个 Excel 对象,再写出到文件中,反复填入写出,就完事了。
在做人工智能任务时,常常会碰到填补缺失值的问题,即按一定规则将缺少的数据填上,比如常见是的按众数(其它未缺失值中出现次数最多的)或平均数(由其它未缺失值计算出)。
我们来尝试一下这个任务,假设 data.xlsx 存储了原始数据:
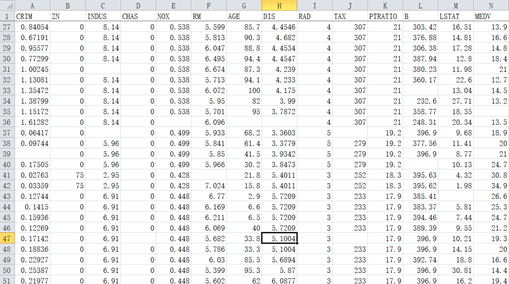
其中有空格部分表示有缺失的,我们的规则是:如果这一列是整数,则用众数方案填充;如果是浮点数,则用平均数方案填充。
A |
B |
C |
|
1 |
=file("data.xlsx").xlsimport@t() |
||
2 |
for A1.fname() |
=A1.field(A2) |
|
3 |
=B2.sum() |
=B2.sum(int(~)) |
|
4 |
=if(B3==C3,B2.mode(),B2.avg()) |
||
5 |
=B2.(if(~,~,B4)) |
>A1.field(A2,B5) |
|
6 |
>file("dataNew.xlsx").xlsexport@t(A1) |
||
将数据读成序表 A1,A2 循环每个字段,B2 中 field 函数将把序列某个字段的值全部取出形成序列,它有点像 A1.(x) 运算,但不同的是,这里 field 函数的参数是一个字符串,而 A1.(x) 中的 x 是个字段名,如果用 A1.(x) 形式写,则需要使用宏,写成 A1.(${A2})。
计算整列的和,与整数化后整列的和相比,如果相等,可以认为全是整数,那么执行众数方案,否则执行平均数方案,其中 mode 函数即可返回序列的众数。
然后在 B5 计算填上缺失值后的字段值序列,field 函数还可以将序列再填入字段,这里也可以用宏写成 A1.run(${A2}=B5(#)),但显然没有用 field 更清晰简单了。

