


机器学习分类
目前机器学习主要分为监督学习、无监督学习和强化学习
监督学习是指:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。在监督学习中训练数据既有特征又有标签(通常称为目标变量),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以预测出标签。
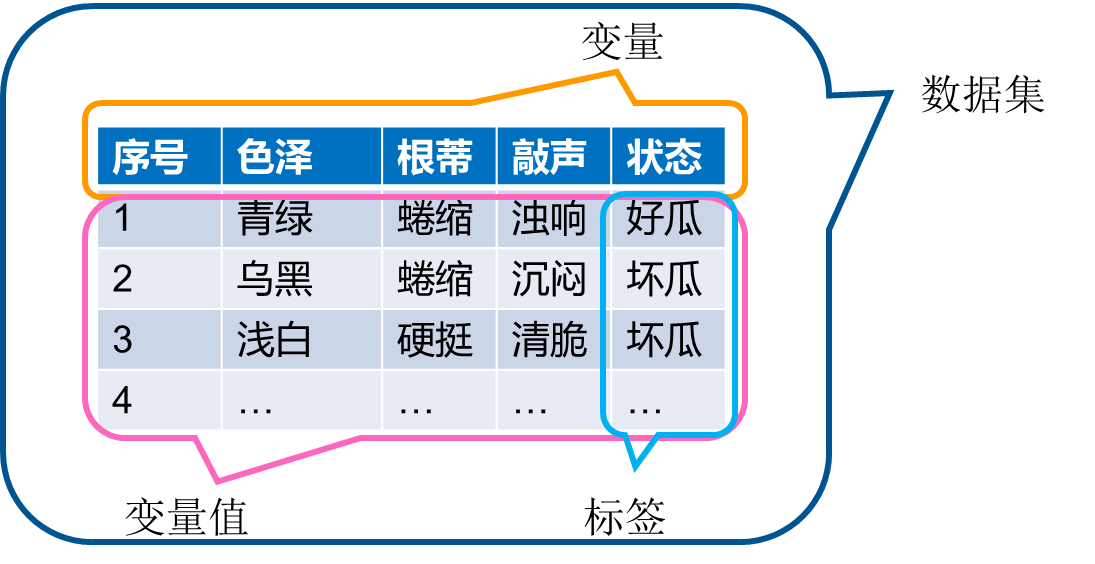
分类和回归是监督学习可以解决两大主要问题。在分类问题中我们要预测的目标是一个离散值,例如上图中预测西瓜的状态是好瓜还是坏瓜,就是一个分类问题。而在回归问题中要预测的目标是一个连续值,比如下图通过某地区房屋的一些特征来预测房屋的销售价格就是一个回归问题。

无监督学习:有一些问题,我们不知道答案,无监督学习就是按照他们的性质把他们 ** 自动地分成很多组,每组的问题是具有类似性质的(比如蔬菜会聚集在一组,水果会聚集在一组,主食…….)比起监督学习,无监督学习更像是自学,让机器学会自己做事情,是没有标签(目标变量)的。
简而言之:有监督学习和无监督学习的最大区别就是,有没有标签,即目标变量 Y
强化学习:所谓强化学习就是智能系统从环境到行为映射的学习,以使奖励信号 (强化信号) 函数值最大。强化学习是不需要标签的。简单来说就是放一只小白鼠在迷宫里面,目的是找到出口,如果它走出了正确的步子,就会给它奖励(糖),否则给出惩罚(点击),那么,当它走完所有的道路后,无论把它放到哪儿,它都能通过以往的学习找到通往出口最正确的道路。强化学习的典型案例就是 Alphago,它不会直接给你解决方案,你要通过试错去找到解决方案。
目前用到最多是监督学习和无监督学习,尤其是监督学习,因为应用场景多并且能给公司创造直接价值,使用最为广泛。

