


【程序设计】7.2 [字与时] 拆分合并
7.2 拆分合并
我们已经会用循环函数和 mid 把字符串拆成单个的字符序列,因为这种情况很常用,SPL 提供了 split 函数。s.split()就相当于 len(s).(mid(s,~,1))。
split 还有更多的拆串能力。
不过,在讲 split 之前,我们先学一个 clipboard 函数。
随便找个文本编辑程序,比如 Notepad,输入点字然后选中再按 Ctrl-C,就是我们熟悉的复制动作。现在到切换到集算器,新建网格在 A1 格里填上 =clipboard(),然后执行再看 A1 格的值。
刚才在 Notepad 里复制的文字到了这里,clipboard 函数可以把复制到系统剪贴板的文字取出来。
再在 A2 填入
>clipboard(“Hello,esProc”)
执行后,切换回 Notepad,再按 Ctrl-V 粘贴。看到了什么?
带有参数的 clipboard 函数会把作为参数的字符串复制进系统剪贴板,然后就可以在其它程序中粘贴了。
现在我们来利用这个 clipboard 函数帮助 Excel 干点事。
假定在 Excel 的某一列,比如就是 A 列吧,有一堆名字,比如前几行是这样:
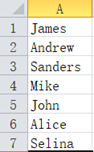
现在我们想知道这些名字中总共用了几次字母 e。
Excel 算这个并不太容易,我们用 SPL 来配合一下。
1) 在 Excel 中把这一列选中,按 Ctrl-C,复制到剪贴板里去。
2) 切换到集算器中,写这样的代码:
A |
|
1 |
=clipboard() |
2 |
=A1.split("\n") |
3 |
=A2.(~.split()) |
4 |
=A3.conj() |
5 |
=A4.count(lower(~)=="e" ) |
执行它,A5 就是我们要的结果了。
我们来看这个代码执行完后脚本中的每个格值,A1 是这样的:
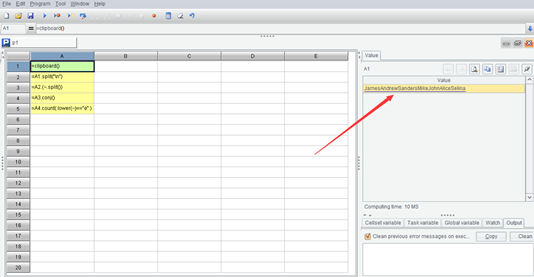
它是从剪贴板取出刚才在 Excel 复制的内容,看起来是把 Excel 那一列文字挤到一起了。再看 A2:
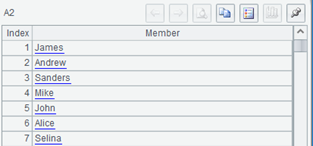
这是个序列,每个成员正好是 Excel 那一列中的每一行文字,这是怎么做到的?
其实,Excel 复制出来的东西是一个由这些文字构成的大字符串,两行之间用回车符分隔。而回车符是个不可显示字符,在集算器界面中看不到,于是就看起来就像是把这些行的文字都挤到一起了。A1.split(“\n”) 的意思就是用回车符作为分隔符把这个大串拆开成序列,于是就回到每一个成员正好对应 Excel 中每一行的情形了。
这里的 "\n" 就是回车符,字符串常数中的反斜杠 \ 称为转义字符,它的作用是帮助我们写出来一些不方便写出来的字符。比如回车符就用 \n 表示,制表符用 \t 表示,这些都是不可显示字符,但也有编码,也是个字符。\n 在字符串里只是一个字符,虽然在引号中书写出来是 \ 和 n 两个字符,\t 也是类似的。
因为 \ 被当成转义字符了,如果我们想真地需要在字符串常数中有一个 \,那也就转义,写成两个,即 "a\\b" 的实际内容是 a\b,长度为 3;还有,双引号被我们用来当作字符串的分界符号了,但仍然有可能有字符串里含有双引号,这时候也要用转义字符来书写,"a\"b"的实际内容是 a"b,长度为 3。
后面几句就简单了,A3 是个循环函数,它的内部 ~.split() 会把每个成员的字符串再拆成单个字符的序列,所以 A3 是个二层序列:
[[“J”,“a”,“m”,“e”,“s”],[“A”,“n”,“d”,“r”,“e”,“w”],…]
conj()函数我们在讲递归时碰到过,它的作用是把多层序列的作为成员的序列都拼接起来,返回这些成员之间用 | 运算的结果,所以 A4 中的 A3.conj() 将得到:
[“J”,“a”,“m”,“e”,“s”,“A”,“n”,“d”,“r”,“e”,“w”,…]
lower 函数将字符变成小写,现在可以和字符串 "e" 比较了,再用 count 计算就可以了。
写成现在这样是为了把步骤拆开方便解释代码,其实这些运算都可以连着写:
A |
|
1 |
=clipboard() |
2 |
=A1.split@n().conj() |
3 |
=A2.count(lower(~)=="e" ) |
s.split@n(x) 就是 s.split(“\n”).(~.split(x)),因为按回车符拆分后再拆开的情况很常见,SPL 就为 split 函数加了 @n 选项。
再看一个例子。
Excel 里某一列存了一批 Email 地址。我们知道,Email 地址都是 x@y 的格式。我们希望把这些 Email 地址重新排序,同一个企业的邮箱能排到一起,即希望按先 y 后 x 的次序排列,比如要把 abc@google.com 和 xyz@google.com 排到一起,而不是把 abc@google.com 和 abc@apple.com 排到一起,但直接用 Excel 的排序就会出后面这种情况了。
还是用剪贴板,在 Excel 中把这列数据复制出来,然后切换到集算器写代码:
A |
|
1 |
=clipboard() |
2 |
=A1.split@n("@") |
3 |
=A2.sort([~(2),~(1)]) |
4 |
=A3.concat@n("@") |
5 |
>clipboard(A4) |
执行,然后切换回 Excel 在那一列用 Ctrl-V 粘贴,已经按我们的希望排好了。
A1 我们已经理解了,A2 里的 split@n 还是同样的意思,先按回车符拆分成字符串的序列,再把每个成员用分隔符 "@" 拆分,一个 Email 地址中有且只会有一个 @,所以每个串将被拆成两个成员的序列,分别是 @前面和后面的部分。然后 sort 函数排序时,把序列成员反过来写,这样按序列比较规则会先比 @后面部分,再比 @前面部分,也就是我们希望的次序了。
A4 中的 concat 是 split 相反的函数,split 负责拆,concat 负责合,@n 选项表示针对二层序列做 concat,每个成员恢复成原先的 Email 地址串后拼成用回车分隔的大串,但现在次序已经合理了。再用 clipboard 函数复制到剪贴板中,Excel 那边只要粘贴就 OK 了。
A4 还可以直接写成 A3.sort(~(2),~(1)),sort 函数也支持多参数形式,意思就是先比前面参数再比后面参数。对于单值构成的序列,多参数的 sort 意义不大,但对于二层序列就会方便一些,将来学习结构化数据后,多参数 sort 会更常见。
现在我们处理的 Excel 都是单列的数据,那么多列的行不行呢?
当然也没有问题。
比如这样的 Excel,我们希望将每一行的数据从小到大排序。
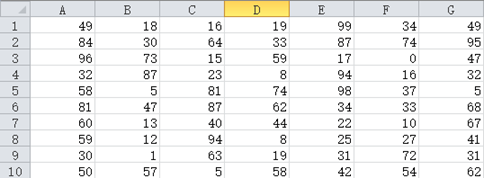
Excel 的排序通常是按行进行的,在列方向排序就很困难了。借助 SPL 就很容易实现,在 Excel 中把这一片选中复制,然后切换到集算器执行这样的代码:
A |
|
1 |
=clipboard() |
2 |
=A1.split@n("\t") |
3 |
=A2.(~.sort()) |
4 |
=A3.concat@n("\t") |
5 |
>clipboard(A4) |
然后再粘贴回去就行了。
Excel 复制出来的成片数据,被 clipboard 函数接收后是一个大字符串,每行之间用回车符即 \n 分隔,每行内的列则用制表符 \t 分隔。所以在 A2 中用 A1.split@n(“\t”) 就可以把这个大串拆成二层序列,其内层成员正好是 Excel 每个单元格的数据;然后在 A3 中对每一行排序,在 A4 中再拼回成这样的 \n 和 \t 分隔的串,粘贴进去 Excel 就完事了。
仔细看 Excel 里的结果,好象有点不对,它把 42 排到了 5 的前面,大小搞错了?
其实没错,因为 split 函数拆出来的东西还是字符串,而作为字符串,"42" 就是比 "5" 小。
那么怎么才能按数值来比较呢?需要转换一下,把 A3 改成:
=A2.(~.sort(number(~)))
与 string()对应,number() 可以把字符串参数转换成数值类型,然后就可以按数值规则来比较和排序了。现在再看,没有问题了。
以前的操作系统下有个叫 grep 的命令,能够在很多文本文件中找出含有某个字符串的文件及以所在的行号。这个挺有用的命令,后来不知道为啥被 Windows 取消了,我们现在来自己实现一下。
假定要找的字符串在 A1 中,我们来指定路径下的所有文本文件:
A |
B |
C |
D |
|
1 |
abc |
=directory@p("D:/data/*.txt") |
||
2 |
for B1 |
=file(A2).read@n() |
=filename(A2) |
|
3 |
for B2 |
if pos(B3,A1) |
>output(D2/"\t"/#B3/"\t"/B3) |
|
我们要再学习几个新函数。
A1 中 directory 函数将返回指定路径下(最好是用绝对路径,不然可能因为集算器的启动路径不确定而找不到文件)所有的.txt 文件名,这些文件名将返回成一个字符串序列,@p 表示返回的文件名也是全路径的。A2 循环这个序列,B2 读出每个文件,file 函数用文件名产生一个文件对象,read@n 函数将文本文件又读成字符串的序列,每行一个成员。filename 将全路径文件名中路径的部分剥离。
B3:D3 就容易看懂了,循环每一行文本,找到 A1 就输出文件名、行号及这一行的内容。
这里我们要假定文件都不大,可以一次读入。如果文件很大,就需要使用后面才讲到的游标技术了。
数一数一批文章中有多少单词,也是一个常见的练习题。学会了读文件后,我们也可以练习一下:
A |
|
1 |
=directory@p("D:/book/*.txt").sum(file(~).read().words().len()) |
没有选项的 read 函数将把整个文本文件读一个大字符串,而 words 函数将把这个大串中的单词都拆出来构成序列,那剩下只要数一下长度再加起来就行了, 一行就够了。
我们再做一个平常可能用得着的任务:把一批 Excel 文件合并成一个大的。
经常我们可能会收集到各个时期或者各个部门的 Excel 文件,这个 Excel 的格式都一样。要把这些文件合并成一个完整的文件方便进一步统计。但手工复制粘贴很麻烦,假如有几十上百个文件,那就相当劳累了。这种事情正好让程序来做。
我们假定要合并的 Excel 都是行式的,即第一行是标题,之后每一行都是数据,比如这样的:
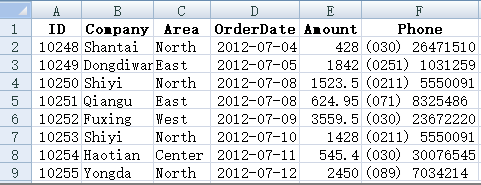
这也是很常见的的 Excel 格式。
还要增加一个要求,把原来分开时的 Excel 文件名拼到合并后的 Excel 的最后一列,这样能区分出数据是从哪个文件来的。
A |
B |
|
1 |
=directory@p("D:/data/*.xlsx") |
|
2 |
for A1 |
=file(A2).xlsimport@w() |
3 |
=filename@n(A2) |
|
4 |
=B2.to(2,).(~|B3) |
|
5 |
=@|B4 |
|
6 |
=if(#A2==1,B2(1)|"File",@) |
|
7 |
=file("D:/all.xlsx").xlsexport@w([B6]|B5) |
|
B3 的 filename@n 会拆解出文件名中去除扩展名的部分,自己用串拆分也能做出来。B2 的 xlsimport@w() 将把一个 Excel 文件读成二层序列,Excel 的每一行对应其一个成员,而每一行中的每一列则对应其成员的成员。B4 中去除第一行的标题,再将文件名拼到每一行的最后。B5 把这些数据合并起来,而 B6 要再保留一个标题,同样也要多拼一列。
最后 A7 用 xlsexport@w()把汇总后的二层序列 [B6]|B5 写成一个新的 Excel 文件(写文件时最好也用绝对路径)。
无 @w 选项的 xlsimport() 其实能把 Excel 文件读成更方便的数据类型,完成这个任务的代码也会更简单,但要在讲过结构化数据之后再来介绍了。
随着学习的深入,我们将逐步进入可以实战的程度,处理文件数据是很常见的任务。这一节的例子中,我们都使用了绝对路径来定位文件。这里简单介绍一下集算器对于使用相对路径时的文件寻找规则(绝对路径就直接找到了):
如果在环境中设置了主路径(第 6 章第 3 节),那么集算器将从这个主路径开始找;如果主路径填成空的,则从当前正在使用的脚本文件所在路径去寻找,当前脚本可能刚新建还未保存的,这时还没有所在路径,就无法确定会哪里找了,很可能发生找不到的现象。所以要么设置主路径,要么当前脚本都被保存而有所在路径。
和主路径同时设置的那个寻址路径是用来寻找被调用脚本的,和数据文件无关。把数据文件放到寻址路径中不会自动被找到。
自己做点实验看看,也就容易理清楚了。
我们后面再举例时,将使用简单的相对路径,请读者根据上面的介绍自行调整合适的系统配置以及代码中的路径。

