


BIRT 中文本与 JSON 关联怎么做
关键词导读:文本与JSON关联 BIRT数据源
BIRT对于两个数据源的联合提供了Joint DataSet的解决方案,它具有图形化的操作界面,可以完成简单的内外关联,但功能非常局限(几乎没有二次计算的能力,Join 后再计算只限于简单查询和固定查询,难以实现自由的组合查询和变量查询,更不能进行分组汇总再过滤这类多步骤计算)。
BIRT虽然支持CSV/TXT等文件作为数据源,但不能构建JSON数据源,一些开源社区提供了解析JSON数据源插件,几乎所有插件都非常底层,使用起来很不方便。
从能力上讲,只有自定义数据源可以完整的解决这个问题,但BIRT JAVA bean data source这种硬编码方式比较复杂,工作量巨大。
比如要处理这么个场景:sales.txt是tab分割的结构化文本,city.json是非结构化的JSON串,sales.txt的第2列和city.json的部分文本存在外键关系,需要将两个文件连接为二维表。示意图如下:
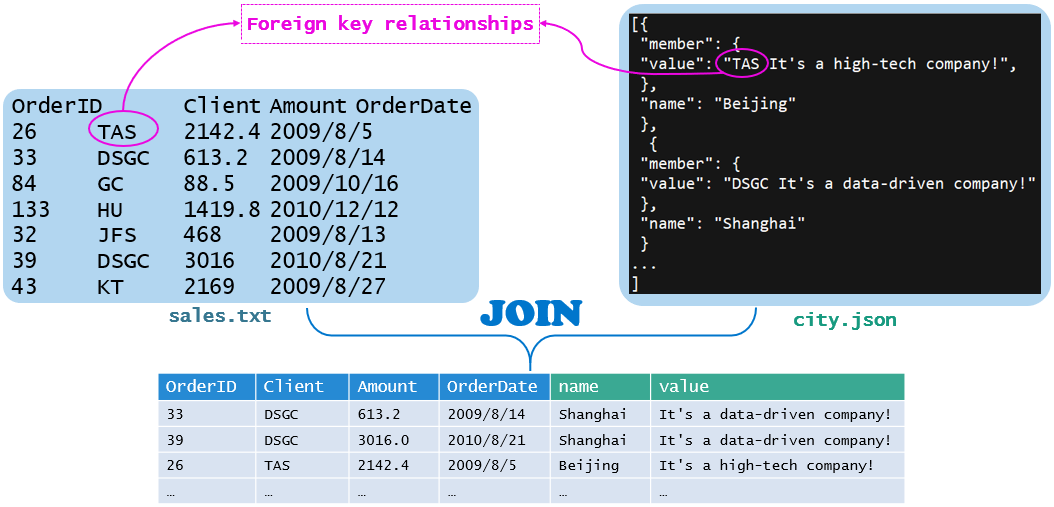
建议使用集算器,它是独立的数据计算引擎,拥有不依赖于数据库的计算能力,可以从多种多样的文件获取数据并混合关联运算,事实上,可以把集算器看作是语法更简单的BIRT JAVA bean data source。比如实现上面的问题,集算器脚本只需5行:
|
|
A |
| 1 |
=json(file("/workspace/city.json").read()) |
| 2 |
=A1.new(name,#1.(#1):desc,(firstblank=pos(desc," "),left(desc,firstblank-1)):key,right(desc,len(desc)-firstblank):value) |
| 3 |
=file("/workspace/sales.txt").import@t() |
| 4 |
=join(A3:sales,#2;A2:city,key) |
| 5 |
=A4.new(sales.OrderID,sales.Client,sales.Amount,sales.OrderDate,city.name,city.value) |
关联之后还能更方便地实施计算,比如:统计每个城市的销售额;只需在此基础上增加1行:=A5.groups(name;sum(Amount):amount)
其实还有很多类似的问题做起来不太方便,比如:计算文本、Excel,甚至关联计算、入库等需求,但用集算器SPL却很简单,感兴趣可以参考:结构化文本计算示例(二)、JSON数据计算与入库
集算器提供了JDBC驱动,可以很方便的与BIRT等报表工具集成,BIRT调用SPL脚本有使用和获得它的方法。
关于集算器安装使用、获得免费授权和相关技术资料,可以参见如何使用集算器。

